
【4/17-4/21】生成AIツール/研究-Weeklyまとめ

今週のAIに関するツールや研究情報をまとめた記事です。
ツール
・BLIP2やSegment Anythingなどの情報をChatGPTに投げ込んでパラグラフを生成するimage2paragraphがHuggingFace Spaceで利用できるように
機能を組み合わせて価値を生み出すのも増えてきてる
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) April 17, 2023
BLIP2やSegment Anythingなどの情報をChatGPTに投げ込んでパラグラフを生成するimage2paragraphがHuggingFace Spaceで利用できるように
huggingface: https://t.co/6WjWshkl5Y
Github: https://t.co/rJqUdwdZCI pic.twitter.com/9RmfBS0uc9
・ChatGPTのUIUXを改善したTypingMindが、複数の会話を並行してできるように
他にも、
-自分のAPIキーを使用
-GPT3.5やGPT4を利用可能
-ログインの繰り返しがない
-検索機能
-プロンプトライブラリ
など
https://typingmind.com
You can now have multiple conversations with ChatGPT in parallel! 👀
— Tony Dinh 🎯 (@tdinh_me) April 17, 2023
No more wasting time waiting for the answer! 😁https://t.co/KHMQRr3sd2 is the only app that can do this on the market 💪
(as far as I know) pic.twitter.com/jdJ8j74uyI
・高性能で無料、誰の声にでもなりきれるAIボイチェン「RVC WebUI」がついに日本語表示に対応(CloseBox) | TechnoEdge テクノエッジ
・AWSのAI
Amazon Titan: ChatGPTライク
Stable Diffusion: 画像生成
Claude: 会話、Q&Aなど
Jurassic-2: 複数言語モデル
Amazon CodeWhisperer: コーディングアシスタント
・リッチ テキストを使用した表現力豊かなテキストから画像の生成がHuggingfaceで利用可能に
https://huggingface.co/spaces/songweig/rich-text-to-image
Expressive Text-to-Image Generation with Rich Text coming to our hub, integrated to @Gradio pic.twitter.com/36SbSXARtC
— Radamés Ajna (@radamar) April 17, 2023
・Adobeが画像生成AI Fireflyをビデオツールに導入予定
テキストでカラーグレーディングなどの動画編集、カスタムサウンドや音楽の生成、字幕やロゴ、タイトルカードなどの作成も また、スクリプトからストーリー、ひいてはプリビジュアライゼーションの自動生成も計画中
Adobeが画像生成AI Fireflyをビデオツールに導入予定
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) April 18, 2023
テキストでカラーグレーディングなどの動画編集、カスタムサウンドや音楽の生成、字幕やロゴ、タイトルカードなどの作成も
また、スクリプトからストーリー、ひいてはプリビジュアライゼーションの自動生成も計画中https://t.co/d9Bp8yaM4t pic.twitter.com/30qmUh3Jyh
・InVideo AIからテキスト動画生成が、来週アーリーアクセスリリース
waiting list: http://bit.ly/3olgW9b
InVideo AI - The Future of Video Creation is ALMOST HERE! 🚀💡
— InVideo (@InVideoOfficial) April 17, 2023
Limited early access releases next week!
Secure your spot on the waitlist NOW!
👉 https://t.co/lxgerCCasM#InVideoAI #VideoEditing #AIvideo #AItools #AIContent pic.twitter.com/p2SHgy4GX7
・AI面接官サービス
ChatGPTを使って、AIと面接練習ができるサービスを作りました!就活中の方、転職中の方にぜひ試していただきたいです!PCから無料で利用できます。https://t.co/ii5bAcYDIg pic.twitter.com/iycJPUpwAP
— Ryohei Igushi (@ryoheiigushi) April 18, 2023
・Adobe Lightroomの最新機能
-被写体の服や顔の毛を自動選択し、色や質感を素早く調整できるオプション
-「髭を暗くする」「ポートレートに磨きをかける」「服を強調する」の3種類のプリセット -「デジタルノイズ」を除去するDeNoiseツールも
https://www.theverge.com/2023/4/18/23687862/adobe-lightroom-update-adaptive-presets-beard-ai-features


・US版メルカリ、ChatGPTを活用した新しいお買い物アシスタント
「Merchat AI」の提供を開始 出品されている何百万もの商品を数秒でくまなく調べ、チャットで入力された要望に基づいておすすめの商品をリアルタイムで表示
MerchatAI: http://mercari.com/merchat
ブログ: https://about.mercari.com/press/news/articles/20230419_merchat/
US版メルカリ、ChatGPTを活用した新しいお買い物アシスタント「Merchat AI」の提供を開始
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) April 19, 2023
出品されている何百万もの商品を数秒でくまなく調べ、チャットで入力された要望に基づいておすすめの商品をリアルタイムで表示
MerchatAI: https://t.co/ySlCoooo9K
ブログ: https://t.co/OeWBfanMdx pic.twitter.com/SxBnAMOcNi
・AutoGPTがHuggingfaceで試せるように
使い方
-このスペースを複製(複製しないと動作しない! )
-OpenAI API Keyを入力
-値を入力し、「開始」をクリック
-ひたすらYes
https://huggingface.co/spaces/aliabid94/AutoGPT

・Snap は、「My AI」チャットボットを Snapchat の 7 億 5000 万人の月間ユーザー全員にも無料でリリース
グループ チャットに追加され、AR フィルターなどを推奨する機能が追加され、まもなく Snapchat 内で写真を生成することもできるように
https://www.theverge.com/2023/4/19/23688913/snapchat-my-ai-chatbot-release-open-ai


・Snapchat、ジェネレーティブAIを搭載したARレンズの提供を開始、まずは「Cosmic Lens」を新設
「Cosmic Lens」は、没入感のあるSFアニメーションのシーンに変えることが可能
・大規模言語モデル x 視覚情報のMiniGPT-4のデモ
https://huggingface.co/spaces/Vision-CAIR/minigpt4
MiniGPT-4 web ui 🚨
— AK (@_akhaliq) April 20, 2023
Enhancing Vision-language Understanding with Advanced Large Language Models now supports a @Gradio web ui hosted on @huggingface Spaces
demo: https://t.co/gW6YoQzjAn pic.twitter.com/7xqiSRgqam
・GPT含む複数AIモデルを利用・比較
GPT含む複数AIモデルが利用・比較出来て、プログラムコードが複数言語用に即コピーできるとんでもないサイトが公開!
— 元木大介@AI社長 (@ai_syacho) April 19, 2023
しかも無料!これはもう使うしか無いですね🙌https://t.co/VXYKhWZCka pic.twitter.com/Gz7zGNxytR
研究
・CyberAgent より、画像生成タスクにおける新たな評価指標の提案
・Web LLM Web
Web LLM
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) April 17, 2023
Web Stable Diffusionと同じチームによる、ChromeのWebGPU APIを利用して、ブラウザ上でvicuna-7b-delta-v0モデルを実行するプロジェクト
ブログ:https://t.co/finXvY2Ac9
github:https://t.co/oC6WHnsgS6
デモ:https://t.co/YeokpgQvpc https://t.co/82NCB4BsM4 pic.twitter.com/qS2lNKTRQ5
・OpenAI APIのファインチューニングの学習データのガイドライン
・マルチモーダル C4コーパス
43Bの英語のトークンと585M の画像を含む103Mのドキュメント
https://github.com/allenai/mmc4

・テキスト生成のAUTOMATIC1111/stable-diffusion-webui
Alpaca 以降コミュニティによって構築されたチャット AI約 12 個すべてのためのオープンソース Web UI
https://github.com/oobabooga/text-generation-webui

・Inpaint Anything: 何でもセグメント化して画像修復
論文: https://arxiv.org/abs/2304.06790
github: https://github.com/geekyutao/Inpaint-Anything


・ChatGPT+VITS+Live2DのChatWaifu…のさらにスマホ版
ChatGPT+VITS+Live2DのChatWaifu…のさらにスマホ版らしい…
— 高杉 光一🦋 @14:59 (@kuronagirai) April 16, 2023
もう中国の技術ツリーに関しては全くと言っていいほど追えてない…https://t.co/86c3n9a7I0
・落合さんのLLM論文紹介
落合さんのLLM論文(https://t.co/zjG5tgSmNz)読んでみた。これは画期的だね。この研究では、GPT-4にThree.jsのソースコードを書かせて、”猫”や”ルンバ”を実装させた。そうしたら猫はルンバを追いかけたりジャンプしたりするし、ルンバは掃除をしてて、猫にぶつかりそうになったら避けたり、あるいは… pic.twitter.com/zsizn12BH7
— うみゆき@AI研究 (@umiyuki_ai) April 17, 2023
・LangChainアプリをJina AI
Cloud上に数秒でデプロイするlangchain-serveで、 Jina AI Cloudにbabyagiをワンコマンドデプロイ
・商用利用可なオープンなRedPajama
#RedPajama→OSS版LLaMAみたいなの来る♪
— forasteran (@forasteran) April 17, 2023
商用利用可なオープンなの
🦙1.2兆トークンの完全open dataset
🤗RedPajama-Data-1Tで公開済
🦙redpajama base modelRLHF
(今後数週間で公開)70億パラくらい?
🦙instruction追加学習モデル予定
(OpenChatKit数十万規模でRLHF)https://t.co/tDd31DJDGS pic.twitter.com/WhhiG2dYt0
・DINOv2
画像レベルの視覚タスク(画像分類、インスタンス検索、ビデオ理解)とピクセルレベルの視覚タスク(深度推定、セマンティックセグメンテーション)に適した普遍的な特徴を抽出
1億4,200万枚の画像からなるデータセットを利用
商用は不可
https://dinov2.metademolab.com
https://github.com/facebookresearch/dinov2
DINOv2
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) April 18, 2023
画像レベルの視覚タスク(画像分類、インスタンス検索、ビデオ理解)とピクセルレベルの視覚タスク(深度推定、セマンティックセグメンテーション)に適した普遍的な特徴を抽出
1億4,200万枚の画像からなるデータセットを利用
商用は不可https://t.co/sCWgrWChEghttps://t.co/YkM2GyGl9G pic.twitter.com/WOKJzb7AlU
・冷蔵庫 x 物体検出 x ChatGPTで、残りモノからのレシピ生成
個人的には、自動生成じゃなくていいから、クックパッドとかクラシルレシピの方がオススメしてほしい
冷蔵庫の中身から料理レシピを考えてくれるAI ChatGPTを利用 米国チームが開発 https://t.co/GIXlerksL1 冷蔵庫の中を撮影した画像から食材を検出しChatGPTが料理を決め,その材料や分量,作り方を文章で出力。レシピ動画生成の未来も。カロリーや糖質制限,ヴィーガン食,おもてなし料理等も可能。 pic.twitter.com/JwwmaUoqWL
— Seamless (@shiropen2) April 18, 2023
・GPT-4以上? 自分で何度も“推敲”し完成度を上げる言語生成AI「Self-Refine」
・50億バラメーターの大規模言語モデルCamel
ラクダさんのLLM笑
— forasteran (@forasteran) April 17, 2023
動物流行りだね🤭
Camel 🐪 5Bは、50億バラメーターの大規模言語モデル。言語学者ら専門ライター監修70kデータセットで学習されてる?
チャットUIhttps://t.co/JKl75Od87u
モデル
🤗https://t.co/E2cRGGZUVEhttps://t.co/XDXBU6HWos pic.twitter.com/hE0hZiGtG7
・databricks-69k-ja-en-translation
Dollyデータセットとこれを日本語翻訳した時のデータを活用して、オリジナルにはない69Kの翻訳タスクデータセットを作成しました!これをいい塩梅で日本語Dollyデータセットに加えれば翻訳タスクもこなせるLLMが作れると思います。
— クニえもん.inc🤗 (@kun1em0n) April 18, 2023
databricks-69k-ja-en-translationhttps://t.co/w1b4siYRJK pic.twitter.com/07IqXLyOpv
・【前編】LangChainによるGenerative Agents実装まとめ
・【後編】LangChainによるGenerative Agents実装まとめ
・Gisting
入力プロンプトを最大26倍圧縮できるGistingって技術だって。どういうこっちゃ?というと例えば「以下の内容をフランス語に翻訳してください」ってプロンプトがあるとして「アレやって」だけで通じるように微調整、蒸留するイメージ。これでプロンプト圧縮できて推論速度上がって計算量も節約できる…
— うみゆき@AI研究 (@umiyuki_ai) April 18, 2023
・拡散モデル生成データで学習したら分類精度向上したらしい
Synthetic Data from Diffusion Models Improves ImageNet Classification
— AK (@_akhaliq) April 18, 2023
abs: https://t.co/6SCrDrUnzH pic.twitter.com/TBDt3toMuQ
・NVIDIA Omniverse と Replicator を使用しての合成データの生成→モデル微調整に関するブログ投稿
・Llama Lab:LlamaIndexを使った最先端のプロジェクトを構築するための専用レポ
・画像チャットのLLaVA
今度はラバw
— forasteran (@forasteran) April 18, 2023
(英語ではmuleなので日本でしか通じん🤭)#LLaVA (Large Language-and-Vision Assistant)
🐴https://t.co/oJH9QIQoIu
お試し→驚きの説明力w
LLaVAは事前学習済のCLIP ViT-L/14とLLaMAをくっつけて、CC3Mで調整しチャット化も学んでマルチモーダル化した奴https://t.co/USmllfK4P3 pic.twitter.com/GAfk9hiieB
・AI専門家の次は、AIチームを作るデモ
MultiGPT タスクと予算を設定すると、専門家のチーム(複数のexpertGPT)を作り、支援する
https://github.com/rumpfmax/Multi-GPT
詳細はスレッドに続く
AI専門家の次は、AIチームを作るデモ
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) April 18, 2023
MultiGPT
タスクと予算を設定すると、専門家のチーム(複数のexpertGPT)を作り、支援する
詳細はスレッドに続く
github: https://t.co/l4HGbDwlJZ https://t.co/WMWNlKk20T pic.twitter.com/FXzuatupLX
・iPhoneのヘルスケアデータを連動して、対話するHealthGPT
HealthGPT
— しょーてぃー / Experience Designer & Prompt Designer (@shoty_k2) April 18, 2023
iPhoneのヘルスケアデータを連動して、対話することができる。pic.twitter.com/f8z1N3j4Xb
開発者が書いていた例でいうと
- 「足が攣っています。これは何が原因でしょうか?」
-… https://t.co/Ppg7xIy9lc
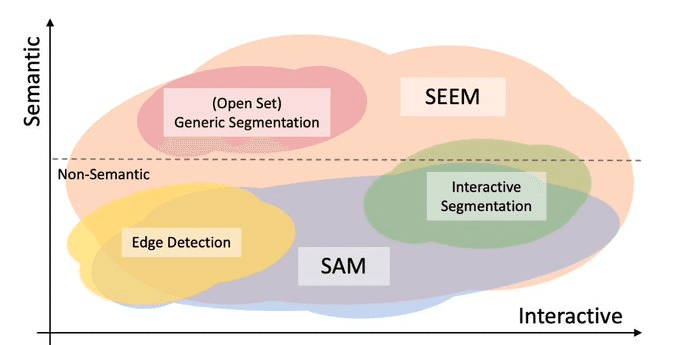
・Segment Everything Everywhere All at Once のhuggingface demo
ちなみにSEEMは、視覚的プロンプト(ボックス、走り書きなど)、言語プロンプト(テキスト、オーディオ)など、様々なプロンプトでセグメンテーションできるモノ
SAMとの違いは意味を踏まえられることらしい
https://huggingface.co/spaces/xdecoder/SEEM

・MetaAIより Avatars Grow Legs: 拡散モデルを使用しての滑らかな人間の動き生成
Githubなぜか開けない
論文: https://arxiv.org/abs/2304.08577
プロジェクト: https://dulucas.github.io/agrol/
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model
— AK (@_akhaliq) April 19, 2023
abs: https://t.co/7PukJpWw2V
project page: https://t.co/q5NzKS9us5 pic.twitter.com/eLaH6SB4Tx
・Text2Performer: テキストによる人物動画生成
合成された人間の外観を維持しながら、動作を行う動画生成研究 ファッション系とかへの応用が期待されそう
プロジェクト: https://yumingj.github.io/projects/Text2Performer.html…
github(モデルやコードは無い): https://github.com/yumingj/Text2Performer…
論文: https://arxiv.org/abs/2304.08483
Text2Performer: Text-Driven Human Video Generation
— Aran Komatsuzaki (@arankomatsuzaki) April 19, 2023
proj: https://t.co/cFIDp3D22i
repo: https://t.co/fIGMupeNTc
abs: https://t.co/SPfhwNBJl3 pic.twitter.com/ZU2OC704FF
・Video LDMs: 潜在拡散モデルによる最大解像度1280×2048の高解像度のテキスト動画生成
DreamBoothを組み込むことで、パーソナライズされた動画も生成可能(スレッドに)
プロジェクト: https://research.nvidia.com/labs/toronto-ai/VideoLDM/
論文: http://arxiv.org/abs/2304.08818
Video LDMs: 潜在拡散モデルによる最大解像度1280×2048の高解像度のテキスト動画生成
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) April 19, 2023
DreamBoothを組み込むことで、パーソナライズされた動画も生成可能(スレッドに)
プロジェクト: https://t.co/WrUfU07Vq7
論文: https://t.co/yRbxprvscF https://t.co/RIT2o1HarG pic.twitter.com/uAjFR6wk8x
・LLaMA-7Bのモデル、Guanaco
-複数言語 -システムプロンプトによる正確な外部知識の統合
-マルチターン対話
-ChatGPT API的ロール対応(システム、アシスタント、ユーザー)
・開発に使える?ChatGPTとプロンプトエンジニアリング
・株式会社松尾研究所のリサーチャーの方のAI系の研究・開発に関する情報収集元
・LangchainでAutoGPT
langchainで、AutoGPTプロンプト+AgentExecutorを実装(モデル、ベクターストア、ツールなど)
・StableLM:Stability AI 言語モデル!!!
-3Bと7BのStableLM-alphaモデルがリリース!
-15B、30B、65B、175Bのモデルも公開予定!
-しかも、ベースモデルはCC BY-SA-4.0、Fine-tunedモデルは非商用
-最大1.5兆個のトークンで学習
-コンテキスト長は4096トークン
huggingface: https://huggingface.co/spaces/stabilityai/stablelm-tuned-alpha-chat
github: https://github.com/stability-AI/stableLM/

・RVC向け学習済みボイスモデルデータをMITライセンスで無料配布
・MaskFreeVIS
ビデオまたは画像マスクのアノテーションなしで、正確なビデオインスタンスセグメンテーションを取得可能
詳細:http://vis.xyz/pub/maskfreevis
github:https://github.com/SysCV/MaskFreeVIS
論文:https://arxiv.org/abs/2303.15904
Segment Anything is fun and powerful but still requires full mask annotation for supervised training. Our new work MaskFreeVIS appearing at #CVPR2023 shows we can get accurate video instance segmentation WITHOUT any video or image mask annotations. More at https://t.co/PrzzPqBUFk pic.twitter.com/hhea2nniWC
— Fisher Yu (@DrFisherYu) April 19, 2023
・UEマケプレにOpenAIのAPIを叩ける無料プラグイン
・某国のChatGPT禁止でどれだけ生産性に影響があったをGitHubへのコミット量で調べてみたという論文。
某国のChatGPT禁止でどれだけ生産性に影響があったをGitHubへのコミット量で調べてみたという論文。
— mah_lab / Masahiro Nishimi (@mah_lab) April 20, 2023
・禁止令後の最初の二日間でアウトプットが約50%減少
・その後の影響は見出せなかった
・禁止令後のVPN検索が約52ポイント増加
みんなVPN使って事なきを得たってことか。https://t.co/tTmtS07jQE
・Microsoftがわずか数秒のサンプルから会話や歌声を再現できる音声合成AI「NaturalSpeech 2」を発表
・WALDO v1.0: ドローン / 地球観測衛星 / 飛行船などからの物体の頭上検出のための FOSS 事前学習済みモデル
github:https://github.com/stephansturges/WALDO
Releasing WALDO v1.0: a FOSS pre-trained AI system for overhead detection of stuff from drones / earth observation satellites / blimps etc !!!!
— uɐɥdǝʇS (𓂀,𓂀) (@StephanSturges) April 20, 2023
🚀🚁 🛩 🛫 🛬 🚀 ⚛ 🤖 🛰 📡
Code / weights ->https://t.co/bZAcsuXzNI
Lots more to come in the repository very soon! pic.twitter.com/1KMqpS1sZe
・NeRFの参照ガイド付き制御可能な修復
めちゃくちゃ綺麗に消せてるなー
論文: https://arxiv.org/abs/2304.09677
プロジェクト: https://ashmrz.github.io/reference-guided-3d/
Reference-guided Controllable Inpainting of Neural Radiance Fields
— AK (@_akhaliq) April 20, 2023
abs: https://t.co/PARwN7TsKU
project page: https://t.co/3jO4swxIK9 pic.twitter.com/r6RH0z1mnv
・構造認識拡散モデルによるスケッチを使用した参照ベース画像合成
服着せ替えたり、翼生やしたり、背景変えたりと、結構雑なマスク・スケッチで、反映されてる
論文: https://arxiv.org/abs/2304.09748
GitHub:https://github.com/kangyeolk/Paint-by-Sketch


・Bark: http://suno.aiが作成したテキストオーディオ生成モデル
多言語音声、音楽、バックグラウンドノイズ、簡単な効果音などの音声や、笑い、ため息、泣き声などの非言語コミュニケーションも生成可能
github: https://github.com/suno-ai/bark
hf: https://huggingface.co/spaces/suno/bark
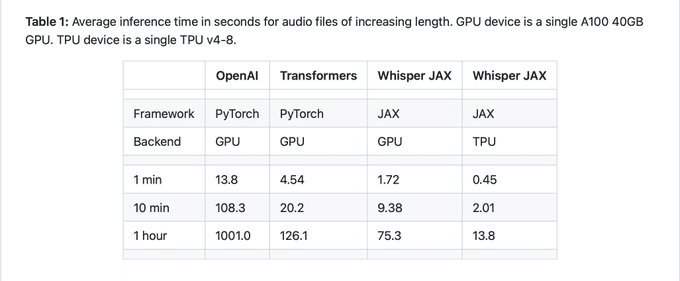
・Whisper JAX:Whisperを70 倍高速化 GPU と TPU の両方に対して最適化されている 1 時間分の音声を 15 秒以内に文字起こし
hf:https://huggingface.co/spaces/sanchit-gandhi/whisper-jax
github:https://github.com/sanchit-gandhi/whisper-jax#available-models-and-languages
・検索 x チャットボットの信頼性評価
Bing Chat、NeevaAI、http://perplexity.ai、YouChatを検証し、裏付けのない文章や不正確な引用が含まれていることがわかった。平均、生成文章のうち引用による完全サポートは51.5%、引用によって関連文章をサポートしているのは74.5%
・LMQL(Language Model Query Language)概観
この記事が気に入ったらサポートをしてみませんか?