
【図解】超高性能AIボイスチェンジャー「RVC」のしくみ・コツ

はじめに
↑に貼った動画は話題の高性能ボイスチェンジャー「RVC」の変換例です(Creative Commonsで配布・改変が可能なライセンスの音声データを学習させたものです。BOOTHで無料配布中です)。今回の記事では動画の4つ+1の計5モデルを作成する中で見えてきたRVCの仕組みや使用時・モデル生成時のコツを紹介したいと思います。
(ライセンスはそれぞれ異なり、元データに準拠します)
注意事項

本編に入る前にいくつか前提を明らかにしておきます。私自身、RVCや音声認識についての専門知識はほぼありません。RVCについて初めて知ったのは約2週間前で、そのレベルは初心者の域を出ないと思っていただければと思います。さらに、RVCのモデルであるHuBERTやトランスフォーマーに関する知識もあまりありません(論文もまともに読んでません)。
したがって、この記事の内容は絶対的な真実と捉えず、RVCがどのように動作するかを大まかに理解する一助としていただければ幸いです。記事を読んでいて疑問点や不明な点がある場合は、お手数ですがご自身で調べていただければと思います。
比較するモデルの紹介

*今回比較するモデル。それぞれ特性が異なります*
本記事の主要テーマに入る前に、私が作成し比較するためのモデルについて紹介します。今回作成した5つのモデル
となっています。ただし、最後のやさしいお姉さん・おじさんについて元のデータセットが同一で、その傾向も類似しているため、今回の記事ではお姉さんのモデルのみを扱います。
これらのモデルを作成する過程で、いくつかの特徴を確認することができました。それらは主に以下の3つです。
音質: 作成したモデルによって音質は大きく異なり、スタジオ録音のように非常にクリアな音声から、家庭での録音レベルまでバリエーションが見られました。
感情表現等への耐性: 同じ音声を変換しようとしても、ヒロインキャラや爽やかな青年のモデルでは上手く変換されるのに対し、優しいお姉さんのモデルでは変換が大幅に乖離することが確認できました。
話し手との相性: モデルによっては、特定の話し方や声質で話すと良好な変換結果が得られる傾向がありました。例えば、クールな女性のモデルは声がこもりがちな人に合い、逆にヒロインキャラのような声質のモデルは、やや声が曇り気味の人では変換にノイズが発生しやすいという特性が見られました。
これらの特徴は、モデルを作成し、自身の声で変換する過程で明らかになりました。その結果、人の声質によってモデルの適応性が変わることが明らかになりました。記事の次節では、RVCの基本情報や内部の動きを詳細に見ていくことで、これらの特徴がどのような理由で生まれるのかを解き明かします。
RVCの基本情報

RVCは、人気のある生成型AIの一種であり、人間の音声を生成することができます。その性質から、この技術は「生成AI」と呼ばれています。生成AIは、ChatGPTやStable Diffusion、Midjourneyなど、さまざまなタイプが存在します。その基本的な概念は、新たな情報を生成するAIで、画像、テキストデータ、音楽などのコンテンツを出力するのが特徴です。
一般的なAIは、入力データから情報を抽出し、それを出力とするもので、モデルの出力が情報という特性があります。しかし生成AIは出力の部分が新たなコンテンツを生成するという点で異なります。
生成AIでは、学習時に入力されたデータの特徴のエッセンスを抽出してモデルに詰め込みます。推論する際には、入力のコンテンツに対して、学習した特性を活かして新しいコンテンツを生成します。
RVCのベースとなる技術は「HuBERT」を使用しています。モデル作成時には、特定の人の声を一から作成するのではなく、まず一般的な人の声のモデルが存在します。これは、たくさんの人の発話データを学習し、人間の一般的な声の特性を理解するためのものです。
RVCは、このベースモデルに学習したい人の声の情報を上から重ねるようにして作成します。このベースモデルが存在することで、学習対象の人の大量のデータを用意する必要がなく、約10分のデータがあれば学習することが可能です。
RVCの利点として、音程の調整幅だけを設定すれば良いという点があります。つまり、設定項目はほぼなく、使用が非常に容易です。また、RVCは非常に軽いため、GPUのVRAMをあまり使わず、学習時には約6GB程度、推論時には約2GB程度しか使用しません。そのため、VRAMが学習時なら8GB/推論時なら4GBしか搭載されていないマシンでも使用することが可能です。
さらに、RVCは変換速度が非常に速く、リアルタイムで音声の変換が可能です。これは、RVCモデルの一般的な使用法であり、最近ではこれが一般的になってきています。
RVCの高速性に貢献している技術として、FAISS(Facebook AI Similarity Search)というものがあります。これについては後ほど詳しく説明します。
RVCは、その能力と使いやすさから、多くのユーザーにとって非常に魅力的なツールです。特に音声生成や音声変換を行いたいユーザーにとっては、その使い勝手と性能の高さから非常に魅力的な選択肢となっています。
RVCのしくみ(学習)
ここではRVCの内部動作、特に学習メカニズムについて解説いたします。AIがデータセットの特徴を学習する過程を理解することが、このモデルの本質を把握する上で不可欠です。
学習された特徴は空間上に配置されるという形で表現されます。この特徴が配置される空間を「潜在空間」と呼びます。以下の説明では、RVCがどのように潜在空間を学習するかについて詳しく述べます。

(❕注意❕)以下で表現される潜在空間のイメージは、分かりやすさを最重要視した結果、実際のRVCの潜在空間とは大きく異なる可能性があります。ですので、以下の内容を絶対的な真実と受け取らず、潜在空間の雰囲気をつかむ材料としてご覧いただければと思います。
ここではRVCの潜在空間を2次元の空間と仮定します。2次元の軸は、縦軸がピッチ(音の高さ)、横軸がシーン(朗読や感情表現、歌唱など)としています。縦軸は下が低音、上が高音となり、横軸は左から右に向かってシーンが変化します。この空間内で、入力音声(例えば「あいうえお」など)はそれぞれ異なる位置に配置されます。
具体的な学習プロセスを見ていきましょう。例えば、「こんにちは」というフレーズを前述のヒロインキャラクターの声として学習する場合を考えてみます。

まず、「こんにちは」を1文字ずつ区切り、それぞれの音が潜在空間上のどこに対応するかを学習します。今回は、「こんにちは」というフレーズが通常の話し言葉としての表現であり、キャラクターが比較的高いピッチで話すという条件を設定します。


~中略~

この音声データが学習されると、潜在空間上の特定の位置にそれらの音が配置されます。具体的には、ヒロインキャラクターの「こんにちは」は、比較的高いピッチで普通に話すというシーンに対応する位置に配置されることになります。
そして、さまざまな音声データが次々と入力され、学習が進むと、キャラクターの声の特徴が潜在空間上に表現されていきます。例えば、データセットが話し言葉の表現だけでなく、感情表現も含む場合、ヒロインキャラクターの声は、通常の話し言葉と感情表現の間で、比較的高いピッチの範囲に分布します。
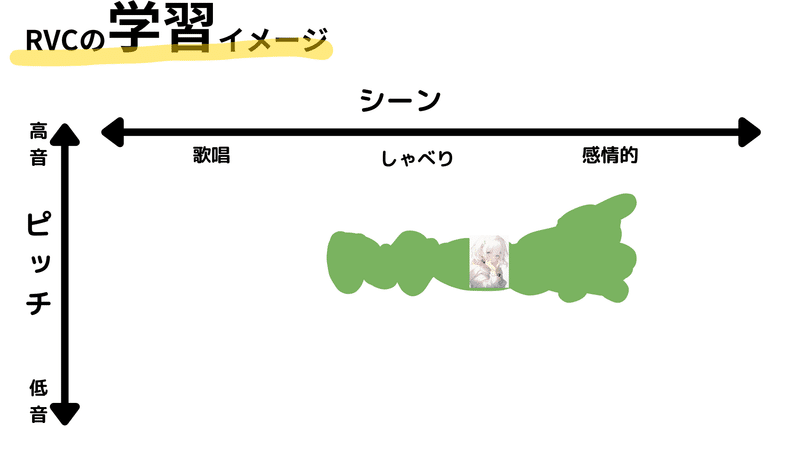
このようにRVCの学習プロセスは進行し、結果として多種多様な音声表現が潜在空間上に学習・配置されることになります。そしてこれがRVCが異なる声質や話し方を再現できる基盤となります。様々な特徴やニュアンスが混在したデータセットから、適切に特徴を抽出し、それぞれを適切な位置に配置することで、モデルは多様な音声表現を学習することが可能となるのです。
RVCのしくみ(推論)
学習されたRVCモデルに対し、変換したい音声を投入すると、モデルはその音声を所定の特徴に基づいて変換します。一般的に、学習されたモデルに対してデータを投入し結果を得ることを推論と言いますがここではその推論の過程について具体的に見ていきましょう。
まず、ユーザーが発話した音声を分析します。この時、学習時と同様に細かい区間に分けて処理を行います。例として、「こんにちは」というフレーズを1文字ずつ分析し、その音声特徴を潜在空間上にマッピングします。ここでは声の低い男性が話しているとします。その場合は、マッピングされる位置も低音の範囲に配置されます。
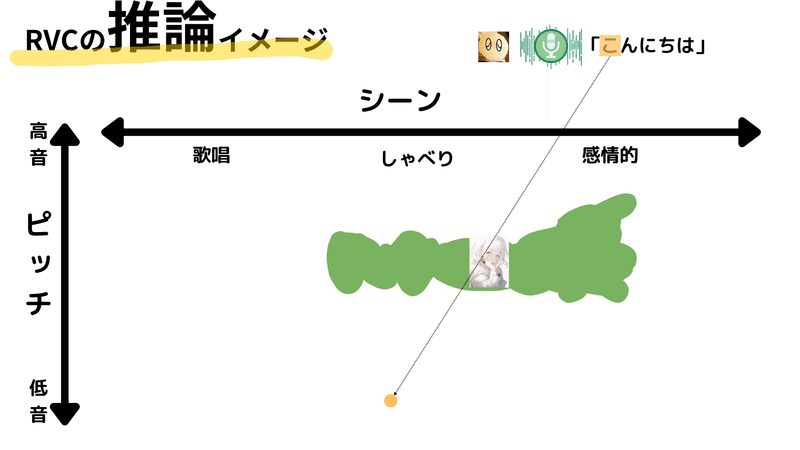
~中略~
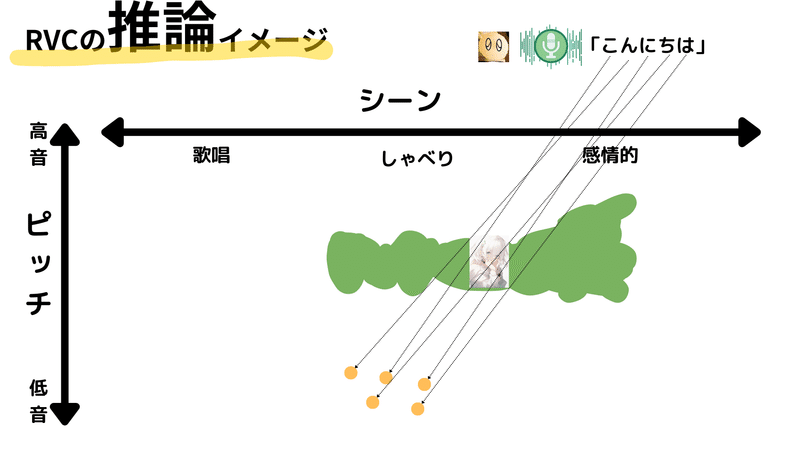
ただし、問題が一つあります。それは、入力の音の特性が、学習時に得られた潜在空間のどの領域にも存在しない場合です。つまり、モデルが学習していない音声特性を持つ入力が与えられた場合、その音声を適切に変換することが困難となります。
ここで活躍するのが「ピッチ変換」です。ピッチ変換は、音声のキーを変更する機能で、RVCツールにも基本的に設定されています。これを使うと、入力音声のキーを調整して、学習時のデータに近い範囲に移動させることが可能になります。
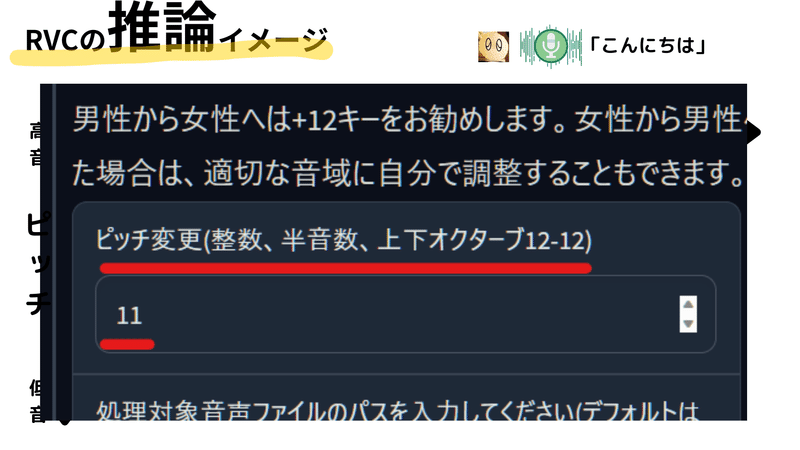
例えば、男性ユーザーが女性の声に変換したい場合、ピッチ変換を用いて音声のキーを上げます。逆に、女性が男性の声に変換したい場合は、キーを下げます。このようにして、ユーザーの声は潜在空間上で適切な位置に調整され、それに基づいて音声変換が行われます。
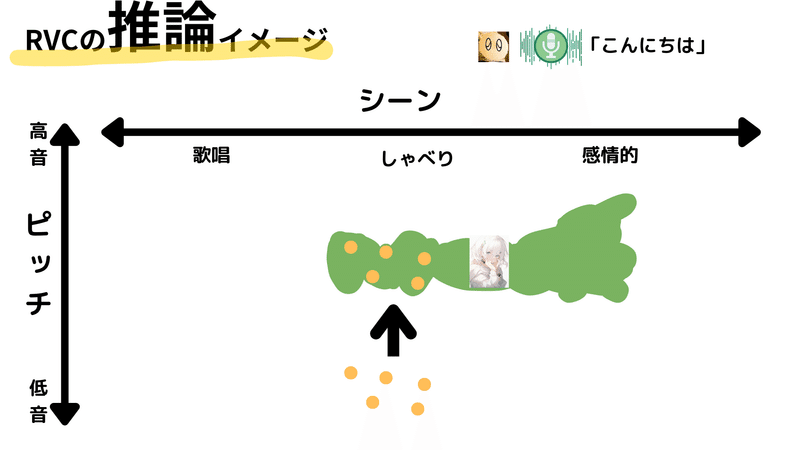
この時、変換の基となるのは学習時に得られたデータで、それがほぼそのまま採用されます。結果として、ユーザーの音声は、その特性に基づき、学習された目的の声に変換されることになります。これが、RVCの推論における声の変換プロセスの概要です。
そして推論がうまくいった場合、ユーザーの音声は自然で信頼性の高い出力音声に変換されます。これにより、「こんにちは」という発話も、元の男性の音声から女性の音声へと自然に変換されます。
しかし、ここで注意すべきは、この変換が成功するか否かは、ユーザーの入力音声と学習データとの一致度に大きく依存するという点です。具体的には、入力音声の特性が学習データと一致していない場合、適切な変換が難しくなります。そのため、ピッチ変換などを用いて入力音声を調整し、学習データに近づけることが重要となります。
外れたときはどうなるの?
推論の仕組はわかりましたが、こうなると気になってくるのは、「RVCが外れた場合どうなるの?」という点だと思います。例えば、現状我々が訓練に使ったデータは主に話し言葉や感情表現のものであり、歌唱表現などは含まれていません。したがって、もし歌声のような、学習データに含まれていない音声をRVCに入力した場合、どうなるのでしょうか?
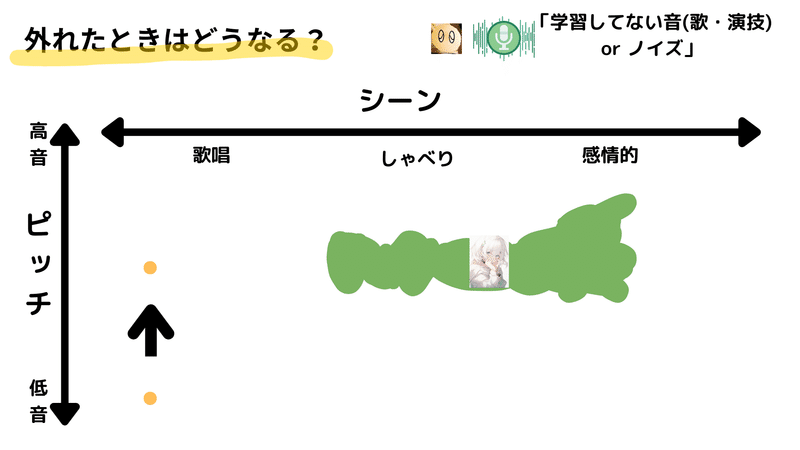
その答えは、基本的には適切な出力が得られない、というものです。入力が学習データと大きく異なる場合、RVCは適切な変換結果を出すための「一致する」部分を見つけられません。そのような時、RVCはどういった処理をするのでしょうか。その答えは、FAISSという技術にあります。
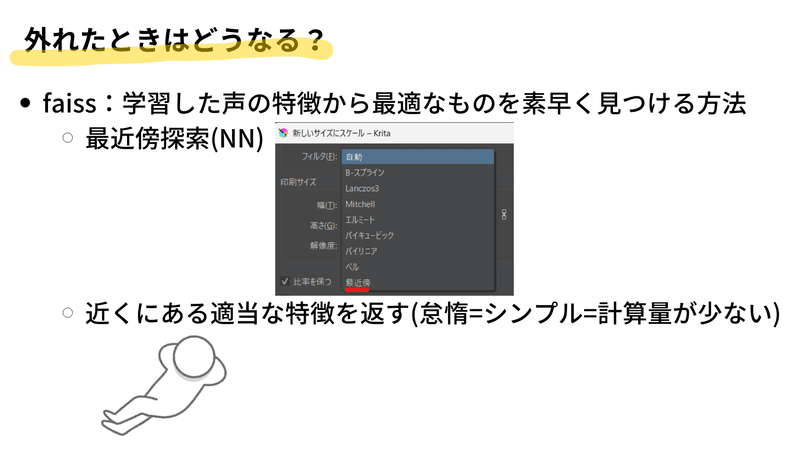
FAISSは、フェイスと読みます。これは、大量の学習データから推論のための最適なデータを高速に探し出す技術です。一言で言えば、最近傍探索(Nearest Neighbor、NN)の技術と同様のものです。
皆さんが画像エディタ(GIMPやKrita、Photoshopなど)で画像のリサイズをする時に、補間アルゴリズムを選べることがあると思います。その中には、Bilinear、Bicubic、Lanczosなど様々な補間方法がありますが、その中でも最も単純なものが最近傍探索です。
画像のリサイズでは、例えば100x100の画像を200x200に拡大すると、画像の領域が2倍になり、新たなピクセルが必要となります。この新しいピクセルをどのように生成するかが問題となるわけですが、最近傍探索では、新しいピクセルの位置に最も近い既存のピクセルの色をそのまま使います。
FAISSもこれと似たようなことを行います。特徴空間内で、入力に最も近い特徴を探し出し、それを出力として用います。これにより、計算が極めてシンプルになり、高速な推論を可能にします。FAISSのおかげで、RVCは推論時に必要なVRAMを削減し、高速な推論を実現していると思われます(想像です)。
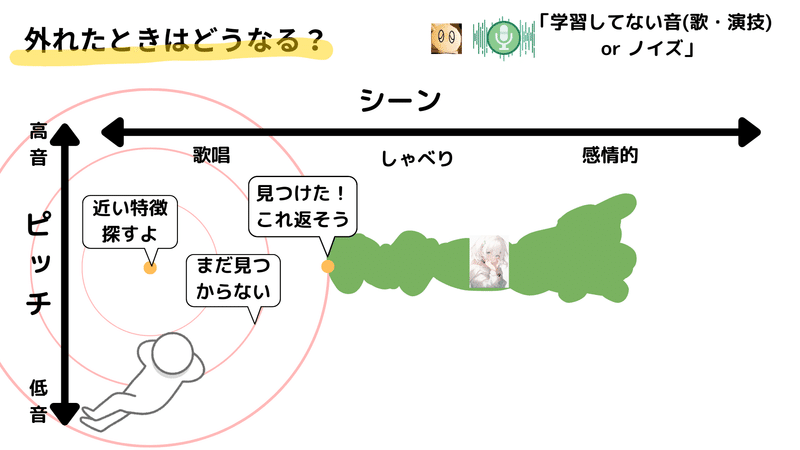
では、FAISSの探索が具体的にどのように行われるか見てみましょう。探索開始位置をオレンジの点とし、そこから最も近い特徴を探し出します。この探索は基本的に同心円状に行われ、最初に見つかった特徴が選ばれます。つまり、探索範囲を徐々に大きくし、初めて見つかった特徴を採用します。
しかし、入力が学習データと大きく異なる場合、適切な特徴が見つかるまで探索範囲が大きくなってしまうことがあります。その結果、見つかった特徴が探索開始位置から非常に遠い場合があります。
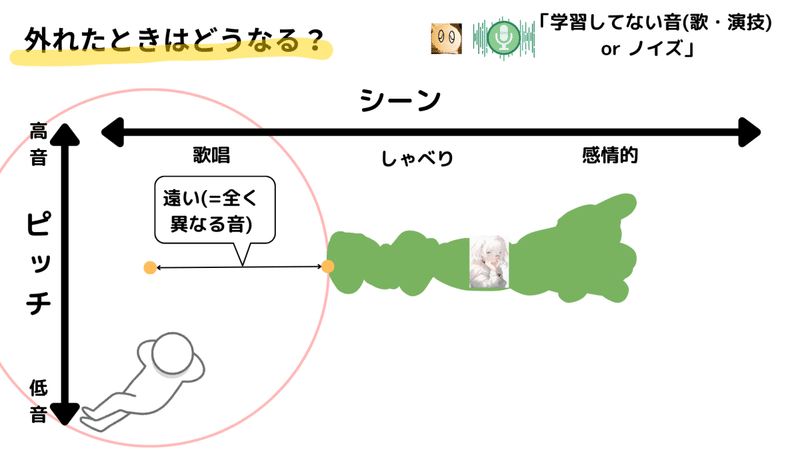
そうなると、出力される音は元の音とは大きく異なることがあります。実際に各モデルでノイズがどのように変換されるかを↓の動画で確認することができます。
この動画では元の音が金属のコップを打つ音なのですが、出力音は機械のノイズや咳のような音、あるいは咳などの全く予想できないような音になることがあります。その出力音は学習モデルによりまちまちです。
これは、FAISSが探索を行う際に適切な特徴が見つからず、遠くの特徴を取得してしまうことで誤差が大きくなり、予期しない音が出力されるためです。
このような現象を防ぐためには、訓練データを多様化し、FAISSが探索を行う際に適切な特徴を見つけやすくすることが有効です。具体的には、訓練データとして話し言葉だけでなく、感情表現や歌唱などの多様な音声表現を用意することが重要です
また、当然ながら、推論の入力データにノイズを含めないことも重要です。ただし、モデル側にも幅広い音声表現を学習させておくことは、誤差を最小限に抑えるために重要な要素となります。

学習データの量は?
AI音声変換技術「RVC」の学習データの必要量についてご説明します。多くの方が気にされることと思いますが、RVCの学習に必要な音声データの量は実はそれほど多くはありません。これは、RVCが既存のモデルをベースにカスタマイズを行うため、高品質でノイズの少ない音声が一定量あればモデルの作成が可能だからです。
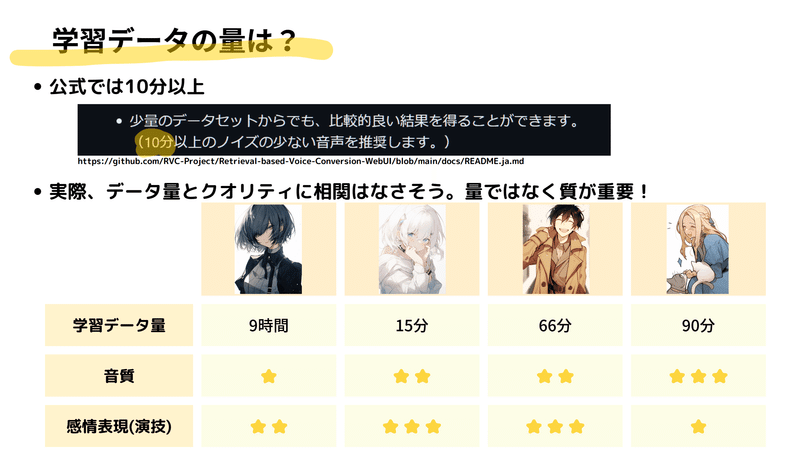
実際に私たちが作成した4つのモデルでは、学習に使ったデータの量がそれぞれ大きく異なっていました。モデル「クール系女性」では全9時間の長大なデータを利用した一方で、モデル「ヒロインキャラ」では15分程度の短いデータを使用しました。しかし、これらのモデルの音質や感情表現の対応範囲を比較したところ、データの量とモデルの品質には明確な相関が見られませんでした。
これは、例えば9時間のデータを使用したモデルは、元々の録音環境が個人のPCで音質がそれほど高くなかったため、音質が低くなりました。逆に、良質な録音環境で取得したデータを使用したモデルは、その音質の良さが反映されています。
また、感情表現の対応範囲についても、元の音源に含まれていた演技的な読み上げが多いほど、モデルの感情表現の対応範囲も広がりました。逆に、元の音源が原稿読みのような感情表現の少ないものだった場合、感情を出すような音源への変換は困難で、破綻しやすいという傾向がありました。
これらの結果から、RVCの学習においては、データの量よりも質が重要であると言えます。質とは、音質の良さや表現できる感情の幅などを指します。例えば、原稿読みだけでなく、演技的な読み上げや歌唱など、様々な表現を含むデータを用意することで、モデルはさまざまな表現に対応できるようになります。公式でも指摘されている通り、十分な品質を保証する音声データが約10分分あれば、それが最低ラインと言えます。
しかし、ここで重要なのは「質の良いデータを準備する」ことです。つまり、音質が良く、ノイズが少ない、そして多様な表現を含む音声データが理想的です。一見、データ量が多いとモデルの学習が有利に思えるかもしれませんが、RVCの場合は質の高さが優先されます。
結論として、RVCの学習データは「多ければいい」というものではなく、「質がいい」ことが重要です。つまり、その音声データの録音環境や、読み上げられる内容のバラエティがモデルの性能に大きく影響するということです。

申し訳ございませんでした
この「学習データの質」に関連して、一点お詫びしたいと思います。
私がRVCモデルを公開した際に、次のようなツイートを行いました。
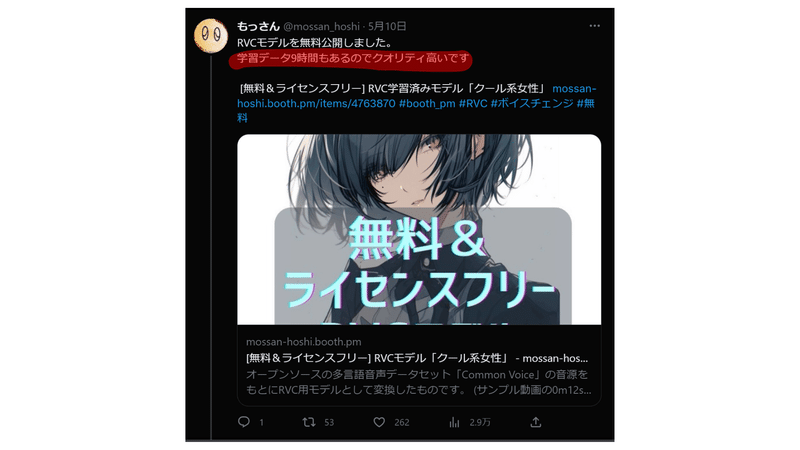
(実際は関係なかったです)
この時点では、初めて作成したモデルだったため、そのクオリティに満足していたのです。しかし、その後に他のモデルを作り始めると、この最初のモデルが特別にクオリティが高いわけではないことに気づきました。先ほど「学習データの量は?」の章で解説したように、データの量だけでクオリティが高いと言えるわけではありません。
そのため、このツイートで「9時間もの学習データがあるからクオリティが高い」と発言したことは、誤った認識でした。特に、このツイートが広く拡散されてしまったために、取り消すのも難しい状況になってしまいました。
このような誤解を招く発言をして申し訳ありませんでした🙇
しゃべるとき(推論)のコツは?
今までの話では学習データについて詳しく解説してきましたが、ここからは「RVC」を使って実際に自分の声や他の音源を変換するときに注意すべきポイントについて説明します。
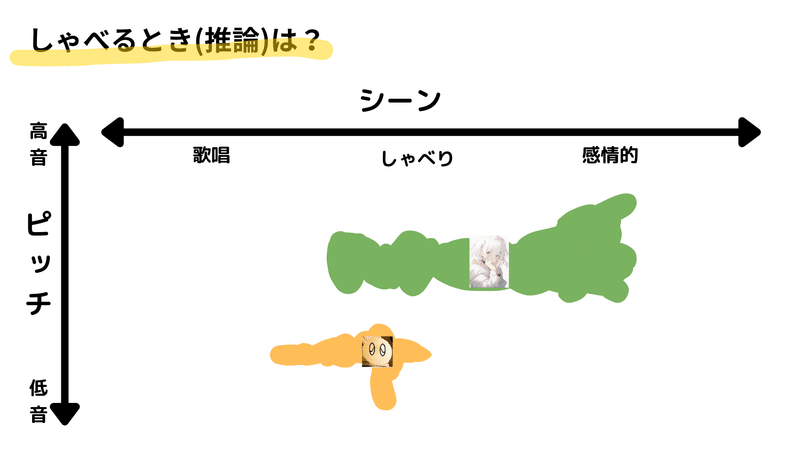
まず、声を変換する際には、元となる音声(図中オレンジ領域)と、それを変換したい音声(図中緑領域)があります。ここで重要なのは、オレンジの音声がどれだけピッチの幅があるか、そしてそれが緑の音声の範囲に収まるか、という点です。
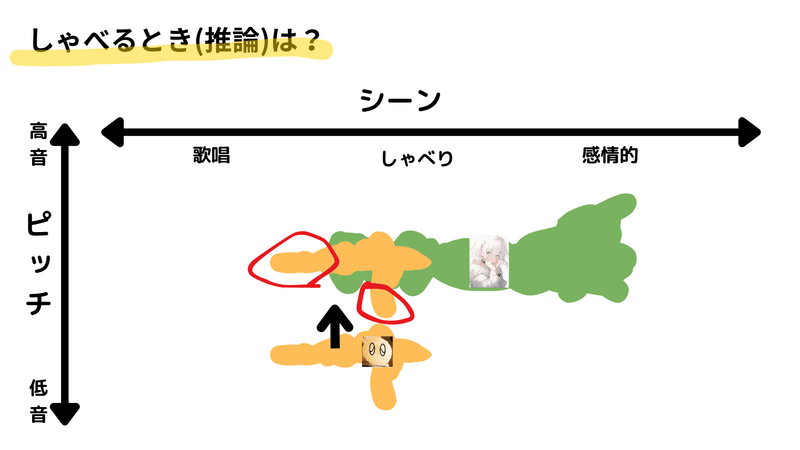
例えば、オレンジの音声のピッチの範囲が非常に広い場合、そのピッチの広がりを緑の音声に合わせようとすると、一部の音声が不自然に変換されてしまうことがあります。具体的には、語尾などで低い音が出てくる場合、その部分が突然破綻してしまう、という現象が起こります。
また、音源に含まれている音が目指す音声の範囲に存在しない場合もあります。この場合、変換すると全く違う音になってしまい、結果としてノイズになってしまいます。
これらの問題を解決するための対策としては、まず一つ目は自分の得意な形のしゃべり方に合ったモデルを選ぶことです。二つ目の方法としては、自分の声を目指す声に合わせていく方法もあります。特に、自分の声のピッチの範囲が広い場合は、その範囲を狭めて目的の声に合わせる努力が求められます。これは声トレに近い作業になりますが、「RVC」ではリアルタイムまたはそれに準ずる形でフィードバックが得られるため、トレーニングとしては比較的行いやすいと思います。
また、自分の声を録音してエフェクトをかけるなどして音声を加工する方法もあります。ここでも、オレンジの音声の範囲を緑の音声の範囲に収まるように調整することが求められます。
以上のように、自分の声を他の音声に変換する際には、自分の声と目指す音声の範囲が一致するようにすることが重要であるという点を強調したいと思います。これを意識して、自分の声に合ったモデルを選んだり、自分の声を目指す声に合わせるように努力することが大切です。
余談ですが、ある友人がかつて、単純なカラオケのピッチ変換機能を使用して、高いキーの女性声優の声を完璧に再現した経験があります。これを例に挙げると、個人の努力と工夫次第で、異性の声に自分の声を適応させることも決して不可能ではないことを示しています。特にRVCの精度は非常に高いので、その点での制約は比較的少ないと言えるでしょう。
なお、音声の加工にはオフラインで行うことが一般的であり、エフェクトをかけて調整することも可能です。これにより、特定の範囲を補填したり、調整したりすることが可能となります。
私自身もさまざまな方法を試してきましたが、一部はまだ完全には成功していません。そのため、具体的な方法についてはここでは詳しくは説明しません。
ただし、ここで強調したいのは、ターゲットとなるモデルが学習している領域に自分の音声を落とし込むという共通のコンセプトです。これを抑えておけば、自分の声を効果的に変換するための方向性が見えてくるでしょう。
したがって、まとめますと、自分の声に適したモデルを選ぶことが基本であり、そして、自分の声を目指すモデルに合わせることに努力を注ぐことが重要です。これらを念頭に置くことで、より自然な音声変換が可能になるでしょう。

RVCのコツまとめ
長くなってしまいましたがここまでのポイント(+説明し忘れていたポイント)を紹介したいと思います

学習時のコツ
音源の音質
RVCの学習には録音状態の良い音源の使用が推奨されます。ノイズの多い音源は、学習の結果、モデルの品質を下げる可能性があるため、ノイズの影響を避けるようにしましょう。良好な録音条件下で得た音源を使用すれば、より高品質なモデルを作成することが可能です。
音源のバラエティ
音源のバラエティも重要な要素です。もし、音源に演技的要素を加えたい場合、感情表現を含んだ音声を使用するとよいでしょう。また、歌をモデルに取り入れたい場合は、アカペラの音源を使用します。これにより、モデルの表現幅が広がり、ノイズに対する強度もある程度高まると考えられます。
学習データの量と質
モデル作成においては、データの質が量よりも重要です。データの長さは10分程度で十分であり、上記の要件を満たした質の高いデータを使用することを推奨します
推論時のコツ
愛称の良いモデル
推論する際は、自分の声に適したモデルを使用することが重要です。そのためには、自分の声をモデルに適応させる努力が必要となります。また、基本的には滑舌よく話すことで、大きく外れることは少なくなると思います。
特に、ブラウザや画面の文字を読み上げる機械音声(TTS)のような明瞭で比較的平坦な発音は、変換エラーが少ないとされています。
音質(特にノイズ)
推論の音声についても、ノイズが変な音に変換される可能性があるため、極力クリアな音声を使用することが推奨されます。
さいごに(権利・倫理について)
権利について
このようにRVCはとてもすごい技術ですが、すごい技術である分、様々な危険性があります。なりすまし、名誉侵害、著作権侵害などです。
実際に先日、とある声優さんの声を学習したモデルを学習したモデルをBOOTHで販売した人物がおり、すぐに公式にアカウント凍結されていました。
AI作品を販売停止にせず温情を見せたboothがさっそく有名声優の無断AIボイス販売会場にされてる
— みや (@miyamoyame) May 17, 2023
安定の著作権法30条の4が悪用されてる模様
某有名お嬢様系キャラ風になれるボイスチェンジャー、あの艶っぽい声が手に入る!!RVC・MMVC対応 | AIガジェット販売 https://t.co/qc2XbwjY3i pic.twitter.com/rbBVzzV5iq
また、ネット上には勝手に有名人やアニメキャラ等を学習したモデルがやり取りされているという話も聞きます(私はアクセスしたことがありません)。
早くもネット上では人気声優の声を使ったRVCの学習モデルが公開されはじめてます
— ゆうぷろ / YuuPro (@YuuPro_2022) April 15, 2023
権利関係はもちろんですがファイル自体が危険な可能性もあるので、見つけても絶対にダウンロードしないよう注意しましょう!! pic.twitter.com/pNliFnJwB1
このように簡単に一線を越えてしまう技術ですので、モデルの作成・使用には権利関係についても注意が必要です。
どのようなモデルや音源であれば使えるのかは、リポジトリとしてまとめてくださってる人がいるので参考にしていただければと思います。
RVCのような音声変換モデルやその学習に使える音源を音声から探すためのリポジトリを作成しています。https://t.co/jnh4ohZPeH
— nadare🌱 (@Py2K4) May 4, 2023
リポジトリ中のnotebookをcolab等で実行すると、音声から類似した声質の音源やモデルをライセンスやクレジットを確認しながら検索できます。(続) pic.twitter.com/4b5JSfTPtE
倫理について
法律面やライセンス面での権利がクリアになったとしても、倫理的に問題が生じる可能性は否定できません。ご存じの通り生成AIの技術の進歩はすさまじく、数年前には考えもしないようなことが現実にできるようになっています(RVCもその1種です)
そのため、原稿の法制度や各種ライセンスの規約が追いついていないこともあり、倫理的に問題が生じる可能性があります。
私が公開しているモデルにおける倫理について
私が公開しているモデルに関してもそのような可能性が完全には否定できません。将来法制度がRVCモデルの共有を制限するようになった場合や、元データの生成者がモデルの生成に対して否定的な反応を行った場合はモデルの公開は停止する予定です。
とはいえ、Common Voiceや各種コーパス音源など、元々音声認識アプリを作るために作られたデータセットであれば、RVCに様なアプリも想定の内と思われるためその可能性はかなり低いと判断し現状公開しています。
RVC WebUIの使い方
本記事ではRVCの実際の使い方は説明していませんが、画面の解説画像は作ってます。使用する際の参考にどうぞ
RVCの画面解説画像を作りました
— もっさん (@mossan_hoshi) May 17, 2023
よくわからない項目が結構ありますが
この程度の理解でもモデルを作れます#rvc #ボイスチェンジャー pic.twitter.com/vOhrlKXQ5K
この記事で紹介したモデル
この記事で紹介したモデルを含む5モデルをBoothにて無料配布しています。いずれもクリエイティブコモンズの配布・改変を許可している音源を学習しています。ライセンスは元のデータに準拠しそれぞれ異なります。ご使用の場合はBoothのページをご確認ください。
この記事の元となった動画
この記事は以下の動画を記事化したものです
(声は「クール系女性」に変換してます)
この記事が気に入ったらサポートをしてみませんか?