進化アルゴリズム vs 強化学習?

こんにちは。岡瑞起です。今日はALIFE研究の真骨頂「仮想生物」に関する実験を紹介したいと思います。
ALIFEの分野では、仮想生物の形や動きを人工的に進化させる研究が長年行われています。Karl Simsによる仮想生物の研究がその先駆けです。次の動画に表れるさまざまな形や動きの仮想生物が生み出されました。
Karl Simsの仮想生物が提案されたのは、今から約30年前の1994年のことです。その後もさまざまな仮想生物の研究が行われました。しかし、その多くは研究者が独自に開発した環境で実験が行われることが多く、アルゴリズムの性能を比較するのが困難でした。
そこで2021年になり、以前このnoteでも紹介した「Evolution Gym」というベンチマークのためのプラットフォームが提案されました。このベンチマークの登場によって、さまざまなアルゴリズムをシステマチックに比較することが可能となったのです。
仮想生物を進化させるという研究において、ターニングポイントとなったのはKenneth Stanleyらによって提案されたCPPN-NEATというアルゴリズムの登場です。詳細な説明はここでは省きますが、このアルゴリズムを用いて仮想生物の形を進化させると、幾何学的なパターンをコンパクトに表現されスムーズな動きを作ることが可能になりました。
次の動画は、Hod Lipsonによって2013年に提案されたCPPN-NEATを使って、その形を進化させた仮想生物たちです。1994年に提案されたKarl Simsの仮想生物よりも、より複雑で多様な振る舞いを作り出すことができるようになっています。
Evolution Gymを用いることで、上記のような仮想生物による実験を手軽に行えるようになりました。そうなると、自分たちでも試したくなりますよね。
そこで、昔から興味のあった「進化アルゴリズム」と「強化学習」の違いについて調べてみました。仮想生物の形を進化させるには、CPPN-NEATのような進化アルゴリズムが使われる事が多いのですが、動きの学習には強化学習が使われる方が多いです。
Evolution Gymでも仮想生物の動きを制御するニューラルネットワークの学習には、Proximal Policy Optimization(PPO)という強化学習手法が使われています。その理由は、1)進化アルゴリズムは計算に時間がかかること、2) 強化学習の方が進化アルゴリズムよりも良い精度が出ることが多いこと、が挙げられます。ですが、より複雑な動きが求められるタスクにはNEATやHyperNEATなどの進化アルゴリズムの方が強化学習よりもよい結果になる、という実験結果も報告されています。
そこで、Evolution Gymを使って実際に実験をして確かめてみました。
強化学習手法としてPPO、進化アルゴリズムとしてNEATとHyperNEATを使いさまざまなロボットの形態を使って実験し、精度の比較を行いました。
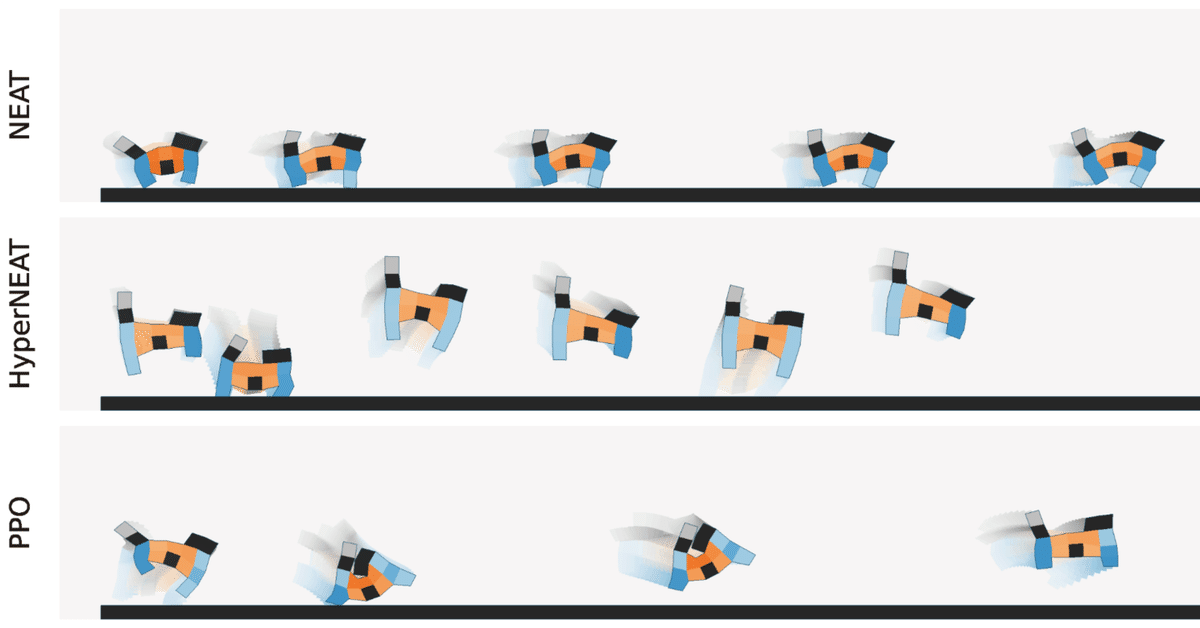
たとえば、真っ平らな環境で、できるだけ遠くまで行くというタスクに対して、猫のような形のロボットで学習させた結果は次のようになりました。学習アルゴリズムによって同じ仮想生物の形でもかなり違った動きをみせる点が面白いですね。このタスクの場合、一番遠くまで移動できているのはPPOです。



さまざまな仮想生物の形とタスクの実験を行ってみた結果、やはり強化学習(PPO)が多くのタスクにおいて良い精度を出すという結果になりました。ですが、タスクによっては進化アルゴリズムの方が得意なものも出てきました。
たとえば、次のようなブロックを投げるというタスクは、進化アルゴリズム(HyperNEAT)によって動くを学習させた方が、強化学習(PPO)よりも良い結果となりました。


ブロックを遠くに投げるためには瞬間的に大きなインパクトを与える必要があります。そのためには、ブロックを適切な位置に移動させることをまずは学習することが重要になります。HyperNEATの方がその動きを上手く学習できたようです。
段差や落とし穴のあるような地面でのタスクも、PPOよりもHyperNEATの方が上手く動きを学習できた例です(noteにgif画像を埋め込みできなかったので、Twitterに投稿したgif動画をここでは埋め込みました。)
PPOによる結果 pic.twitter.com/GeO0RCYOxK
— Mizuki Oka/岡瑞起 (@miz_oka) September 13, 2022
HyperNEATによる結果 pic.twitter.com/TKg6uGGBCY
— Mizuki Oka/岡瑞起 (@miz_oka) September 13, 2022
PPOはジャンプの学習に失敗しているため、段差の前で止まってしまっています。段差があるまでは、前に進むことに最適化することでより速く進むことができますが、段差を超えるためにはジャンプすることを学習しないといけません。PPOでその動きを学習するためには、おそらく精密なチューニングが必要になります。
一方、HyperNEATは、仮想生物の形を上手く生かして高いジャンプをするように学習しています。結果、段差もうまく超えて前に進むことができています。
ちなみに、この実験に使用したコードは研究室の斉藤拓己さん(博士課程)によって実装され、コードもGitHubで公開されています。ぜひダウンロードしてみなさんも手元で走らせてみてください。実験は、学部4年生の西村春輝さんにも手伝ってもらいました。
また、この実験は論文にもまとめ2022年12月にシンガポール&オンラインで開催されるIEEE ALIFEという国際会議で発表する予定です。論文が公開されたらまた共有したいと思いますので、技術的な詳細に興味がある人はぜひチェックしてみてください。
今回も最後まで読んでいただきありがとうございました。
見出し画像クレジット:斉藤拓己さんが作成した画像です。
この記事が気に入ったらサポートをしてみませんか?