深層学習とゲーム

今週の社内で開催しているAIセミナー(第130回)は、Deep Learning (深層学習)を取り上げた。
「Google DeepMind」が驚異的な速さで学習!人工知能への危機感も高まる
http://itpro.nikkeibp.co.jp/atcl/column/14/466140/012500025/
というのは、やや大袈裟だが、Deep Learning (DL、深層学習)は、
現代の人工知能のキーワードになっている。
DLとは、
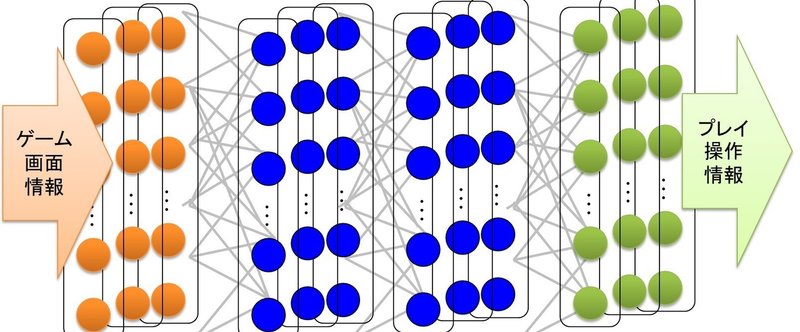
- 多層型ニューラルネットワーク(NN=neural networkは昔からあるが...)
- 階層的学習(それぞれの階層で学習して行く。2006年頃から)
- GPUとかで高速計算
という特徴を持つ。ある程度、何を学習するかまで、NNが学習できる。
例えば何万枚もの猫の画像から、階層型なので、スケールや部分を変えて学習できる。(耳とか目とか)
この技術を研究していた Deep Mind 社が Google に買収された。
この Deep Mind 社が、昨年、Atari2600 のゲーム(他にも実はやっていた)をAIに学習させてプレイする研究成果を論文として発表した。
Playing Atari with Deep Reinforcement Learning
http://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
これは、簡単に言うと、Deep Learning と Q学習という強化学習の手法を組み合わせたハイブリッド方法である。
強化学習というのは、AIがある環境の中にいて、その環境がどんな環境がモデル化できない時に、とりあえず行動してみて、その結果から手さぐりで、環境における最適な行動を見つけて行く、という手法だ。
結果というのは「報酬」と言い換えることができて、Q学習というのは、これをやって、これをやって、最後にうまく行ったときに、それまでの過程全体に報酬を分配する方法だ。正確には Q(s,a)と書いて、状態sの時にaという行動を選択する評価値を、いろいろ試行錯誤した結果から変えて行くのだ。
さて、この論文で環境とはゲームであるが、かなり荒っぽくゲームの画面そのものをNN に入力する。もちろん、毎フレームの必要はなくて、例えば Space Invader なら4フレーム毎の画面キャプチャーを取る。出力は、そのゲームでプレイヤーが取れる行動が一揃い出力ノードになっていて、もっとも出力の高いものをオンにする。報酬はスコアのアップ、ダウンを、おもいきって、1、0、-1にしてしまったものだ。
そうやって、このDL-NNを学習させると、結果としては、人間ほどはうまくならないが、これまでのAIよりずっと上手になる。何よりたいせつなことはDeep Learning のニューラルネットワークで、異なるゲームのAIを全部作れてしまったことだ。これまでのゲームのAIというのは、ゲームのルールに基づいて、囲碁なら囲碁のAI、将棋なら将棋のAI、あるRTSならRTSのAIというふうに、ゲームごとに異なるAIを作って来た。それが同じフレームの学習を変えるだけで作れるというのは、とても汎用性が高い。もちろんAtari2600の単純なアクションゲームを選んでいるのだけれど、
- ルールを覚えさせていない。
- 複数のゲームを同じフレームで作ってしまった(汎用人工知能、と言います)
というところが新しい。NNとQ学習は、メモリと計算リソースがかかるので、商用ゲームにはまだ早いが、現行クラウド上でも十分に機能する。
この汎用性こそが、社会に、ゲームに、拡散して行く可能性を持っている。
https://www.youtube.com/watch?v=EfGD2qveGdQ
この記事が気に入ったらサポートをしてみませんか?