
RecSys Challenge 2020 備忘録

はじめに
3月初旬から開催されていたRecSys Challenge 2020が、6/15に提出締切が終了したので、その取り組みについてまとめました (現在は6/22の最終結果のアナウンス待ちです、筆者はPublicは22th -> Private 8th)
この記事はソリューションの話は少なめでコンペの取り組みに関する備忘録色が強めです。
コンペについて
RecSys challengeは、推薦システムに関するトップカンファレンスであるACM Recommender Systems conference (RecSys)で毎年開催されているデータ分析コンペティションです。毎年、推薦に関する異なるタスクが用意されており、今回で11回目となる歴史のあるコンペです。
- 過去の大会 https://recsys.acm.org/challenges/
今回のRecSys Challenge 2020は、Twitter社がデータ提供をしており、ツイートへのエンゲージメントを予測するタスクです。以降、簡単にタスクやデータを紹介しますがデータを提供しているTwitter社が公開している論文[1]が詳しいです。
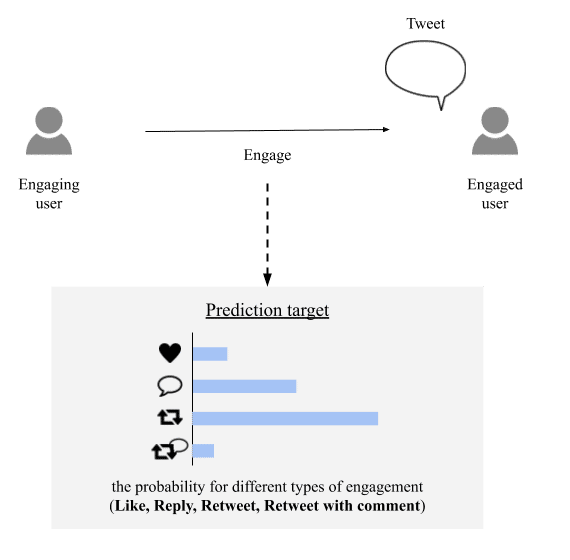
上図のようにツイートに対するユーザの4種類のエンゲージメント (いいね、返信、リツイート、コメント付きリツイート) の確率値を予測します。テキストなどのツイートに含まれる情報やユーザ (投稿者側、読者側)の情報を用いて、これを予測します。
評価指標
評価指標は、4種類のエンゲージメント予測それぞれに対するPRAUC (Area Under the Precision-Recall Curve)およびRCE (Relative Cross Entropy)です。コンペのリーダーボードは4種類のエンゲージメントのPRAUCとRCEの平均値のLB上での順位の和として算出されます。※ こちら以前誤って記載していました
データ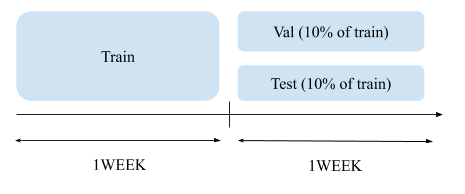
- 2週間で発生した約200millionのエンゲージメント
- この内の約半数(100million)は公開されているフォローグラフを基にランダムに負例としてサンプリングされている
- Train: 160million, Val: 20million, Test: 20million
今回のデータセットの特殊な点として、プライバシー保護の観点からデータセットが毎週更新されるという点があります。サービス上でツイートやユーザがパブリックでなくなったり削除されたりした場合に、GDPRに準拠してデータセットから取り除かれます。その結果、時間の経過とともにデータセットのサイズが小さくなります。(コンペ期間中に、trainのサンプル数は1.6million -> 1.2millionくらいになりました)
特徴量
データセットに含まれるツイート、ユーザやエンゲージメントに関する特徴量は以下の表の通りです。(論文[1]のTable. 1)

コンペ期間中の取り組み
手法の詳細やコードも最終結果確定後、別途何らかの形で残そうと思っていますが、メインのシングルモデルは簡単には以下の通りです。(振り返ってみると、私は凡な特徴量・モデリングしか採用できませんでした。上位解法が超気になります。)
Validation
7日間のデータの前半6日を学習データ、残り1日を検証データ
特徴量
- Dense features, 数値特徴量
- フォロワー数系、ツイートの長さ系、timestamp系、など
- Sparse features, one-hotのカテゴリ特徴量
- 提供されたものを中心に基本的なもの
- social graph系, フォローグラフのユーザのクラスタリング、など
- テキスト系, Bert特徴量を使ってツイートをクラスタリング、など
- Varlen sparse features, multi-hotのカテゴリ特徴量
- ハッシュタグ、ドメイン、リンク
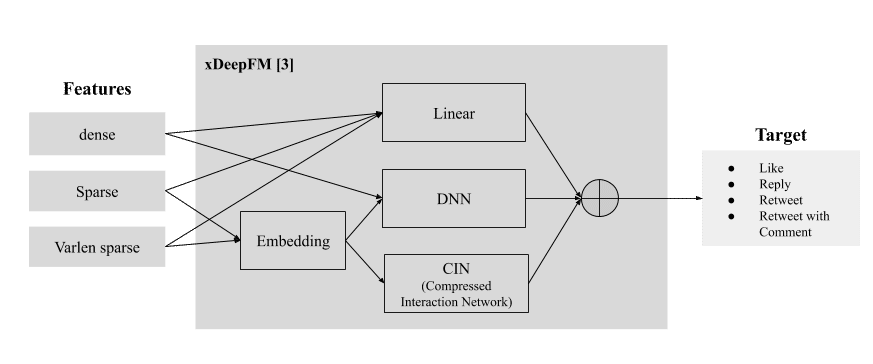
モデル
- xDeepFM [3]
- optimizer: Adam
- loss: BCE
LBの変遷

上図はコンペ期間中の私のLBの変遷(RCEのみ)です。下部分は期間中の作業をざっくり分けています。こんなに明確には分かれてないですが、ざっくりこんな感じです。これは弱者の作業ログなので反面教師にして下さい。
1. コンペ参加チャレンジ期
最初の関門として、Twitter API承認(データをDLするために必要)&データDLチャレンジがあります。当時、自宅回線が地獄だったのでトレーニングデータをダウンロードするのに5日くらい掛かって馬鹿みたいでした。
最初は、10分の1くらいのデータを使って提供されている特徴量を観察したり、提出できるかどうかなどシステムの確認などをしてました。
2. ベースモデル作る期
推薦関連やCTR系の手法を調査して、DeepFM [2]が良く使われてそうだったので動かしてみたらそれっぽい精度がでたのでこれで良いのかな?という感じでベースモデルができました。その後、4月末くらいに公開されたTwitter社の論文[1]で代表的な手法として調査したあたりが紹介されていたので安心しました。この期間は幸福度高かったです。(FF7 REMAKE楽しい期でもあった)
3. 特徴量増やしたり、減らしたり期
1. 2.の期間で作ってたり、考えてた特徴量を使って実験をしました。私の環境では、特徴量算出の計算コストが大変 + 毎週データセットが更新される という状況に振り回されて効率的に実験を進めることができなかったのが良くなかったです。コードが適当過ぎたら、メモリ乗らない or 計算終わらない なので、自分の実装能力を嘆きながら過ごしてました。
その他イベント
- ネット回線を改善
- PC増強 by 特別定額給付金 (メモリ 64GB -> 256GB)
4. ハイパーパラメータ試す期
ユニークユーザ数が多くて、Embeddingの次元数とか増やしたらメモリが溢れるので、低頻出ユーザは使わないとか、その辺りの勘所が全く分からなかったので、それっぽい値を探すとかをしてました。データ量が大きく、何も考えずにやると実験1回の施行のコストも大きくなってしまうのですが、何も考えずに進めてしまいました。
5. 色々試す期
この期間はいくつかの実験をしたが期待した精度向上がありませんでした。特に、論文[1]の3章の「KEY CHALLENGES」で指摘されている「Sampling」「Label Imbalance」「Social Graph」「Language」「Data Shift」あたりを中心に努めましたが何も得られませんでした。理論の理解力とエンジニアリング能力の未熟さで実験が正しくやりきれてない気がしていて、上位解法から最も学びたい部分です。また、別件の忙しさも相まって残り時間的な余裕がなくなり、細かい違和感を感じてもデータ量も大きいし、実装・実験する体力が無くなり、 思考停止しました。
6. アンサンブル期
今回はMLflowで実験管理を使ってたので、その中でモデルのパラメータなどを踏まえてできるだけ多様なモデルを採用してスタッキング等で最後少しだけ足掻きました。
反省ばっかりなのですが、一番大きな反省点としては、3. 4. の期間に手当たり次第に実験をしたのですが、MLflowで実験管理をしていたものの、1つ1つの特徴量やパラメータの影響などの検証が雑になり、5. 6.の期間に何が有効なのかが不明確な状態で雰囲気で実験を繰り返してて進まなくなった気がします。 また、5. の期間にやろうとしていたような重要そうな実験はもう少し初期の時間的な余裕があるときにやるほうが筋が良かったのかなとも思います。
コンペの感想
予測対象が身近なのでタスクがイメージしやすく、データの種類も量も大きくて、やり込み要素もあり、面白かったです。
推薦系のタスクのDeep実装は初めてで、本当にこれで良いのか?みたいな気持ちの連発で全然わかりませんでしたが、何も分からないなりに3ヶ月くらいもがいてたので、上位解法を見たら何か分かると信じてます。
ディスカッションが活発でないタイプのコンペ
このコンペでは、Forumはありますが、内容はほとんどシステムやルールに関する主催者への質疑くらいであり、手法に関する議論はほとんどおこなわれておりませんでした。個人的には、必然的に自分だけでモデルを実装したり、アイデアを考えられるので公開されている情報に踊らされることなく楽しく取り組めた気がしました。(Kaggleをやるときも、目の前に情報が多すぎると私はそれに溺れることが多いので、一定見ないようにするというのも大事と感じました)
ただ、上位解法は最終的にRecSys2020のWorkshopにて共有されることは保証されているので、安心して取り組めました。(今年は学会がオンライン開催なので渡航費無しで比較的低コストで参加できるのでチャンス)
rapids.aiが強い

上図はPublic LBの1st(rapids.ai, 緑), 2nd(Layer 6 AI, オレンジ), 22th(私, 青)。
最終的なPublic LB1位のrapids.aiチームは、終始強かったのですが、特に5月末ごろに上図のようにスコアが急上昇し、「!?」って感じでした。シャーマンキングでハオの巫力が125万と知ったときのインパクトでした。スコア以外にどう強いのかは分からないので、ソリューションがとても気になります。

最後に
結果は微妙でしたが、個人的には超楽しかったです。推薦タスクはユーザ側としてタスクをイメージしやすくて面白かったので、できれば来年も参加したいと思いました。
参考文献
参考資料として、コンペ中に参考にした(しようとした)論文や記事をまとめました。実装能力、理解力、時間などの観点で実装や検証までたどり着いていないものが多いですが、とても助けられました。別のコンペで役立てたいです。
主催論文
- [1] Luca Belli et al., "Privacy-Preserving Recommender Systems Challenge on Twitter's Home Timeline", https://arxiv.org/abs/2004.13715, 2020.
CTR系
- Paperswithcode (CTR page), https://paperswithcode.com/task/click-through-rate-prediction
- DeepCTR (tool), https://github.com/shenweichen/DeepCTR , https://github.com/shenweichen/DeepCTR-Torch
論文
- [2] Huifeng Guo et al., "DeepFM: a factorization-machine based neural network for CTR prediction", IJICAI 2017.
- [3] Jianxun Lian et al., "xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems" KDD2018.
- Weiping Song et al., "AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks", CIKM 2019.
- Wei Deng et al. "A Sparse Deep Factorization Machine for Efficient CTR prediction", https://arxiv.org/abs/2002.06987.
- Guorui Zhou et al., "Deep Interest Network for Click-Through Rate Prediction", KDD2018.
- Tongwen Huang et al., "FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction", Recsys 2019.
- Maxim Naumov et al., "Deep Learning Recommendation Model for Personalization and Recommendation Systems", https://arxiv.org/abs/1906.00091.
- Chong Chen et al., "Efficient Non-Sampling Factorization Machines for Optimal Context-Aware Recommendation", WWW 2020.
- Junwei Pan et al., "Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising", WWW 2018.
- Sofia Ira Ktena et al., "Addressing delayed feedback for continuous training with neural networks in CTR prediction", Recsys 2019.
- Lin Guo et al., "Visualizing and Understanding Deep Neural Networks in CTR Prediction", SIGIR Workshop on eCommerce 2018.
記事
- DeepなFactorization Machinesの最新動向(2018) , https://data.gunosy.io/entry/deep-factorization-machines-2018
- ぐぐりらさん論文紹介, https://www.smartbowwow.com/
- マイクロアドにおけるCTR予測への取り組み, https://speakerdeck.com/kishimotobanana/maikuroadoniokeructryu-ce-hefalsequ-rizu-mi
NLP系
論文
- Bhuwan Dhingra et al., "Tweet2Vec: Character-Based Distributed Representations for Social Media", ACL2016.
- Manoel Horta Ribeiro et al., "Characterizing and detecting hateful users on twitter", AAAI2018.
- SEDTWik: Segmentation-based Event Detection from Tweets Using Wikipedia, NAACL2019, https://www.aclweb.org/anthology/N19-3011/
- Svitlana Vakulenko et al., "Character-based Neural Embeddings for Tweet Clustering" SocialNLP 2017.
- BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs, SEMEVAL 2017, https://arxiv.org/pdf/1704.06125v1.pdf
- Dat Quoc Nguyen et al., "BERTweet: A pre-trained language model for English Tweets", https://github.com/VinAIResearch/BERTweet.
記事
- Analyzing Multilingual Data, https://www.kaggle.com/rtatman/analyzing-multilingual-data
- BERTの精度を向上させる手法10選 , https://qiita.com/YuiKasuga/items/343309257da1798c1b63
- Text Classification: All Tips and Tricks from 5 Kaggle Competitions , https://neptune.ai/blog/text-classification-tips-and-tricks-kaggle-competitions
Graph系
- networkX, https://networkx.github.io/documentation/stable/tutorial.html
- python-louvain, https://github.com/taynaud/python-louvain
- gae, Thomas N. Kipf et al., "Variational Graph Auto-Encoders", NeurIPS Bayesian Deep Learning Workshop 2016, https://github.com/tkipf/gae
- node2vec, Aditya Grover et al., "node2vec: Scalable Feature Learning for Networks", KDD 2016,https://github.com/aditya-grover/node2vec
- Yozen Liu et al., "Characterizing and Forecasting User Engagement with In-App Action Graph", KDD 2019.
Pytorch系
- モデル並列関連
- https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
- https://blog.paperspace.com/pytorch-memory-multi-gpu-debugging/
- apex, https://github.com/NVIDIA/apex
- PyTorchのDataLoaderが遅い , https://qiita.com/bauer/items/98cb096e9fe585e7a926
この記事が気に入ったらサポートをしてみませんか?