データからみる競輪予想印の見方その2:#機械学習 #競輪予想

#機械学習 #競輪予想
合同会社ムジンケイカクプロ、代表のムジンです。
前回>データからみる競輪予想印の見方その1:#機械学習 #競輪予想
競輪ファンの方、もしくは大量データ好きの方、分析好きの方、こんちわ。
私は競輪ファンではありませんが、分析の対象として競輪を選んだのは、鍛えた人間の生身の戦いというのが好きだからです。
(プロレスや格闘技が好き)
いい脚してるわー
元になるデータ
過去に行われた約42000レースのデータから読む傾向と題して、データを見ていこうと思います。
元データの集積方法
Pythonによるスクレイピング
1,DBへ、各月ごとの開催情報のURLをExcelで作って格納。
2,開催情報のURLから、レースごとのURLを一覧化し、DBへInsert
3,2で作ったURLから、HTMLをローカル保存。
4,ローカル保存したHTMLから必要部分をスクレイピング
予想と予測
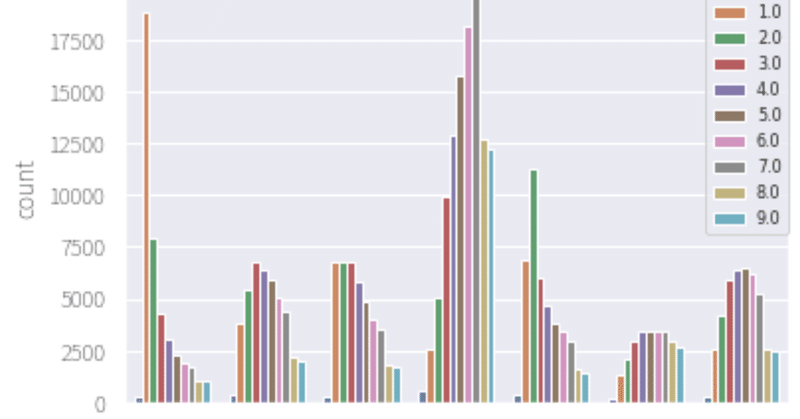
◎○×△▲の順で、ある程度着順が山なりになっていてくれるはずだ。という予想をしておりました。
本命◎の1着と、無印の7着からの5着以下の数値を見ると、ここはまぁそうだろうと。
×△▲ではどうか
数字ではなく、ビジュアルで見て感じたこと。
▲
5着を中心にバラける。
△
3着を中心にバラける
×
む?
こいつか犯人は。
予想印で起こること
予想印を見た人の心理が気になるのです。
予想印が良ければ、それを買うことに信頼性が生まれると。
買いやすい。
実際に1着になる確率も高そうだ。
(この時点では計算をしていない)
競輪は2着も当てなければならない。
○は◎の予想印に対して、かなり見劣りする信頼度に感じる。
棒が短い。
本命対抗でくるとして、予想印のもっともらしさ、正しさを出せばいいのかもしれない。
(尤度については、また後ほど)
この時点で、2着の○の信頼度は、1着の◎ほど高くないし見せかけだ。
心理的には買いたくなるが、よく考えるべきだ。
となっています。
順に紐解く
勝率くらいなんですよね。
いくつかその他、マイナスの相関がありますが、わかりやすいところだと勝率や連対率。
Pythonプログラムで相関関係図を出してみるとこんな感じ。
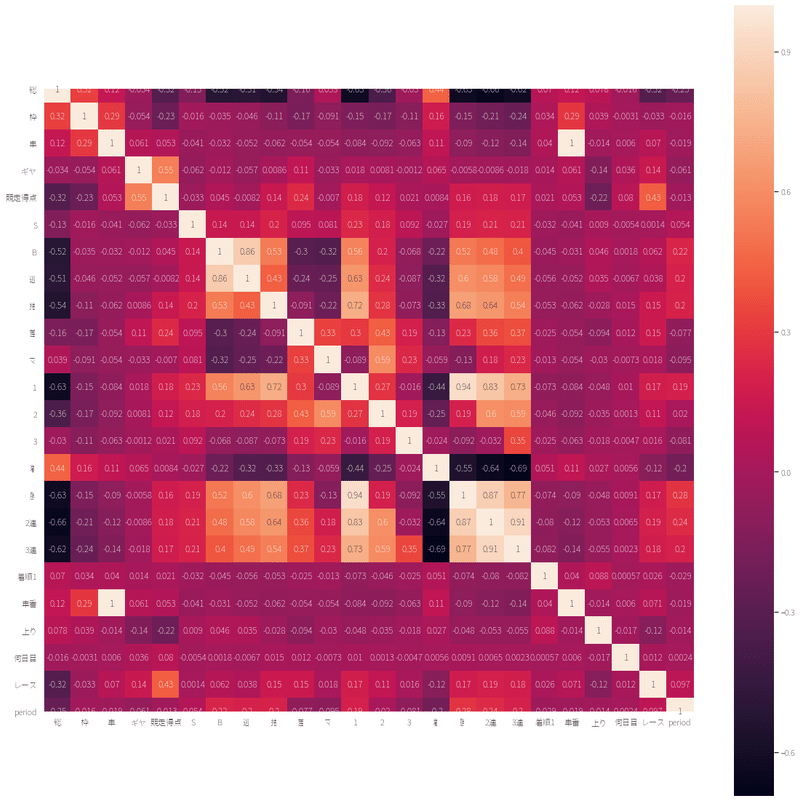
数値データをクリーニング(前処理をクリーニングと呼んでしまう癖)する前の段階で、着順に関係ありそうな数字は勝率。
適当な分析なので、以下の画像はカテゴリ値がありません。
カテゴリ値というのは、数字でないもの(予想印は数値ではなく文字)だと思ってください。
ヒートマップ出力のコード抜粋
df = df.drop(columns=['車番'])
df = pd.get_dummies(df,columns=['予'],drop_first=True)
df_xx = df[0:100]
corr = df.corr()
print(corr)
sns.heatmap(corr, square=True, annot=True)
plt.show()[予]が予想カラムの名前です。
ONE-HOTな形にして、数値にすることで、相関を出しています。
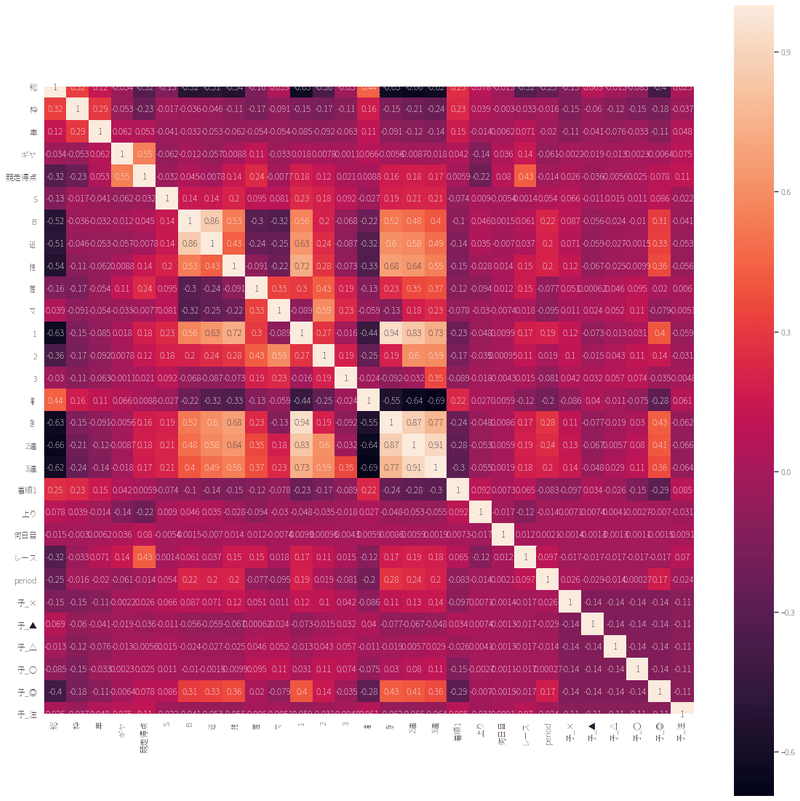
思ったほど、わかりやすく相関は出ないものの、◎の信頼度が○に比べて2倍近くあるということとして、目安にしようと思いました。
※大いに間違っているかもしれない。
予想印と着順の関係
この関係が崩れれば、オッズが上がると仮定しました。
着順が1着で、予想印が無印だったら配当が高いということにして、計算してみます。
1着 かつ 予想印が注以下のよくなかった選手
pr1 = df.query("着順1==1 & yosou_in < -2 ")10632回/42000レース
2着 かつ 予想印が注以下のよくなかった選手
pr2 = df.query("着順1==2 & yosou_in < -2 ")7131回
#2着以上で結果が穴
pr1 = df.query("着順1<=2 & yosou_in < -2")
19491
#3着以下で結果が穴
pr2 = df.query("着順1>=3 & yosou_in < -2")
9933
#2着以上で結果が順当
pr3 = df.query("着順1<=2 & yosou_in >= 0")
50628
#2着以上で結果が順当
pr4 = df.query("着順1<=2 & yosou_in == 0")
#3着以下で結果が順当
pr5 = df.query("着順1>=3 & yosou_in == 0")調べてみると
固いレースは、上位陣が潰し合うようなグレードの高いレース以外がそれに当たると仮定。
中穴くらいが出やすい条件がある。
選手が、風の影響を受けやすいレース場がある。
機械学習モデルの整備
レース場ごとにモデルを作るか検討。
レースのグレードごとにモデルを作るか検討。
開催何日目の開催か、も含む。
※競輪というのは、どうやら3日くらいかけて勝負しているようだ。
更に見てみる
既に素晴らしい分析を公開されている方が、ネット上に散見されますが、自分でやってみないことには理解できないのです。
#2着以上で、予想印より着順が良かった数
pr2 = df.query("着順1!=0 & 着順1<=2 & yosou_in > 1")
35079
#2着以上で結果が順当 予想印と着順が同じだった数
pr3 = df.query("着順1!=0 & 着順1<=2 & yosou_in == 0")
30079本命対抗以外の予想印で、1着2着になってしまったものが、35000回あります。
これは結構な確率。更に内訳。
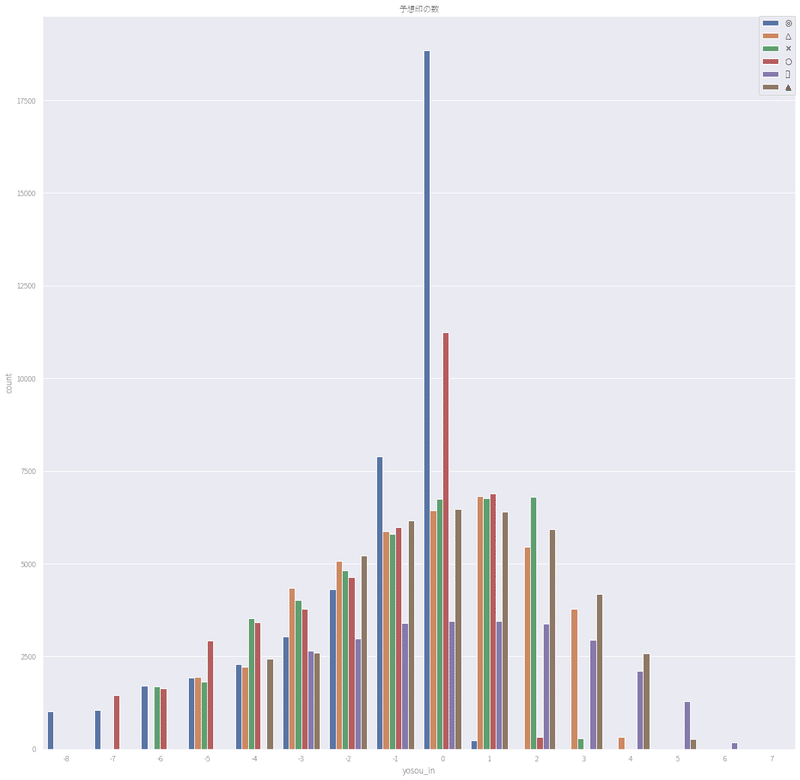
◎はそのまま1着になることが多い。
◎=1着=差が0で真ん中。
これが真ん中の青線。
左にずれると、着順が下がるので、◎は2着にもなりやすい。
赤いのが○で、○=2着=差が0で真ん中。
右に行くと着順が上がるので、1着になることも多い。
2着ほどではないにしろ。
なんだかここ重要な気がする。
✕ですね。これは問題。
緑がヤバイ気がする。
そのまま3着でくるより、上位になりやすい。
7車のレースでも9車のレースでも(この言い方はよくわからない)3着を中心にした上下は、+も-も均等になるはずだから、ここに偏りを見ることができる。
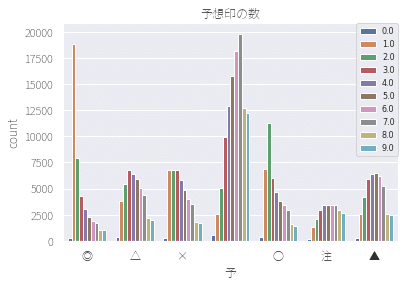
本紙予想は「◎○×△▲注」
デスク予想は「◎○×△▲」の順で強弱が表現されます。
Kドリームスさんより引用
これだな、ほとんどこれ。
✕が何着にいくか見極める。
これに注力しよう。
これは確率%とか出さなくても、全体的には、✕予想がついている選手は、そのまま3着でおとなしく終わらない!
という結論にしておこう。
いつもお読みいただき、ありがとうございます。 書くだけでなく読みたいので、コメント欄で記事名入れてもらうと見に行きます。