
スプレッドシートのIMPORTXML関数でWinActorのUserForumをスクレイピングしてみたハナシ
こちらの記事を参考にさせていただきました🙏✨
とてもわかりやすかったです。ありがとうございます!
【スクレイピング】IMPORTXML関数の使い方や具体的な使用方法を解説!
ホントはね…今 受講中のGAS中級講座の卒業LTでやるべく、「Parserライブラリ」を使ってみたかったのですよ。
でも このライブラリが使いこなせず、しかもスクレイピングしたかったサイトがGASやPythonでスクレイピングするのが難しいことがわかりまして…😭
検証をした結果UserForumなら実現できたので、学習メモとして残しておきます📒
(注意事項にスクレイピングについての記述は見つけられなかったですが、見逃していたら教えてください🙇♀️💦)
完成すると、こんな感じになります!

① Googleさんの説明によると
IMPORTXML関数のヘルプはこんな感じ。

要するに、URLとXPathさえ わかればOKなんです。すごいな、これ…😳
といいつつ、WinActorのブラウザ関連ライブラリでも使用するXPath…これがまた難しいんだ😂💦
② URLの指定(1ページ目)
今回は投稿日が新しいものから40件のスクレイピングをしてみます。
URLに設定するのは、UserForumのトップページの一番下にある「すべてをもっと見る」をクリックした後の、

このページ!

URLは
https://winactor.com/questions/?ap_sort=unanswered
です(*゚▽゚)ノ□ペタッ
③ XPathの指定
ここが大変なのです!XPathの指定!!
XPathは、右クリック→検証か、F12キーを押すと表示されるこの「デベロッパーツール」です。
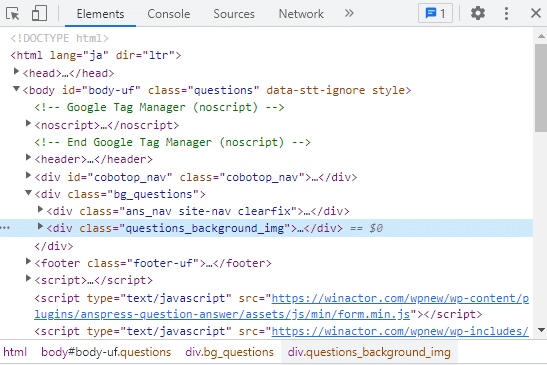
あーーーーー なんか いっぱい書いてある( ;つд⊂)ゴシゴシ
とりあえずタイトルのXPathを取得します。
タイトルで右クリックして、検証!

そうすると、右側のデベロッパーツールの該当箇所がアクティブになります。
この中で右クリックして、Copy→Copy XPath(。・Α・)σポチッ

すると、こんなものがクリップボードに入ります。
//*[@id="question-47076"]/div/div[3]/span/a
これをIMPORTXML関数の中のXPathの部分に貼る訳なのですが、関数の中ではXPathを "" で囲わないといけないため、"question-47076" のダブルクォーテーションを、'question-47076' とシングルクォーテーションに変更します。
こんな感じ。
=IMPORTXML("https://winactor.com/questions/?ap_sort=unanswered","//*[@id='question-47076']/div/div[3]/span/a")
すると「Loding…」という表示の後…

キタ――(゚∀゚)――!!
なのですが…
実はこれだと、このページにひとつしかない「id」の指定のため ひとつしか表示されないのです…😢
今回やりたいのは、「このページにあるタイトルをすべて取得」なので、idではない方法で指定する必要があります。
(HTMLの構造については詳しくないので、別途 有識者さまのサイトをご参照ください🙏💦)
なので今回は、このタイトルの文字装飾のために設定されている class というものを取得します!
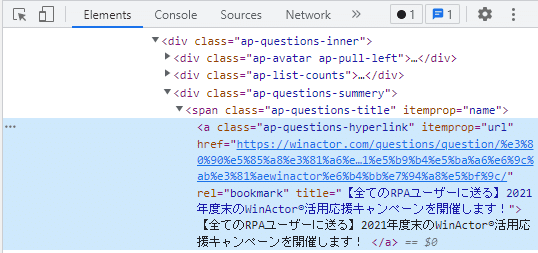
先ほどXPathをコピーしたときのように、デベロッパーツールのアクティブになっている部分で右クリック→Copy→Copy element します。

そうすると、こんなものがクリップボードに入ります。
<a class="ap-questions-hyperlink" itemprop="url" href="https://winactor.com/questions/question/%e3%80%90%e5%85%a8%e3%81%a6%e3%81%aerpa%e3%83%a6%e3%83%bc%e3%82%b6%e3%83%bc%e3%81%ab%e9%80%81%e3%82%8b%e3%80%912021%e5%b9%b4%e5%ba%a6%e6%9c%ab%e3%81%aewinactor%e6%b4%bb%e7%94%a8%e5%bf%9c/" rel="bookmark" title="【全てのRPAユーザーに送る】2021年度末のWinActor®活用応援キャンペーンを開催します!"> 【全てのRPAユーザーに送る】2021年度末のWinActor®活用応援キャンペーンを開催します! </a>
欲しいのは、これの一行目の a class="ap-questions-hyperlink" 部分。
これを使って、こんな感じで設定します。
=IMPORTXML("https://winactor.com/questions/?ap_sort=unanswered","//a[@class='ap-questions-hyperlink']")
再び Loding… (*´д`*)ドキドキ
からの~! ばばーーーーーん✨

一行目には関数が入っていて、2行目以下は値のみが入っています。
こんな感じで欲しい情報を右クリック→検証、デベロッパーツールで Copy element して、タグ(このときのa)と属性(このときのclass)と属性値(このときのap-questions-hyperlink)を設定していきます。
④ URLの指定(2ページ目)
2ページ目は1ページ目の一番下にある「2」か「次へ」を押した先のページです。
URLでいうと、
https://winactor.com/questions/page/2/?ap_sort=unanswered
これ。
RPAツールを使うときは、この「次へ」を指定して、指定したページ分 スクレイピングすることができるのですが、IMPORTXML関数だと どうなんですかね…?🤔
まぁ考えるより関数のURLを変更した方が早いので、私は21行目に こう設定しちゃいました!
=IMPORTXML("https://winactor.com/questions/page/2/?ap_sort=unanswered","//a[@class='ap-questions-hyperlink']")
サイトとしての作りは同じなので、URLの変更のみで大丈夫です🙆♀️
はいっ、これで完成🎊
今 一度、完成したものは こちら!!

⑤ 所感
まさか関数でスクレイピングできるなんて思いもしなかったので、びっくりです…!😳
スプレッドシートすごい!!👏✨
WinActorで XPath を扱う機会があるので抵抗感はなかったですが、Copy XPath でひとつしか情報が取れなかったときは あーーーー😱ってなりました🤣
ホントにやりたかったサイトのスクレイピングは IMPORTXML関数ではできなかったので、Power Automate for desktopを使用しました🤤
手軽に使える 関数・RPAツール、最高!🙌✨
事務員が少しの背伸びでできる効率化を目指す🌈✨ 自分の好きなものを、楽しく発信していきたいです! いただいたサポートは学習費にあてさせていただきます🥰