
Stable Diffusion Web UIの設定を消費メモリを確認して行う
長らく放置してきたAutomatic1111の起動オプションを弄ってみた。settingsで行う部分が増えていてコマンドラインはかなり削れそう。オプションとして残るのはxformersとかmedramやモデルやコンフィグの指定かな。(実はxformers使っていなくて、opt-sdp-no-mem-attentionを有効にしているけど)
見直すポイントは以下二つ
モデルのfp8を有効にする
--no-half-vaeを無効にする
Windows11のタスクマネージャーではGPUの使用メモリ以外に、CUDAの負荷率も確認出来る(設定が必要だが)

CUDA使用率は100%で張り付いていて、100%を維持出来る時間が長いほど速度向上できる可能性がある。
従来の設定
VRAM12GBの環境でXLのモデルを動かすと途中からVRAMの空きメモリが0になっていてどうもこれがボトルネックになっていそう。

実行前使用メモリ:8.4GB
そういうわけで前回、説明したfp8を導入してみる。Stable Diffusion XLにしたと思ったらautismmixSDXL_autismmixPonyだった。サンプラーはEauler a,step 25で検証している。サイズは896x1216ぐらい(このサイズの理由は後で書く)

fp8 weightの導入
fp8の導入方法(1.9.4)
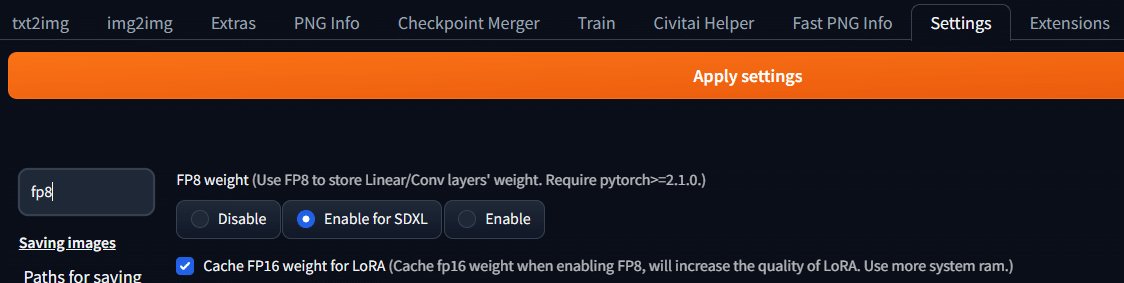
FP8 weight (Use FP8 to store Linear/Conv layers' weight. Require pytorch>=2.1.0.)
ここを変更するとcheck pointをFP8でロードするようになる(実際の演算はFP16で行われる)デフォルトはdisableで、enable for SDXLにするとSDXLのモデルのみ有効になる。Enbaleにすると全て有効になる。またLoRAの挙動に問題が出る場合があるらしいためCache FP16 for LoRAはチェックしておく。Apply Settingを押した時点で変更が出来ようされる(再起動は必要無い)

実行前メモリ4.9GB
VRAMが天井に張り付いている時間が大分短くなっている。一枚の作成時間も54秒から28秒に短縮。Diffusionプロセスは1割ほど遅くなっていた。しかし、その後にくるVAEプロセスが恩恵を受けた模様。

今回のケースではモデルの精度を落とした影響は見られない。
no-half-vaeを無効化する
次にコマンドラインの--no-half-vaeを無効にする。これはStable Diffusionの設定でVAEが真っ黒な画面になる場合にbf16もしくはfp32にVAEを切り変えるオプションが追加されているが--no-half-vaeが有効になっているとこのオプションが無視されるから。

・Automatically convert VAE to bfloat16
・Automatically revert VAE to 32-bit floats
この2つが真っ黒な画面が生成されたときにVAEの精度をあげるオプションとして実装されているためno-half-vaeは基本的に不要になるので、オプションを削除してWebUIを再起動する。
この状態でVRAMをチェックする。

実行前使用メモリ:7.3GB。fp16では真っ黒な画面が出るため、bf16でvaeが実行された。bf16は精度を落として桁数をfp32に合わせるモデルでfp32のモデルのそのまま倍速で動かしたい時に使われる。
A tensor with all NaNs was produced in VAE.
Web UI will now convert VAE into bfloat16 and retry.
To disable this behavior, disable the 'Automatically convert VAE to bfloat16' setting.


実行前使用メモリ:4.1GB。
メモリがほとんど天井にいかなくなっている。余裕はロードするLoraの数次第になるようだ。時間は30秒から25秒に短縮された。
ネイティブfp8だと生成時間も約半分になるが、そうでなくてもメモリが圧迫している場合はVRAMが空いた分だけ恩恵を受ける。
まとめ
デフォルト(--no-half-vae, fp16) 54秒
--no-half-vaeを削除 31秒
fp8を使う 27秒
両方適用 25秒
メモリがギリギリなのでちょっとした差で大分差が出る……。
※ 896x1216にしたのは、1024x1024だとここまで差がでないから(デフォルトだと40秒ぐらいで大体3割ぐらい )
この記事が気に入ったらサポートをしてみませんか?