
初心者がPythonでホテルデータのロジスティック回帰をやってみた

この記事の概要
この記事はAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。今回Aidemyにチャレンジしたものの中々時間を割くことができませんでしたが、短い時間でも私と同じようにPythonデータ分析にチャレンジされる方の参考になれば幸いです。
自己紹介
ITベンチャーの企画職の30歳。元々プログラミングには興味があり業務でデータ分析をする機会が増える中でもっと専門的なことを知りたいと思い、Aidemyを受講
私の環境とレベルについて
Python3
Macbook Pro
Chrome
Google Colaboratory
プログラミング初心者で数学もあまり得意ではないです
作成プログラム
テーマ
私自身が旅行業界に携わっていることもあり、ホテルの需要予測ができるものを作成したいと思います
使用するデータセットですが、Kaggleのデータセットからホテルの需要・予測データがありましたのでこちらを使用したいと思います。
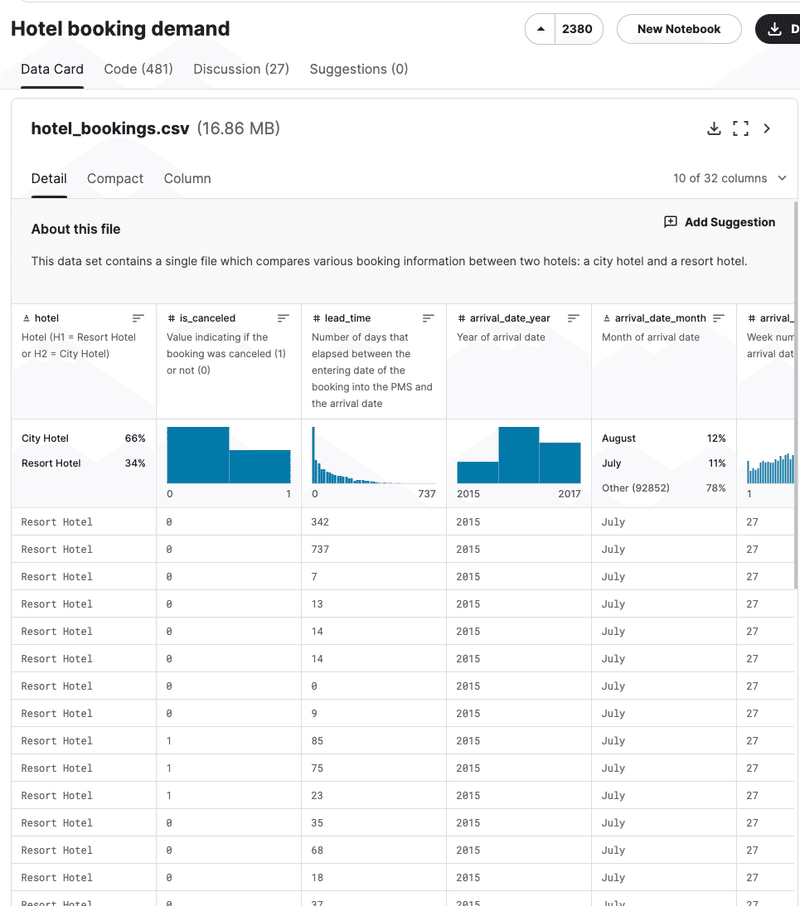
リゾートホテルとシティホテルのキャンセル有無データをリードタイム(何日前の予約なのか)、と人数情報をもとにしてホテルタイプ別の予測モデルを作成し、キャンセルされる可能性が高い予約を検知できるものを目指します
1. 必要なモジュールを記載
まずは必要なモジュールを読み込みます。今回はロジスティック回帰の手法を用います
# 必要なモジュールの読み込み
import numpy as np
from numpy import nan as NA
import scipy.stats
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score2. データの読み込み
ホテルブッキングデータをGoogle Colaboratoryにアップロードし、Pandasでデータを読み込みます
https://www.kaggle.com/datasets/jessemostipak/hotel-booking-demand/data
# データの読み込み
hotel_data = pd.read_csv("/content/hotel_bookings.csv")3. データの前処理
ホテルブッキングデータの人数情報は大人、子供、幼児で分かれているため、総人数のカラムを新たに作成します。
また、ホテルカテゴリが「リゾートホテル」「シティホテル」で分かれているため、予めデータを2分割しておき、それぞれで予測モデルを作成できるようにしていきます。
# データにカラム作成(大人+子供=総人数)
hotel_data['totalnum'] = hotel_data['adults'] + hotel_data['children'] + hotel_data['babies']
hotel_data['totalnum'] = hotel_data['totalnum'] .fillna(0)
hotel_data['lead_time'] = hotel_data['lead_time'] .fillna(0)
hotel_data['is_canceled'] = hotel_data['is_canceled'] .fillna(0)
# ResortHotelとCityHotelでデータ分け
R_data = hotel_data[hotel_data['hotel']=='Resort Hotel']
C_data = hotel_data[hotel_data['hotel']=='City Hotel']4. データ分割
リゾートホテルとシティホテルそれぞれでデータを訓練用と検証用に分けます
# ResortHotelデータを訓練/検証で分割(デフォルトの75%:25%)
R_train_X, R_test_X, R_train_y, R_test_y = train_test_split(R_data[['lead_time', 'totalnum']], R_data['is_canceled'], random_state=42)
# CityHotelデータを訓練/検証で分割(デフォルトの75%:25%)
C_train_X, C_test_X, C_train_y, C_test_y = train_test_split(C_data[['lead_time', 'totalnum']], C_data['is_canceled'], random_state=42)5. モデルの学習
ロジスティック回帰モデルを構築し、先ほど分割した訓練用データを使って学習させていきます
# ロジスティック回帰モデルを構築する
R_model_LR = LogisticRegression()
C_model_LR = LogisticRegression()
# R_train_XとR_train_y、C_train_XとC_train_yを使ってモデルに学習
R_model_LR.fit(R_train_X, R_train_y)
C_model_LR.fit(C_train_X, C_train_y)
6. モデルによる予測
作成したモデルに対してテストデータを当て予測結果を出します
# R_test_X、C_test_Xに対するモデルの分類予測結果
R_LR_y_pred = R_model_LR.predict(R_test_X)
print(R_LR_y_pred)
C_LR_y_pred = C_model_LR.predict(C_test_X)
print(C_LR_y_pred)
7. 精度の確認
精度、適合率、再現率、F1スコアを計算します。
# Resortホテルモデル精度評価
R_conf_matrix = confusion_matrix(R_test_y, R_LR_y_pred)
print("R_Confusion Matrix:")
print(R_conf_matrix)
R_accuracy = accuracy_score(R_test_y, R_LR_y_pred)
R_precision = precision_score(R_test_y, R_LR_y_pred)
R_recall = recall_score(R_test_y, R_LR_y_pred)
R_f1 = f1_score(R_test_y, R_LR_y_pred)
print("R_Accuracy:", R_accuracy)
print("R_Precision:", R_precision)
print("R_Recall:", R_recall)
print("R_F1 Score:", R_f1)
# Cityホテルモデル精度評価
C_conf_matrix = confusion_matrix(C_test_y, C_LR_y_pred)
print("C_Confusion Matrix:")
print(C_conf_matrix)
C_accuracy = accuracy_score(C_test_y, C_LR_y_pred)
C_precision = precision_score(C_test_y, C_LR_y_pred)
C_recall = recall_score(C_test_y, C_LR_y_pred)
C_f1 = f1_score(C_test_y, C_LR_y_pred)
print("C_Accuracy:", C_accuracy)
print("C_Precision:", C_precision)
print("C_Recall:", C_recall)
print("C_F1 Score:", C_f1)
8-1. リゾートホテルモデルのチューニング
ランダムサーチの手法でベストなパラメーターを探ります
# ランダムサーチ:ハイパーパラメーターの値の候補を設定
R_model_param_set_random = {LogisticRegression(): {
"C": scipy.stats.uniform(0.00001, 1000),
"random_state": scipy.stats.randint(0, 100)
}}
# スコア比較用に変数を用意
R_max_score = 0
R_best_model = None
R_best_param = None
#ランダムサーチ
for R_model_LR, param in R_model_param_set_random.items():
R_clf = RandomizedSearchCV(R_model_LR, param)
R_clf.fit(R_train_X, R_train_y)
R_LR_y_pred = R_clf.predict(R_test_X)
R_score = f1_score(R_test_y, R_LR_y_pred, average="micro")
# 最高評価更新時にモデルやパラメーターも更新
if R_max_score < R_score:
R_max_score = R_score
R_best_model = R_model_LR.__class__.__name__
R_best_param = R_clf.best_params_
print("学習モデル:{},\nパラメーター:{}".format(R_best_model, R_best_param))
# 最も成績のいいスコアを出力してください。
print("ベストスコア:",R_max_score)
# 最適なハイパーパラメータを使用して、モデルを再度トレーニングします。
R_best_model = LogisticRegression(C=R_best_param['C'])
R_best_model.fit(R_train_X, R_train_y)
# 最適化されたモデルを使用してテストデータで評価します。
R_LR_y_pred_tuned = R_best_model.predict(R_test_X)
# 精度を計算
R_accuracy_tuned = accuracy_score(R_test_y, R_LR_y_pred_tuned)
print("R_Tuned Model Accuracy:", R_accuracy_tuned)
8-2. シティホテルモデルのチューニング
こちらも同様にランダムサーチの手法でベストなパラメーターを探ります
# ランダムサーチ:ハイパーパラメーターの値の候補を設定
C_model_param_set_random = {LogisticRegression(): {
"C": scipy.stats.uniform(0.00001, 1000),
"random_state": scipy.stats.randint(0, 100)
}}
# スコア比較用に変数を用意
C_max_score = 0
C_best_model = None
C_best_param = None
#ランダムサーチ
for C_model_LR, param in C_model_param_set_random.items():
C_clf = RandomizedSearchCV(C_model_LR, param)
C_clf.fit(C_train_X, C_train_y)
C_LR_y_pred = C_clf.predict(C_test_X)
C_score = f1_score(C_test_y, C_LR_y_pred, average="micro")
# 最高評価更新時にモデルやパラメーターも更新
if C_max_score < C_score:
C_max_score = C_score
C_best_model = C_model_LR.__class__.__name__
C_best_param = C_clf.best_params_
print("学習モデル:{},\nパラメーター:{}".format(C_best_model, C_best_param))
# 最も成績のいいスコアを出力してください。
print("ベストスコア:",C_max_score)
# 最適なハイパーパラメータを使用して、モデルを再度トレーニングします。
C_best_model = LogisticRegression(C=C_best_param['C'])
C_best_model.fit(C_train_X, C_train_y)
# 最適化されたモデルを使用してテストデータで評価します。
C_LR_y_pred_tuned = C_best_model.predict(C_test_X)
# 精度を計算
C_accuracy_tuned = accuracy_score(C_test_y, C_LR_y_pred_tuned)
print("C_Tuned Model Accuracy:", C_accuracy_tuned)
9. 最適パラメーターを使ってモデルの再評価
ベストなパラメーターをあらためて精度評価し変化を確認します。
今回Cパラメーター調整による精度変化は見られませんでした。
# Resortホテルモデル精度評価
R_conf_matrix = confusion_matrix(R_test_y, R_LR_y_pred_tuned)
print("R_Confusion Matrix:")
print(R_conf_matrix)
R_accuracy = accuracy_score(R_test_y, R_LR_y_pred_tuned)
R_precision = precision_score(R_test_y, R_LR_y_pred_tuned)
R_recall = recall_score(R_test_y, R_LR_y_pred_tuned)
R_f1 = f1_score(R_test_y, R_LR_y_pred_tuned)
print("R_Accuracy:", R_accuracy)
print("R_Precision:", R_precision)
print("R_Recall:", R_recall)
print("R_F1 Score:", R_f1)
# Cityホテルモデル精度評価
C_conf_matrix = confusion_matrix(C_test_y, C_LR_y_pred)
print("C_Confusion Matrix:")
print(C_conf_matrix)
C_accuracy = accuracy_score(C_test_y, C_LR_y_pred)
C_precision = precision_score(C_test_y, C_LR_y_pred)
C_recall = recall_score(C_test_y, C_LR_y_pred)
C_f1 = f1_score(C_test_y, C_LR_y_pred)
print("C_Accuracy:", C_accuracy)
print("C_Precision:", C_precision)
print("C_Recall:", C_recall)
print("C_F1 Score:", C_f1)
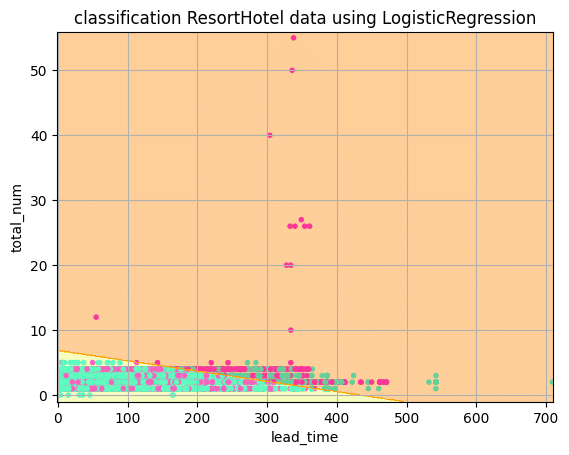
10-1. リゾートホテルの予測結果の描画
予測結果をMatplotlibを使って描画していきます。まずはリゾートホテルです。
# 全データを散布図にプロットし、ラベルごとに色を分ける
plt.scatter(R_train_X.iloc[:, 0], R_train_X.iloc[:, 1], c=R_train_y, marker=".",
cmap=matplotlib.cm.get_cmap(name="cool"), alpha=1.0)
# グラフの範囲を決定
x1_min, x1_max = R_train_X.iloc[:, 0].min() - 1, R_train_X.iloc[:, 0].max() + 1
x2_min, x2_max = R_train_X.iloc[:, 1].min() - 1, R_train_X.iloc[:, 1].max() + 1
# グラフを0.02ごとに区切った時の交点の座標を格納
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.1),
np.arange(x2_min, x2_max, 0.1))
# 全てのxx1,xx2のペアに対して、学習モデルで予測を行う
Z = R_best_model.predict(np.array([xx1.ravel(),xx2.ravel()]).T).reshape(xx1.shape)
# 座標(xx1, xx2)にZを描画
plt.contourf(xx1, xx2, Z, alpha=0.4,
cmap=matplotlib.cm.get_cmap(name="Wistia"))
# 範囲、ラベル、タイトル、グリッドを指定
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
plt.title("classification ResortHotel data using LogisticRegression")
plt.xlabel("lead_time")
plt.ylabel("total_num")
plt.grid(True)
plt.show()縦軸のtotal_numの単位:予約者人数の総数(大人+子供+幼児)
横軸のlead_timeの単位:リードタイム日数(宿泊から何日前に予約したか)
水色の点:キャンセルしないと予測された点
紫色の点:キャンセルされると予測された点
黄色のエリア:キャンセルしないと分類された範囲
橙色のエリア:キャンセルされると分類された範囲
total_numが10名を超えている予約はすべて紫色の点になっているのでキャンセル確率が高いと予想されています。また、lead_timeでは300日を超えたあたりから紫色の点の割合が増えていています。リゾートホテルでは40~50名のグループサイズの予約も発生していることがシティホテルとの違いになります。
10-2. シティホテルの予測結果の描画
続いてシティホテルです。
# 全データを散布図にプロットし、ラベルごとに色を分ける
plt.scatter(C_train_X.iloc[:, 0], C_train_X.iloc[:, 1], c=C_train_y, marker=".",
cmap=matplotlib.cm.get_cmap(name="cool"), alpha=1.0)
# グラフの範囲を決定
x1_min, x1_max = C_train_X.iloc[:, 0].min() - 1, C_train_X.iloc[:, 0].max() + 1
x2_min, x2_max = C_train_X.iloc[:, 1].min() - 1, C_train_X.iloc[:, 1].max() + 1
# グラフを0.02ごとに区切った時の交点の座標を格納
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.1),
np.arange(x2_min, x2_max, 0.1))
# 全てのxx1,xx2のペアに対して、学習モデルで予測を行う
Z = C_best_model.predict(np.array([xx1.ravel(),xx2.ravel()]).T).reshape(xx1.shape)
# 座標(xx1, xx2)にZを描画
plt.contourf(xx1, xx2, Z, alpha=0.4,
cmap=matplotlib.cm.get_cmap(name="Wistia"))
# 範囲、ラベル、タイトル、グリッドを指定
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
plt.title("classification CityHotel data using LogisticRegression")
plt.xlabel("lead_time")
plt.ylabel("total_num")
plt.grid(True)
plt.show()縦軸のtotal_numの単位:予約者人数の総数(大人+子供+幼児)
横軸のlead_timeの単位:リードタイム日数(宿泊から何日前に予約したか)
水色の点:キャンセルしないと予測された点
紫色の点:キャンセルされると予測された点
黄色のエリア:キャンセルしないと分類された範囲
橙色のエリア:キャンセルされると分類された範囲
先ほどのリゾートホテルモデルではtotal_numが10名を超えている予約はすべて紫色の点になっていましたが、シティホテルモデルではtotal_numが上がるほど紫色の点が発生しているわけではないようです。むしろlead_timeが150日を超えてくるとキャンセル確率が高いと予想されています。

まとめ
今回ロジスティック回帰モデルのCパラメーターを調整したことによる精度の変化は見られなかったので、ランダムフォレストなど他のモデルを使用してみて精度に変化がでるかどうかが今後の課題になります。より精度を上げていけば「仮押さえでキャンセルされる可能性が高い予約を事前に検知するモデル」として活用することができるようになるのではないかと思います。
今後について
今回は業務との両立ができず最後に短期間で追い込む形になってしまい悔しい思いです。受講が終わってもAidemyの教材で学習を継続してアウトプットをしていこうと思います。また数学的な知識があることでより本質的な理解ができるとわかりましたのでそこの知識増強も追ってできればと思います。
この記事が気に入ったらサポートをしてみませんか?