
ABC192の解答

SOMPO HD プログラミングコンテスト2021(AtCoder Beginner Contest 192)の問題を解き終わりましたのでその解答を書いていきます。
問題はこちらから。
難易度はこんな感じでした。
A 7(灰)
B 23 (灰)
C 105(灰)
D 1425(水)
E 1135(緑)
F 1783(青)
今回の問題は今までのabcと比較すると若干優しめな難易度になってますね。ただ私は「ほんとですか?」って思います。解説を読んで、なんとなく理解はできるのですが、そこからacまでが非常に長かったです。言葉を選ばないなら「むずくね?」といった感じです。なんとなくやることは分かったけど、なんか実装がうまくいかない、バグが取れない、waが少しだけ出るみたいな状況に陥りました。
ですので、私がコンテスト本番およびコンテスト後の復習時において嵌ってしまった点なども併せて書いていけたらと思っています。本記事が誰かのお役に立つことを願っていると同時に、執筆を開始する現在において、そうなるように精一杯頑張ろうと思っております。
ただ、毎度のことながら長くなると思いますので、のんびりとお読みいただけたら幸いです。
ではいきます。
A Star
高橋君はゲームで遊んでいます。このゲームでは集めたコインの枚数が100の倍数になるとご褒美がもらえるみたいです。今 x 枚持っているので、次のご褒美のためにはあと何枚必要でしょうか。ただし、x が100の倍数のとき、そのご褒美はすでにもらっています。
という問題です。ご褒美は何がもらえるのでしょうか。1upですかね。
あと何枚でご褒美ですか?という感じですので、不足分を求めましょう。100の倍数とあんまり数がおおきくないので、好きなようにやって大丈夫です。x に+1ずつしていって、100の倍数になるまでに何回足したか、でもよいです。
今回は 「%」 を使いました。「%」を使うと割り算の余りを求めることができます。例えば、
140 / 100 = 1 ... 40
ですので、
140 % 100 = 40
ですね。この演算をすることで、数字を0から99までに抑えることができます。問題は「100までにあと何枚必要か?」ですので、100から40を引いてあげましょう。答えは60枚ですね。一般化するとこんな感じ。
ans = 100 - (x % 100)
これを実装してあげましょう。
#include<bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define reps(i,s,n) for(int i=s;i<n;++i)
using namespace std;
using ll = long long;
using P = pair<int, int>;
int main()
{
int x;
cin >> x;
int ans = 100 - x % 100;
cout << ans << endl;
return 0;
}はじめは肩慣らしみたいな感じですね。私は一回間違えましたが、、、
ところで、1upって何て呼ぶのが正解なのでしょうか?「いちあっぷ」「わんなっぷ」「一機アップ」などなど。そもそも、「機」なのか?「人」もあるよね。
B uNrEadaBlE sTrInG
ある文字列の奇数番目が小文字で偶数番目が大文字の文字列は読みにくい文字列とされています。文字列 s が与えられたとき、 s が読みにくい文字列かどうか判定をしましょう。
という問題です。
指示通りに実装すればよい、と言われればその通りなのですが、少しだけややこしいですね。ちょっとだけ整理します(人によっては余計にややこしくなるかもしれません)。
読みにくい文字列
奇数:小文字 かつ 偶数:大文字
ですので
読みにくい文字列ではない
奇数:一つでも大文字があればよい
または 偶数:1つでも小文字があればよい
となりますね。ですので「読みにくい文字列ではない」ということを考えます。まず、bool をtrueにセットします。奇数番目が大文字、偶数番目が小文字かどうか判定します。ひとつでも引っかかってしまったら、bool を falseにしましょう。文字列全部の検査を潜り抜けてもtrueであれば、おめでとうございます。それは「読みにくい文字列です」ので"Yes"を出力します。falseになってしまったら「読みにくい文字列ではない」ので"No"となります。
図で示すとこんな感じ。

大切なのは「読みにくい文字列」の反対は「読みやすい文字列」とは限らないということです(反対というと少しぼんやりとしますね。また、「読みやすい文字列」言葉は本問題ではでてきません。勝手に作りました)。
あとは判定方法です。今回はもともと用意されていた機能を使います。
C++ : isupper(s), islower(s)
python : s.isupper(), s.islower()
これらですね。
さて実装です。
#include<bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define reps(i,s,n) for(int i=s;i<n;++i)
using namespace std;
using ll = long long;
using P = pair<int, int>;
int main()
{
string s;
cin >> s;
bool ok = true;
rep(i, s.size())
{
int idx = i + 1;
if (idx & 1)
{
if (isupper(s[i])) ok = false;
}
else
{
if (islower(s[i])) ok = false;
}
}
if (ok) cout << "Yes" << endl;
else cout << "No" << endl;
return 0;
}配列のインデックスは0から始まるので、偶数奇数に気を付けましょう。今回はidx = i+1として番目とインデックスを対応させています。
C Kaprekar Number
0以上の整数 x に対して、g1(x), g2(x), f(x)を次のように定めます。
g1(x) = xを十進法で表した時の各桁の数字を大きい順にならべた整数
g1(x) = xを十進法で表した時の各桁の数字を小さい順にならべた整数
f(x) = g1(x) - g2(x)
整数n, kが与えられたとき a0 = n, a(i+1) = f(ai) (i >= 0)で定まる ak を求めてください。
という問題です。
まずは計算量を把握するために制約を見てみましょう。
0 <= n <= 10^9
0 <= k <= 10^5
ですね。k はこの問題では繰り返しの回数に相当します。また、n は10^9までありますね。しかし、n 回for文を回すわけではなく、問題の初期値です。10^9ですので、桁数としては10桁分あります。
このまま少し計算量について考えます。次に、各操作g1, g2, f1 を見ていきましょう。f1 は簡単ですね。式一つで計算できます。次にg1 とg2 です。各桁の並び替えですね。これをとっても愚直に考えます。
まず、各桁の数字を一つずつ取り出して配列に入れてしまいましょう。これは問題Aでも使った「%」が活躍しますね。次のような感じで桁数を取り出せます。
例:1234567
1234567 % 10 = 7
1234567 / 10 = 123456 (余り切り捨て)
123456 % 10 = 6
123456 / 10 = 12345 (余り切り捨て)
・・・
1 % 10 = 1
1 / 10 = 0 (余り切り捨て)
0になったら終了です。この繰り返しは桁数分行われます。本問題では最大10桁ですので10回です。
次に、この配列をソートしましょう。g1とg2で昇順、降順が異なりますので注意です。一般にソートの計算量はO(N log N)です。本問題の N は桁数ですので N=10と小さいです。そのため、ソートの計算回数は 10 ぐらいでしょう。
最後に復元をします。ソートした数字たちに 10のなんとか乗の係数をかけて足し合わせます。先ほどの例を復元してみましょう。
例:1234567 を大きい順にする
ans = 0
ans += 1 * 10^0 (ans = 1)
ans += 2 * 10^1 (ans = 21)
・・・
ans += 7 * 10^6 (ans = 7654321)
この操作も桁数分の繰り返しですね。こちらの値がg1 となります。g2は小さい順にしてあげましょう。
これにより、g1, g2, および f も求められました。さて、この計算量って大体どのくらいでしょうか。ソートをどう見積もるかにもよりますが、最大ケースにおいても10の繰り返しのwhileとソート、復元。そしてこれをg1, g2の2回分。と考えると、6*10 = 60。 1試行で60回ほどループが回っています。
さて、これを繰り返し回数の k 回行うわけですが、k の制約を見るに、全体の計算は、
6 * 10 ^ 6
こんなもんで収まると思います(f の操作で桁数が減ることはあっても、増えることはありません)。これが大体の計算量になります。
さて、ここまで計算量について考えてきました。その結論として私が言いたいことは
愚直に書けばよし
の一言に尽きます。回りくどく説明しましたが、問題を解く際にはこれで十分です。g1, g2の関数も先の説明の通りです。「%」と「/」でやってソート、復元してあげましょう。
実装です。
#include<bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define reps(i,s,n) for(int i=s;i<n;++i)
using namespace std;
using ll = long long;
using P = pair<int, int>;
int g(int n,int g)
{
vector<int> v;
while (n > 0)
{
v.emplace_back(n%10);
n /= 10;
}
if (g == 1) sort(v.begin(), v.end());
else if (g == 2) sort(v.rbegin(), v.rend());
int res = 0;
int w = 1;
for (auto vi : v)
{
res += vi * w;
w *= 10;
}
return res;
}
int main()
{
int n, k;
cin >> n >> k;
int ans = n;
rep(i, k) ans = g(ans,1) - g(ans, 2);
cout << ans << endl;
return 0;
}実装のアドバイスというほどでもないのですが、g1とg2ってソート以外は同じ挙動をします。そのため、g1, g2を別々に作るよりも、if分岐とかで同一関数内で分ける方が良いのかなと思います。もし、この関数にバグがあった場合、関数を2つに分けているとデバッグが大変になりますので、、、
D Basen
0~9からなる文字列 x と、整数 m が与えられます。x に含まれる最も大きい数字を d とします。d + 1以上の整数 n を選んで x を n 進表記の数とみなして得られる値のうち、 m 以下であるものは何種類でしょう。
という問題です。結構問題がややこしいですね。入力例1を見て考えてみましょう。x = 22, m = 10ですね。まずは最大値 d です。これは、ぱっと見て d =2であることがわかります。進数の始まりはd+1ですので、私たちは3進数以上のものを考えていくことになります(d+1となるのは当然ですね。例えば10進数なら各桁は 9 までです。10が入ろうとすると繰り上がってしまいます)。
まずは、3進数ですね。その前に10進数がどうなっているか考えてみます。10進数って実はこんな感じでできているのです。

10のまとまりが何個ありますか?という感じですね。これは、よく聞く2進数でも、今回の3進数でも、10000進数でも同じです。そのため、3進数とみなした場合にはこんな感じになります。
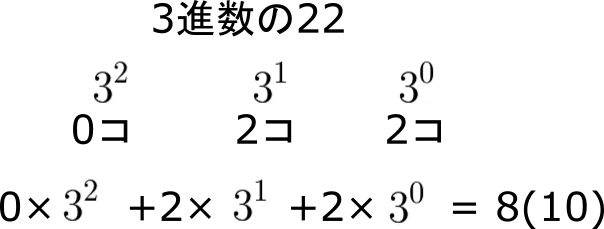
このとき、3進数を10進数に変換していることに注意です。逆じゃないです。
このようにすれば、ある数字(今回であれば22)を任意の進数で置き換えることが可能となります。また、ある数字が2桁以上(2つ以上の数字という方が正確かもしれません)であるときには、必ず1乗以上の項が出現します。そのため、2桁以上の数を n 進数で表したときの値は必ず n 以上となります(3進数で表したら、3どんなに小さくても3ですね)。
そのため、d+1進数から、m 進数までを全部進数変換して、m以下である個数を数えれば答えが出ます(m以下の個数と書きましたが、問題文で聞かれているのは、そのときの数(上の例だと 8 )の種類です。ただし、2桁以上であれば、進数が異なれば変換後の数も異なるので、求める答えと対応します)。
ただし、いつも通りですが制約を見てみると、1 <= m <= 10^18です。一つずつ見ていったら間に合いません。工夫をしましょう。
今回は、進数を増加させたときの値の変化を追ってみます。22の場合を列挙します。
進数 値
3 → 8
4 →10
5 →12
6 →14
この数字は永遠に大きくできます。どうやら進数を大きくすると値も増加するみたいですね。それもそのはずで、変換は進数 n の累乗の和で表されます。その n が増加すれば当然、変換後の値も大きくなりますね。
また、入力例1ではm = 10ですので、進数4ではOKなのに、進数5ではNGとなります。
単調増加する値において、ある値を境にOKとNGが変化する。そのような問題は、二分探索がとっても効果的です。二分探索の詳しい説明は別記事に任せますが、簡単に言うと、範囲の真ん中で hi or low をして、半分ずつ値を絞り込んでいく手法です。この手法により、n進数ではOKなのに、n+1進数ではNGとなる値を見つけます。

さて、次はOKかNGの判定方法についてもうちょっと詳しく見ていきます。先で述べたように、n 進数として変換した値が m 以下であればOK、m よりも大きい場合にNGとなります。なのですが、n 進数の変換について少々工夫しなければなりません。というのも、制約が大きいため、上の図や問題Cの復元のように、愚直にnの0乗、1乗とやっていくとオーバーフローの対処が大変です。
そのため、以下の進数変換の式を変形していきます。
1234(n)
=1 * n^3 + 2 * n^2 + 3 * n^1 + 4 * n^1 (10)
ここまでは、先ほどと一緒です。この n を分解します。
= n * ( n * (n *( n * (+1) + 2) + 3) +4) (10)
↓一つずつ書くとこのようになります
start:0
+1:1
*n:1*n
+2:1*n+2
*n:(1*n+2)*n = 1*n^2 + 2*n
+3:1*n^2 + 2*n+3
*n:(1*n^2 + 2*n+3)*n = 1*n^3 + 2*n^2 + 3*n
+4 : 1*n^3 + 2*n^2 + 3*n + 4
こうなります。これらの2式は同じ式です。ただし、下の式の何が良いのかといいますと、n^(なんとか乗) っていうのを管理しなくても良い点です。上の手法だと、n^(なんとか乗)もしくは変換してる値の両方のオーバーフローを監視する必要がありましたが、下の式だと、変換してる値だけに注意すれば良くなります。
これでスマートに進数変換できました。あとは値を絞り込むだけです。このとき、二分探索の開始点に注意しましょう。lower = d, upper > m+1です。upperはこれ以上大きくしても問題ないのですが、lowerを小さくすると進数はd+1以上という条件を破ってしまいます。また、d+1ではなくdです。lowerに設定された数値は成功が保証されてしまいます。m 以下になる進数が一つもない場合にlower = d+1としていると、二分探索ではd+1で成功するとみなされます。そのため、lower = dとし、upperがd+1まで降りてくるのを待ちましょう。
最後にコーナーケースについてです。上の方で、何回か「2桁以上の場合」と書きました。というのも、1桁の場合、1桁目は進数に関わらず書かれた数字が値に加算されるため、進数の影響を受けません。そのため、二分探索で解こうとすると答えが無限に出てきてしまいます。1桁の場合は別途if 文にてif(x.size() == 1)と分けましょう。x <= mなら1、x > mなら0です。
さて実装です。
#include<bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define reps(i,s,n) for(int i=s;i<n;++i)
using namespace std;
using ll = long long;
using P = pair<ll, ll>;
ll n2d(ll n,string x)
{
ll res = 0;
for(auto c: x)
{
if (res > 2e18 / n) return 2e18;
else res = n * res + (c - '0');
}
return res;
}
int main()
{
string x;
ll m;
cin >> x >> m;
//コーナーケース
if (x.size() == 1)
{
if (x[0] - '0' <= m) cout << 1 << endl;
else cout << 0 << endl;
return 0;
}
//最大値
int md = 0;
for (auto c : x) md = max(md,c-'0');
ll ac = md;
ll wa = 2e18;
while (wa - ac > 1)
{
ll wj = (wa + ac) / 2;
ll v = n2d(wj, x);
if (v <= m) ac = wj;
else wa = wj;
}
ll ans = ac - md;
cout << ans << endl;
return 0;
}何点か補足を。
まず、オーバーフローについてです。値が、2e18などの指定された値を超えたらbreakみたいな実装だとダメです。例えばですが、1e18が閾値で、今の値が1e10で次にかける値は1e11だとしましょう。この値を計算してしまうと、1e21ですね。
if(1e10 * 1e11 > 1e18) break;
long long型は大体9*10^18までですので、この時点で値がおかしくなります。そのため、判定の際には
if(1e10 > 1e18 / 1e11) break;
とする必要があります。
次に進数変換についてです。私ははじめは n^1, n^2, n^3のように累乗を増やしながら変換をしていました。ただし、そうするとオーバーフローのタイミングがうまく制御できませんでした。そのため、本記事のような実装を取りました。以下が該当箇所のコードとなります。正直どうしたらいいのかわかりません。ご教授いただきたいです。
ll res = 0;
ll w = 1;
int l = x.size();
rep(i, l)
{
char c = x[l-1-i];
//パターン1
//i == l-1の後にもう一回wをかけたもので判定
res += w * (c - '0');
if (w > 2e18 / n) return 2e18;
else w *= n;
//パターン2
//入力例3のようにxの桁数が多い場合、最終桁前にreturnする(要再考)
if (w > 2e18 / n) return 2e18;
res += w * (c - '0');
w *= n;
}最後に、オーバーフローするなら多倍長整数を使えばいいじゃないか、ということで、pythonで書きました。これが一番いいかもしれません。
x = int(input())
m = int(input())
if x <= 9:
if x <= m:
print(1)
else:
print(0)
exit()
def n2d(n):
tx = x
res = 0
w = 1
while(tx > 0):
res += (tx % 10) * w
tx = tx // 10
w *= n
return res
X = [x for x in list(str(x))]
md = int(max(X))
ac = md
wa = 2*10**18
while(wa-ac > 1):
wj = (wa+ac)//2
v = n2d(wj)
if v <= m:
ac = wj
else:
wa = wj
print(ac-md)E Train
n 個の都市が m 本の鉄道で結ばれています。鉄道は都市 ai と bi を結んでおり、時刻が ki の倍数のとき、両方の街から同時に出発し、ti 秒後に到着します。あなたは都市 x にいて、現在 0 時です。都市 y には最速でいつ到着するか求めます。ただし、着けないかもしれません。また、乗り換え時間は無視できます。
という問題です。結論から申し上げると、この問題は「ダイクストラ法+鉄道を待つ時間」といった感じで解くことができます。ということで、まずは簡単にダイクストラ法を説明します。
ダイクストラ法とは負の経路を含まないグラフの任意の2点間の最短距離(経路)を求めるアルゴリズムです。今回は距離だけですね。
いきなりですが、ここで一番大切なのは「負の経路を含まない」という点です。ここが、ダイクストラ法の肝です。なんで?っていう説明は後程します。そもそも、負の経路って何?って昔の私はなりました。例えばこんなのです。
勇者が街1から街10まで移動します。複数の道が用意されており、道i を通ると、疲労が xi たまります。ただし、ある道 j には回復アイテムが無限個置いてあり、この道を通ると、疲労が yj 回復します。
こんなやつです。この経路探索にはダイクストラ法は使えません。
ダイクストラ法が使える道を考えましょう。

これにします。私が今15秒で考えました。〇が街でーが道です。また、道に書いてある数字はコストです。全部0以上ですね。今回は街1から街6までの最短距離を求めてみましょう。
ダイクストラ法の初期状態は出発点の距離を 0 として、まだ到達していない街への距離をinfとします。

ピンクと緑の数字が街1からの距離です。ダイクストラ法のルールは
全ての街において一番距離(コスト)が小さいものから確定する
です。そのため、確定した0の色を緑に変えています。このルールにより最短距離が求まるのは紛れもなく、「負のコストを含まない」という点のおかげです。現在の最小値はどんな道を通ろうとも、そのコストは0以上のため、更新されようがないのです。
次に確定した街から行くことのできる街にお出かけします。

街2と街3にそれぞれ、5と3を書き込みました。これは、
街1に至るまでのコスト0 + 街1から街2 or 3までのコスト
が
今まで記録されていた距離(inf)
よりも小さいため値を更新しました。また、このとき、未確定の値のうち3が最も小さいので、コスト3を確定させました。今度は街3からです。

やることは先ほどと同様です。街3までの距離に街3から街2までのコスト(3+1=4)が記録されていた街2までの最短距離 5 を下回ったため、値を更新します。街5も同様に13と書きます。これで、4が確定しましたね。
という作業をすべての距離が確定するまで行います。あとは図をご覧ください。

こんな感じで、すべての街までの距離がわかりましたね。6までの距離最短距離は8です。
注意点としては探索をするのは、先に値が書き込まれた街ではなく、未確定のうち値が最も小さい街となります。街5の13から探索が進まなかったのが良い例ですね。
また、本グラフは双方向の道でしたが、一方通行の道(有向グラフ)でもダイクストラ法は適用できます。
以上がダイクストラ法のざっくりとした説明です。雰囲気をつかんでいただけたでしょうか?
次に実装方法です。ダイクストラ法を実装する際にはpriority_queueというデータ構造がよく用いられます。これは、名前の通りqueueの一種であり、queueの中身に優先度がついています。引数を何も指定しないと値の降順にソートされます。ダイクストラ法は「値が小さいものから」というルールがありますので、値を昇順に指定します。先頭のものを取り出してきて、、、とやるのですが、この辺はソースコードを見ながらの方が理解しやすいと思いますので、後回しにします。
さて、ようやく本問題に移ります。本問題では通常のコスト以外に、「鉄道の待ち時間」というものが存在します。裏を返せばそれだけです。通常のダイクストラ法では、「街2から街3まで移動」の際には「街1から街2までの距離」+「街2から街3までの距離」を「街3に書かれている値」と比較します。こちらの距離(コスト)に鉄道の待ち時間を含めてあげます。つまり「街1から街2までの時間」+「街2から街3までの移動時間」+「街2で街3までの鉄道を待つ時間」となります。距離が時間に代わってますが、コストという点で考えれば同じです。街3に到着した時のコストが、街3に到着した際の時刻になります。
あとは待ち時間を計算しましょう。まずは、具体例から。現在時刻が16分、電車が10分間隔で来るとしましょう。この場合、待ち時間は4分ですね。この4分を移動コストに足してあげます。
この 4分 の導出はこんな感じです。
10 - (16 % 10) = 4
ただし、この式だと時刻ぴったりの場合には待ち時間が10分になっちゃうので、10の場合には0としましょう。
これを文字で一般化すると
wait_time = k - (cost % k)
if (wait_time == k ) wait_time = 0
こんな感じです。引いてmod取ってみたいにやるともうちょっと綺麗になりそうですが、これで十分だと思います。
例1を図で示すとこんな感じ。

あとは、実装を見ながら補足します。
#include<bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define reps(i,s,n) for(int i=s;i<n;++i)
using namespace std;
using ll = long long;
using P = pair<ll, ll>;
const ll inf = 1e18;
int main()
{
int n, m, x, y;
cin >> n >> m >> x >> y;
--x, --y;
vector<vector<T>> edge(n, vector<T>());
rep(i, m)
{
ll a, b, t, k;
cin >> a >> b >> t >> k;
--a, --b;
edge[a].emplace_back(b, t, k);
edge[b].emplace_back(a, t, k);
}
vector<ll> d(n, inf);
priority_queue<P, vector<P>, greater<P>> pq;
d[x] = 0;
pq.emplace(0, x);
while (!pq.empty())
{
ll c = pq.top().first;
int s = pq.top().second;
pq.pop();
if (d[s] < c) continue;
for (auto a : edge[s])
{
ll gt = get<0>(a);
ll gc = get<1>(a);
ll gk = get<2>(a);
ll gw = gk - c % gk; // 待ち時間
if (gw == gk) gw = 0;
if (d[gt] <= d[s] + gc + gw) continue;
d[gt] = d[s] + gc + gw;
pq.emplace(d[gt], gt);
}
}
ll ans = d[y];
if (ans == inf) ans = -1;
cout << ans << endl;
return 0;
}まず、ダイクストラではpriority_queueをpairで指定して、<街 i までの暫定コスト、街 i>としてます。暫定コストの小さい順に探索が進みます。ここで、暫定としているのは priority_queueに投げて、まだ底の方に眠っているタイミングでその街の値が更新される可能性があるからです。その場合には、そこからの探索は意味を成しません。そのため、
if (d[s] < c) continue;
の部分でいわゆる枝刈りをしています。これをすると余分な探索が行われません。実は結構重要です。
繰り返しになりますが「その街までに到着した時刻」+「次の街への移動時間」+「鉄道の待ち時間」が「次の街に書き込まれてる時刻」より小さければその値を更新して、priority_queueに投げています。本当に通常のダイクストラとの違いは「鉄道の待ち時間」に集約されています。
あとはコストの値が大きいため、int では入りきりません。long longを使いましょう。
忘れてました。到着できない場合には値が更新されませんのでinfが書き込まれていると思います。その場合にはans = -1としましょう。
F Potion
n 種類ある素材のうち好きなものを調合してポーションを作ります。素材には魔力が定められており、はじめポーションの魔力は調合した素材の魔力の和です。調合の後、1秒ごとに調合した素材の数だけ魔力が増加します。さて、最も早く魔力を x ぴったりにできるのは何秒後ですか?
という問題です。
はじめはふんわりと考えましょう。イメージが大切です。まず、ぴったりかどうかは置いておいて、早く大きな魔力を手に入れるには、いっぱい調合するのが良さそうですね。ただこのときの「いっぱい調合する」という言葉には、2つの意味合いが含まれます。
まず、1点目は「初期魔力が高い」ことです。これは調合した素材の魔力の合計が高いとよさそうですね。2点目は「魔力の増加量が多い」ことです。似ているようで、少し違いますね。「魔力の増加量」は調合した素材の数によって決定されます。「魔力の合計値」は直接は関係ありません(だいぶ相関はありますが)。
目標魔力以上のポーションを作る問題はとっても簡単です。負の魔力の素材は存在しないため、全部の素材を入れましょう。そうすれば、「初期魔力が高い」かつ「魔力の増加量が多い」最強のポーションがすぐに作れます。「以上」の制約の下では、この2点は互いに最大ケースが一致することは直感で分かります。
ただし、本問題は「以上」ではなく「ピッタリ」です。この場合、全種類入れる最強調合だと、ピッタリを飛び越えてしまう恐れがあります。そうなると、話がややこしくなります。「初期魔力が高い」方がよいのか、はたまた「魔力の増加量が多い」方がよいのか。あっちを立てれば、こっちが立たないという感じです。困りました。
このように2つのパラメータが従属に変化してしまう問題を解く際には、
1つのパラメータを固定する
という手法を用いるのが典型です。今回はどちらにしましょう。「初期魔力」を固定するのは色々な組み合わせがあって難しそうなので、「魔力の増加量」の方を固定しましょう。魔力の増加量は先に述べた通り、「素材の数」で決まります。増加量は等しいので、最強のポーションとなりえるのは、「初期魔力」が最も高いものになります。ただし、その初期魔力から「ピッタリ」が実現できるものに限られますが。
以上より、少しだけ方針が定まりました。
k 個の素材を使用したとき際の初期魔力の最大値(ピッタリの実現)
をうまいこと使いましょう。魔力の増加量は k ですので、このとき魔力が x となるのにかかる時間は、初期魔力の最大値を s とすれば、
(x - s) / k
で表されます。ただし、
x % k = s % k
というピッタリの条件を満たしたものに限られます。この条件は「初期状態 s と終端状態 x は同じだけ k からはみ出てるから、kずつ増やすとちょうどいい感じに一致する」って感じです。私はそんなイメージをもってます。
あとは、この k を 1 から n まで回して、各 k で得られた時間の最小値をさらに比べましょう。その中で最も小さいものが答えになります。
これが、1つのパラメータを固定する方法です。高校の先生からは「地区大会のあとに全国大会をやる感じ」って言われました。当時はしっくりきてませんでしたが、言われてみればその通りですね。
ということで、ここからは k 個選ぶときの初期魔力の最大値を求めていきます。今回は動的計画法(Dynamic Programming : DP)を用いました。私の実装はC++であることにかまけて、工夫せず愚直に解いているので、他言語だと時間が厳しいかもしれません。その反面、基本的なDPに忠実ですので、理解はしやすいかな、と思います。
今回のDPの設計は次の通りです。
dp[ i ][ j ][ m ] :
現在 i 番目の素材を見ており
j 個の素材を既に使用している
k で割った際の余りが m である
ときの魔力の和
です。ここでいう「i 番目の素材を見ている」というのは、素材「ai」を入れよっかなー、やめよっかなーと考えている状態です。
入力例を使って具体的な遷移を見ていきましょう。
3 9999999999
3 6 8
ですね。k = 2の2個の素材を選ぶという状況にてdpの遷移を考えてみます。
まず、初期状態はdp[0][0][0] = 0ですね。一つも素材が入っていないのですから、余りも和も0です。それ以外を-inf とでもしておきましょう。
まず、一つ目の遷移です。3を入れるかどうか(採用するかどうか)を考えます。考えますといっても、DPなので採用する場合としない場合の両方を遷移させます。
3 を採用する場合
dp[1][1][1] = max(dp[1][1][1], dp[0][0][0]+3)
3を採用しない場合
dp[1][0][0] = max(dp[1][0][0], dp[0][0][0])
まずどちらの場合でも、素材a1の採用不採用の判断をしたので、i が増えましたね。次に採用した場合には j が増加し、しなかった場合には j がそのままです。最後に余りです。今回は遷移前の余り「0」と遷移後の余り「3」の和の余りは「3%2=1」ですので、上左辺の[ ]の3つ目も[1]となっています。2つの遷移式をもうちょっと詳しく書くと、
dp[0+1][0+1][(0+3) % 2]
= max(dp[0+1][0+1][0+1], dp[0][0][0]+3)
dp[0+1][0][0] = max(dp[0+1][0][0], dp[0][0][0])
ですね。a[0] = 3です。さて次の遷移に行きましょう。
6を採用するかどうかです。
6 を採用する場合
dp[2][2][1] = max(dp[2][2][1], dp[1][1][1]+6)
dp[2][1][0] = max(dp[2][1][0], dp[1][0][0]+6)
6を採用しない場合
dp[2][1][1] = max(dp[2][1][1], dp[1][1][1])
dp[2][0][0] = max(dp[2][0][0], dp[1][0][0])
こんな感じですかね。採用不採用ともに上が3を採用した状態で下が3を不採用の状態からの遷移ですね。あと、余りについても一つぐらいやっておきます。一番上の遷移式でdp[2][2][1]と余りが1ですね。これは、和が 3+6 = 9 ですので、9%2=1となって、その値が入っています。
さて最後です。8を採用するか悩みましょう。まあするのですが。
8を採用する場合
dp[3][3][1] = max(dp[3][3][1], dp[2][2][1]+8)
dp[3][2][0] = max(dp[3][2][0], dp[2][1][0]+8)
dp[3][2][1] = max(dp[3][2][1], dp[2][1][1]+8)
dp[3][1][0] = max(dp[3][1][0], dp[2][0][0]+8)
8を採用しない場合
dp[3][2][1] = max(dp[3][2][1], dp[2][2][1])
dp[3][1][0] = max(dp[3][1][0], dp[2][1][0])
dp[3][1][1] = max(dp[3][1][1], dp[2][1][1])
dp[3][0][0] = max(dp[3][0][0], dp[2][0][0])
こうやってみると、遷移自体は
採用する または 採用しない
の2種類しかないことがわかります。だいぶシンプルな問題にかみ砕くことができたのではないでしょうか。簡単な遷移図を載せておきます

これで、具体的な遷移の説明はおしまいです。
更新が終わったら、 k における最大値初期魔力を取得しましょう。ピッタリ x と重なるのは、x % k の余りを持つものなので、
dp[n][k][x%k]
が x にぴったり重なる最大初期魔力となります。あとはこの値から必要な時間を求めてあげましょう。すべての k について計算し、時間を比べましょう。その最小値が求める答えです。
長くなりましたが実装です。
#include<bits/stdc++.h>
#define rep(i,n) for(int i=0;i<n;++i)
#define reps(i,s,n) for(int i=s;i<n;++i)
using namespace std;
using ll = long long;
using P = pair<ll, ll>;
void chmax(ll & x, ll y) { x = max(x, y); };
ll dp[105][105][105];
int main()
{
int n;
ll x;
cin >> n >> x;
vector<int> a(n);
rep(i, n) cin >> a[i];
const ll inf = 1e18;
ll ans = inf;
//ki個調合する時を考える
for (int ki = 1; ki <= n; ++ki)
{
//初期化
rep(i, n + 1)rep(j, n + 1)rep(m, n+1) dp[i][j][m] = -inf;
dp[0][0][0] = 0;
//i番目の素材を見ている
for (int i = 0; i < n; ++i)
{
//現在 j個の素材を使っている(j <= ki かつ j <= i)
for (int j = 0; j <= ki; ++j)
{
//m 余るときの値
for (int m = 0; m < ki; ++m)
{
if (dp[i][j][m] == -inf) continue;
//a[i]の素材を選択しないとき
chmax(dp[i + 1][j][m], dp[i][j][m]);
//a[i]の素材を選択するとき(もし現在 j == ki)
chmax(dp[i + 1][j+1][m+a[i]) % ki], dp[i][j][m]+a[i]);
}
}
}
ll s = dp[n][ki][x % ki];
if (s != -inf) ans = min(ans, (x - s) / ki);
}
cout << ans << endl;
return 0;
}ここで大切なのが、
if (dp[i][j][m] == -inf) continue;です。解法は上記の方法で良いのですが、いざ実装となるとfor文を回す関係上、値が届いていない場所からの遷移が生じえます(入力例ですと、d[2][2][0]は取りえないのですが、for文ではここからの遷移が発生します)。そのため、if 文にて過去の遷移が届いていない場所(値が-infの場所)からの遷移は取り除く必要があります。気を付けましょう!
あとは、ここまで触れませんでしたが計算量ですね。プログラムを見るとfor文の4重ループですのでO(N^4)です。ただし、本問題では N<= 100と制約はかなり小さく、計算回数は10^8になります。また、1試行で行う処理は採用と不採用の遷移させるだけです。そのため、10^8でも計算が間に合ってくれます。
あとがき
昨日のコンテストの解答を翌日に挙げるというのはなかなかに大変でした。今、とっても眠いです。眠い中で、解けなかった問題を考えるのは修行でしたね。睡眠は大切です。身に染みてわかりました。
あと、特にD問題の数学チックな内容を要約しようとすると、実力不足を痛感させられます。なかなか読みやすい文章になりませんね。自分で理解したつもりでも、いざアウトプットしようとするとあやふやな部分が露呈します。問題を解く力だけでなく、考えを整理して、読みやすい、伝わりやすい文章を書く力も少しずつ向上してほしいなあ、と思いつつ、本記事を締めさせていただきます。
とても長かったですが、読んでいただきありがとうございました。ここまでお付き合いいただいてとても嬉しい限りです。
この記事が気に入ったらサポートをしてみませんか?