
【3/18-3/24】生成AIツール/研究-Weeklyまとめ

今週のAIに関するツールや研究情報をまとめた記事です。
ツール
・画像電卓
image calculator pic.twitter.com/YTIuFBdRXs
— saint laurent del rey (@laurentdelrey) March 17, 2023
・Praktika:GPT駆動のAIアバターによる没入型語学学習アプリ
ChatGPTを搭載したAIスピーキングアバターと一緒に、楽しくインタラクティブな言語学習に取り組める。 いつでもどこでも、1000以上の会話ベースのレッスンと、すべての英語能力レベルに対応した100以上のトピック。 https://praktika.ai

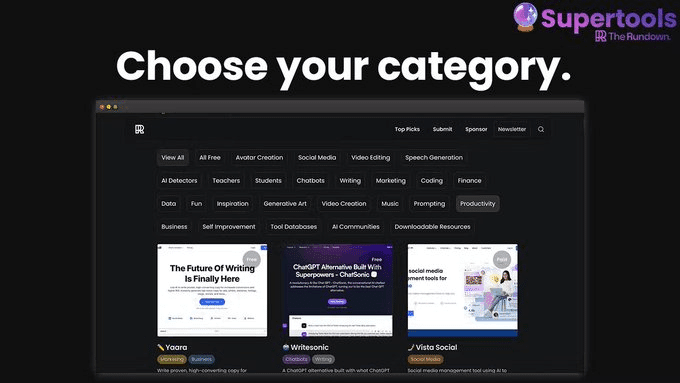
・Supertools:最高のAIツールを一挙に紹介
どんなタスクにも最適なAIツールを簡単に見つけることができる。 100%無料で、毎日更新。 こういうツール一覧系めちゃくちゃあるけど、結局producthuntを見てる。
https://supertools.therundown.ai
・OpenAIのkeyなしで誰でもGPT-4を使えるデモを公開してる人
https://twitter.com/akinoriosamura/status/1637436364592680963
・ChatGPT × Unity Editorだそう
別投稿で日本語でも動かしてた
https://github.com/keijiro/AICommand
I created a proof-of-concept integration of ChatGPT into Unity Editor. You can edit your Unity projects using natural language prompts. https://t.co/suLrE0tEEB pic.twitter.com/CnaD5zp744
— Keijiro Takahashi (@_kzr) March 19, 2023
・AIミュージックビデオを作成できるツールdecoherence
AIスタイルを選択し、エフェクトを設定し、開始画像を選び、プロンプトを使用して、作成
https://decoherence.co
https://twitter.com/akinoriosamura/status/1637640733606965249
・利用可能なAI動画生成モデル
・ツール12種 (元投稿に一部追記)
1. GEN-1
2. GEN-2
3. ModelScope
4. KaiberAI
5. LeiaPix
6. plazmapunk
7. decoherence
8. D_ID
9. Genmo
10. Tavus
11. flawless
12. Google ole' Stable Diffusion
スレッドに詳細
利用可能なAI動画生成モデル・ツール12種
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 21, 2023
(元投稿に一部追記)
1. GEN-1
2. GEN-2
3. ModelScope
4. KaiberAI
5. LeiaPix
6. plazmapunk
7. decoherence
8. D_ID
9. Genmo
10. Tavus
11. flawless
12. Google ole' Stable Diffusion
スレッドに詳細 https://t.co/w5QbsKS2sX
・事前登録1,000名超え! アイデアから仮説を生成する「Value Discovery」大型アップデート
🎉事前登録1,000名超え!
— しょーてぃー / UX Designer & Prompt Designer (@shoty_k2) March 20, 2023
アイデアから仮説を生成する「Value Discovery」大型アップデートしといたでぇ〜
◆GPT-4搭載! 鋭い仮説に出会える
◆無料でお試し可能
◆月額プランも登場
”AI時代に必要な仮説立案スピードを”
すぐに試したい人👇https://t.co/eqGfsJ6Eggpic.twitter.com/jLW9j9quyi https://t.co/9ZVc3J33GX
・Chrome拡張機能の「Superpower ChatGPT」
Chrome拡張機能の「Superpower ChatGPT」が超便利。過去履歴を一括削除できたり、エクスポートを色んな形式でやれたり、「続けて」をボタン一個でできる。Chrome/Firefoxユーザーは絶対に追加しておくべき👍
— いつもの匠@ガジェット研究家 | 3Dプリンタ大好きシステムエンジニア (@itsumonotakumi) February 28, 2023
Superpower ChatGPThttps://t.co/mThu9T88aY pic.twitter.com/4T5ZvHr1oJ
・Luma ARが発表
キャプチャした物体を現実に差し込んだりしてる。
http://lumalabs.ai/ios
https://twitter.com/LumaLabsAI/status/1638197756778156034
・AI家庭教師
・コミュニケーション力評価AIを搭載
コミュニケーション力評価AIを搭載しました!
— たむこう | ACES, Inc. (@7142857) March 23, 2023
商談解析AIツールACES Meet、声量・声の高さ・話速・ラリー数・発話割合・発話平均時間の分析が可能に https://t.co/X9qtexf6OH @PRTIMES_JPより pic.twitter.com/J8TwGhHNdv
・自分のコンテンツをYC、Sequoia、Asana、McKinseyなどによるテンプレートで変換してくれるそう
プロダクトマネジメントテンプレートや企業/戦略テンプレート、VCの企業分析テンプレートなどなど キーエンスの営業ナレッジの自動適用とかできんかな
https://wnr.ai

・Github Copilot for Docs
https://t.co/mTUt2i0kVS
— ぬ (@nkmry_) March 22, 2023
Github Copilot for Docs, コレが欲しかったんだよ感が半端ない!
ライブラリのメンテナーが書いた最新のドキュメントを元にチャットで聞ける。情報は Github の repo から直接持ってきてるから最新性と信頼性が高い。
ChatGPT だと 2021… pic.twitter.com/rbEn0uHzKj
・ノーコードサイト作成ツール「Studio」にもAIが搭載
遂にノーコードサイト作成ツール「Studio」にもAIが搭載される
— チャエン| Web3.0×海外テック×AI (@masahirochaen) March 23, 2023
・音声での複雑なサイト構築
・最適なデザイン案のレコメンド
・AIによる最適なレスポンシブ対応
StudioはオシャレなWebサイト制作向きで、それにAIが搭載されると質の高いサイトが量産されまくる…
サイト制作会社の未来が心配… pic.twitter.com/IGzbf0Dqdj
・Chuanhu ChatGPT
ChatGPTやGPT-4 APIのための軽量で使いやすいWebグラフィカルインターフェース
デモ: https://huggingface.co/spaces/JohnSmith9982/ChuanhuChatGPT…
github: https://github.com/GaiZhenbiao/ChuanhuChatGPT
Chuanhu ChatGPT🐯
— AK (@_akhaliq) March 23, 2023
Provides a light and easy-to-use web graphical interface for ChatGPT API@Gradio demo: https://t.co/Xjj1T91YKk
github: https://t.co/wQVTuQbBSK pic.twitter.com/efka1pz8gX
・ChatGPT for Me
過去の出来事をGPTに外部記憶させ呼び起こせる。 質問をすると、過去の最も関連性の高い瞬間のテキストが GPT-4 に送信され、回答が生成される。
waiting: https://rewind.ai/chatgpt-for-me


・Consensusが結果のサマリーを GPT-4で対応
研究
・言語モデル強化学習ライブラリのTRLの新しいリリース
1, 大きなモデルのサポート: ナイーブパイプラインの並列性を利用し100BスケールのモデルをRLHFできるように
2, PEFT+データ並列化: 学習並列化で、より多くのデータとGPUで学習できるように
詳細: https://github.com/lvwerra/trl/releases/tag/v0.4.1

・Google が 動画キャプションのための大規模な事前学習モデルであるVid2Seq をリリース
数百万本のナレーション付き動画を用いて事前学習 事前学習済みモデルを近日中に公開
プロジェクト: https://ai.googleblog.com/2023/03/vid2seq-pretrained-visual-language.html…
事前学習と下流タスク適応のためのコード: https://github.com/google-research/scenic/blob/main/scenic/projects/vid2seq/README.md
Google just released Vid2Seq!
— Lior⚡ (@AlphaSignalAI) March 17, 2023
It's a pretrained visual language model that can understand and describe multi-event videos.
The team augmented a LM with time tokens to predict event boundaries and textual descriptions in the same output sequence.
Paper: https://t.co/5ez6JiYFGz… pic.twitter.com/Q2MApAkrnT
・17億のパラメータのテキスト動画生成拡散モデル
学習データ: LAION5B、ImageNet、Webvid、およびその他の公開データセット
モデルに関して: https://modelscope.cn/models/damo/text-to-video-synthesis/summary…
モデルファイル(Apache2.0かな?): https://modelscope.cn/models/damo/text-to-video-synthesis/files

・昨日出た17億パラメータのオープンソーステキスト動画生成モデルのhuggingface
https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
🚨 BREAKING: You can now create amazing videos from text with the largest diffusion model ever open-sourced.
— Alvaro Cintas (@dr_cintas) March 19, 2023
Try it out here: https://t.co/gQeCShrEOI pic.twitter.com/ACqjqGshXF
・so-vits-svc のフォークでリアルタイム声質変換
・日本語を含む52Kの多言語データセット(mini ver)をリリースした方
GPT3.5 #ChatGPT スタイルのチャットデータセットで、データセット全体が150Kに到達。#Alpaca #Llama https://huggingface.co/datasets/JosephusCheung/GuanacoDataset

・大規模自然言語モデル LLAMA・GPT の比較
・Alpaca-loraを日本語タスクでファインチューニングする
・DS-Fusion: 芸術的なタイポグラフィー生成
入力された単語の意味を視覚的に伝えるために、1つまたは複数の文字フォントを様式化することによって、芸術的なタイポグラフィを自動生成 なんか、似たようなの前もあった?
論文: https://arxiv.org/abs/2303.09604
プロジェクト: https://ds-fusion.github.io
DS-Fusion: Artistic Typography via Discriminated and Stylized Diffusion
— AK (@_akhaliq) March 20, 2023
abs: https://t.co/K3b8HHo3OM
project page: https://t.co/Np9Cwok7zQ pic.twitter.com/sNSIcUedZ4
・CHAMPAGNE: 大規模な Web ビデオから実世界の会話を学ぶ
身振り手振りや顔の表情といった、これまでの会話モデルでは取れていなかった視覚的な文脈を考慮した会話の生成モデル
論文: https://arxiv.org/abs/2303.09713
プロジェクト: https://seungjuhan.me/champagne/
github: https://github.com/wade3han/champagne…

・Video-P2P: クロスアテンションコントロールによる動画編集
github: https://github.com/ShaoTengLiu/Video-P2P…
hf: https://huggingface.co/spaces/video-p2p-library/Video-P2P-Demo
Video-P2P: Video Editing with Cross-attention Control@Gradio demo is out on @huggingface
— AK (@_akhaliq) March 20, 2023
demo: https://t.co/dHHoiLh18v
github: https://t.co/vbq1MqwjXO pic.twitter.com/EYBCr9TkbK
・手元で動く軽量の大規模言語モデルを日本語でファインチューニングしてみました(Alpaca-LoRA)
・SKED: スケッチとテキストによる3D 編集
abs: https://arxiv.org/abs/2303.10735

・CLIP x 3D
ShapeNetCore v2、ModelNet、ScanObjectNNと3Dデータ詰め込んでる。
abs: https://arxiv.org/abs/2303.11313
プロジェクト: https://jeya-maria-jose.github.io/cg3d-web/
GitHub: https://github.com/deeptibhegde/CLIP-goes-3D…
お、ULIPに続いて、CLIPも3D統合が!
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 21, 2023
テキスト・画像・3Dの統合が進んで、テキスト3D生成等が進みそう
CLIP x 3D
ShapeNetCore v2、ModelNet、ScanObjectNNと3Dデータ詰め込んでる。
abs: https://t.co/yhhthbz9Jv
プロジェクト: https://t.co/LhpeITJxVl
GitHub: https://t.co/unj96OKQ17 https://t.co/Xoczy35Zov pic.twitter.com/yIytvarjRg
・Zero-1-to-3:ゼロショットで1枚画像から3Dオブジェクト変換
論文:https://arxiv.org/abs/2303.11328
プロジェクト: https://zero123.cs.columbia.edu github:https://github.com/cvlab-columbia/zero123…
デモ:http://huggingface.co/spaces/cvlab/zero123…


・中国企業「HUAWEI(ファーウェイ)」が1.085兆パラメータの言語モデル「PanGu-Σ」を発表
中国企業「HUAWEI(ファーウェイ)」が1.085兆パラメータの言語モデル「PanGu-Σ」を発表!(疎なモデル)
— 小猫遊りょう(たかにゃし・りょう) (@jaguring1) March 21, 2023
ゼロショットの設定で様々な中国語タスクで最高性能。現在、1兆パラメータを超えるモデル(疎なモデル)はSwitch-C、GLaM、 MoE-1.1T、悟道 2.0、M6-10Tなどがあるhttps://t.co/y9SBYiZDqa pic.twitter.com/aDIxMQlK1n
・長尺動画のエンドツーエンド生成モデリングに向けて
プロジェクト: https://sites.google.com/view/mebt-cvpr2023…
Github: coming soon

・Vertex AIで提供予定の生成AI機能を紹介した動画
Vertex AIで提供予定の生成AI機能を紹介した動画。PaLM等の豊富なLLM群から選べるModel Garden、プロンプト開発基盤を提供するGen AI Studio、画像生成できるVision AI Gen、モデルのEndpointへのデプロイ等。 #gcpja https://t.co/sWKrg3MrX0 pic.twitter.com/gFbzhRvR4d
— Kazunori Sato (@kazunori_279) March 20, 2023
・「Her」(!)という音声アシスタントを作っている人
gpt-3.5-turboと言語モデルチェーンを使いメールと会話して生産性向上を行える。音声は、文字通り映画 Her に合わせて微調整されており@ElevenLabsなどを検証。
「Her」(!)という音声アシスタントを作っている人
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 21, 2023
gpt-3.5-turboと言語モデルチェーンを使いメールと会話して生産性向上を行える。音声は、文字通り映画 Her に合わせて微調整されており、@ElevenLabsなどを検証。 https://t.co/ZCytK32uLN pic.twitter.com/WqaplX2cTe
・テキストテクスチャ生成:拡散モデルによるテキスト駆動型テクスチャ生成
論文:https://arxiv.org/abs/2303.11396
プロジェクト: https://daveredrum.github.io/Text2Tex/
Text2Tex: Text-driven Texture Synthesis via Diffusion Models
— AK (@_akhaliq) March 22, 2023
abs: https://t.co/acvUoQDn2E
project page: https://t.co/eAbpAKLMLk pic.twitter.com/lEvkGNiJ89
・Text2Room: テキスト画像生成モデルからの部屋のテクスチャ付き 3D メッシュの抽出
論文: https://arxiv.org/abs/2303.11989
プロジェクト: https://lukashoel.github.io/text-to-room/
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
— AK (@_akhaliq) March 22, 2023
abs: https://t.co/RJDk9APpQC
project page: https://t.co/zIf9dXE1aN pic.twitter.com/iDGgFdtgnx
・GPT-4を開発したOpenAI等がGPTが労働市場に与える影響を分析した論文:"GPTs are GPTs"
GPTはまさにGPTs(汎用技術; General Purpose Technogies)で影響は広範に及び,賃金水準によらず,むしろ高所得層が影響を受けることが示唆
https://arxiv.org/pdf/2303.10130/
GPT-4を開発したOpenAI等がGPTが労働市場に与える影響を分析した論文を公開しました
— 今井翔太 / Shota Imai@えるエル (@ImAI_Eruel) March 20, 2023
"GPTs are GPTs"https://t.co/5g3EE2NTgr
GPTはまさにGPTs(汎用技術; General Purpose Technogies)で影響は広範に及び,賃金水準によらず,むしろ高所得層が影響を受けることが示唆されてます pic.twitter.com/9KFqVyh0KX
・AlphaGOが出てから人の打つ碁のクオリティが加速度的に進化
AlphaGOが出てから人の打つ碁のクオリティが加速度的に進化しつつあるという、AIとヒトの共進化を示唆する報告。過去60年横ばいだった打ち筋の質が2016年以降急速に向上。しかもAIの打ち筋を単に覚えたのではなく、人が生み出した新しい打ち筋が増えている。https://t.co/0WZZBfV6LB pic.twitter.com/TwJ7pOriFy
— Kazuhisa Shibata (@kazuhi_s_) March 22, 2023
・Objaverse 3D生成を加速させる、100 万の注釈付きテキストペア3Dオブジェクトデータセット
hf: https://huggingface.co/datasets/allenai/objaverse…
論文: https://arxiv.org/abs/2212.08051
Introducing Objaverse, a massive open dataset of text-paired 3D objects!
— Matt Deitke (@mattdeitke) March 22, 2023
Nearly 1 million annotated 3D objects to pave the way to build incredible large-scale 3D generative models: 🧵👇
🤗 Hugging Face: https://t.co/bTWDd6JnIz
📝ArXiv: https://t.co/Qt1QirmGDN#CVPR2023 pic.twitter.com/FLH8JVx1ls
・Instruct-NeRF2NeRF: 命令による3D シーンの編集
1, 学習視点でのシーンから画像レンダリング
2, InstructPix2Pixでテキスト指示により編集
3, 学習データの画像を編集画像に置き換え
4, NeRFは通常通り学習
(イメージ動画はスレッド)
論文: https://arxiv.org/abs/2303.12789
詳細: https://instruct-nerf2nerf.github.io
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
— AK (@_akhaliq) March 23, 2023
abs: https://t.co/TE9W2ADnvp
project page: https://t.co/7LcuLJQ89K pic.twitter.com/A0133XoT0C
・Pix2Video:画像拡散を利用したテキストによるビデオ編集
添付動画は、他の手法との比較
プロジェクト: https://duyguceylan.github.io/pix2video.github.io/…
論文: https://arxiv.org/abs/2303.12688
githubとかはまだ
Pix2Video: Video Editing using Image Diffusion
— Aran Komatsuzaki (@arankomatsuzaki) March 23, 2023
proj: https://t.co/ERI62n9ipz
abs: https://t.co/79knRHUd3f pic.twitter.com/GjUSh7tNdC
・LAION-2Bの重複排除について
LAION-2Bの20億枚中の約7億枚が重複していたとのこと。
重複削除のデータはgithubにてダウンロード可能
論文: https://arxiv.org/abs/2303.12733
GitHub: https://github.com/ryanwebster90/snip-dedup…
検出された重複ペアのリスト(無作為抽出):https://docs.google.com/spreadsheets/d/1Eq46U3MbTXzNoLCvnHLcw64X3bWE3ZE8zMJVQU9_gCg/edit#gid=0


・研究者にとってのcode-davinci-002 の重要性を鑑みて、研究者アクセスプログラムで継続しているとのこと
https://openai.com/form/researcher-access-program…
また、ベースの GPT-4 モデルへのアクセスも研究者に提供している
・マイクロソフトが「GPT-4は汎用知能を獲得した」と主張
マイクロソフトが「GPT-4は汎用知能を獲得した」と主張。AGI(汎用人工知能)
— 小猫遊りょう(たかにゃし・りょう) (@jaguring1) March 23, 2023
へ大きな一歩。この論文では、初期のGPT-4の非マルチモーダル版(言語モデル)が、知能の多くの特徴を示している証拠を報告(1994年に52人の心理学者が行なった知能の定義に従っている)https://t.co/0bJbsJ5H1B
・RWKV(100%RNN)言語モデル搭載のChatRWKVというモデルらしい。apache2.0モデルで、@StabilityAI, @AiEleuther, @EMostaqueが計算資源を提供してる。intサポートしてて、しかも、日本語も通じた。
github: https://github.com/BlinkDL/ChatRWKV…
デモ: https://huggingface.co/spaces/BlinkDL/ChatRWKV-gradio

・Persistent Nature
3D世界モデルを維持しながら、任意の境界のない自然シーンを生成 ボクセル化したらマインクラフトや
論文: https://arxiv.org/abs/2303.13515
プロジェクト: https://chail.github.io/persistent-nature/…
Persistent Nature: A Generative Model of Unbounded 3D Worlds
— AK (@_akhaliq) March 24, 2023
abs: https://t.co/kwhyrIOGHm
project page: https://t.co/ABwVT9qV8h pic.twitter.com/8GdjxLDaX6
・教育用ビデオのステップ表現を学習するためのVideoTaskformer
タスク全体のビデオをコンテキストとして活用しながら、ステップ表現を学習。この学習されたステップ表現から、未知映像がタスクを正しく実行しているかを検証し、次に実行される可能性が高いステップを予測
論文: https://arxiv.org/abs/2303.13519
詳細: https://medhini.github.io/task_structure/

・ReBotNet:高速リアルタイム動画高画質化
ライブストリームやビデオ会議をリアルタイムで高画質化するために設計されたビデオアーキテクチャ
論文: https://arxiv.org/abs/2303.13504
プロジェクト: https://jeya-maria-jose.github.io/rebotnet-web/
ReBotNet: Fast Real-time Video Enhancement
— AK (@_akhaliq) March 24, 2023
abs: https://t.co/Mhmk2x49zH
project page: https://t.co/is9CW4Vu3J pic.twitter.com/ipF1neUv43
・GPT-4を医学能力試験とベンチマークで包括的に評価
-特殊なプロンプトなしで米国医師免許取得試験で20点以上の成績アップ
-学習データの暗記を示す証拠は見つからず
-医療データで調整したLLMを上回る(Flan-PaLM 540Bのプロンプトチューニング版Med-PaLM)
論文: https://arxiv.org/abs/2303.13375

・SINEってやつで、テキストやターゲット画像、あるいはそれらハイブリッドでNerf編集してる
論文: https://arxiv.org/abs/2303.13277
プロジェクト: https://zju3dv.github.io/sine/
SINE: Semantic-driven Image-based NeRF Editing with Prior-guided Editing Field
— AK (@_akhaliq) March 24, 2023
abs: https://t.co/RQpeJocBGF
project page: https://t.co/p5v8oJ1Ag4 pic.twitter.com/OOeY8eKiXs
・DreamBooth3D: テキスト3D生成
画像生成でもあったDreamBoothの3D版 対象の数枚の写真を入れるだけで、対象概念でのテキスト3D生成を可能に
論文: https://arxiv.org/abs/2303.13508
プロジェクト: https://dreambooth3d.github.io
DreamBooth3D: Subject-Driven Text-to-3D Generation
— AK (@_akhaliq) March 24, 2023
Personalized 3D models from just a few casual photos, with text-driven modifications
abs: https://t.co/H2TTmKDuSP
project page: https://t.co/rubuEZbYjo pic.twitter.com/DYPvJ9o3ON
・AIボットは人間レベルの創造性にまで昇華
-ボット: http://alpa.ai, http://Copy.ai, GPT3, 4, http://Studio.ai, YouChat
-それぞれのボットと100人の人間が出したアイディアを人間が (出所を知らないままで)評価したが違いなし
-ただ、人間の9.4%はほとんどのボットより創造的
・心の理論(ToM)が大規模言語モデル向上の 副産物で自然発生した可能性
#心の理論(ToM)が大規模言語モデル向上の
— forasteran (@forasteran) March 24, 2023
副産物で自然発生した可能性w
って草→Colabもある
GPT-4 🧑🎓95%のToM誤信念課題タスクを解決w
GPT-3.5 "davinci-003" 7歳児レベル🧒(90%)
InstructGPT "davinci-002" 6歳児に匹敵(70%)
GPT-3 "davinci-001" 3.5歳児と同等👶(40%)https://t.co/hxIWXcy3QK pic.twitter.com/87CFfiaONt
・マイクロソフトが作った動画AIのNUWA-XL
マイクロソフトが作った動画AIのNUWA-XLで、脚本を入力すると11分間のフリントストーンのアニメが一発出し!!すごすぎて頭がおかしなる~ →RT https://t.co/3p5ILs31W0
— うみゆき@AI研究 (@umiyuki_ai) March 24, 2023
この記事が気に入ったらサポートをしてみませんか?