[Tableau Tips]Tableauの計算順序(クエリパイプライン)の覚え方と、もっと細かい情報

** Tableau Tips * Tabjo Advent Calendar 2022 - Day15 **
やりたいこと:Tableauの計算順序(クエリパイプライン)を分かりやすく伝えたい
Tableauは非常に便利なツールだが、理解する上での壁はいくつかある。
その壁を乗り越えるために、私が一番理解すべきだと思うのが、Tableauの計算順序、通称クエリパイプラインである。
しかしこのクエリパイプライン、かなりとっつきづらい。公式サイトの画像が引用されることが多いが、英語の図がでてきて初心者に優しくない。

https://help.tableau.com/current/pro/desktop/ja-jp/order_of_operations.htm
そこで本記事ではクエリパイプラインを私なりに解説し、覚えて帰ってもらうことを目標にする。単なる丸暗記だと覚えにくいが、裏側の計算をイメージすると大分覚えやすくなる。クエリパイプラインを理解し記憶すれば、Tableauで自由に計算が出来ること間違いなしである。
少し長い記事だが、最後まで読んでもらえると嬉しい。
前提知識:データの集計粒度(Viz-LOD)
クエリパイプラインの解説に入る前に、2つ覚えて欲しい単語がある。
それはLOD(Level Of Detail)とViz-LODである。
LOD(Level Of Detail)とは、一言で表すとデータの粒度・細かさである。
例えばサンプルスーパーストアの場合、一番細かいデータの単位は製品名であり、注文された1製品名毎にレコードが分かれている。
例えば以下VizのLODは製品名で、最も細かい/深い単位で集計されている。

製品名やオーダーIDを外すとデータはサブカテゴリ単位で集約される。
よってこの場合のLODはサブカテゴリといえる。
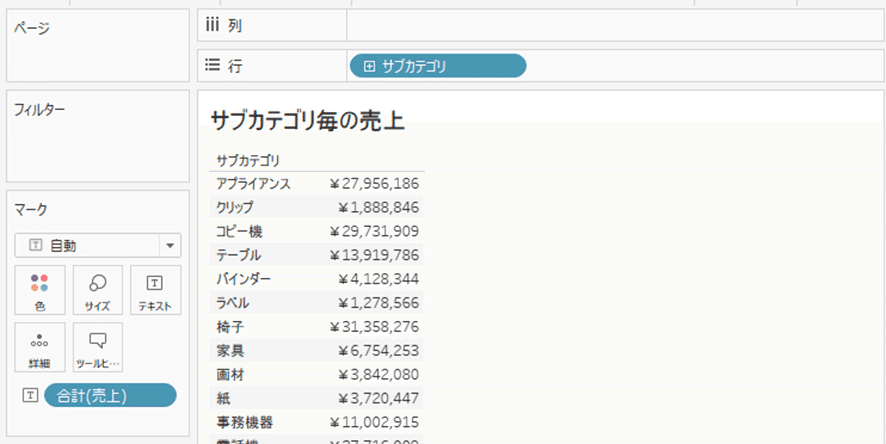
LODはVizにどのディメンション・メジャーを入れるかによって変わる。
そこで「このVizのLODはサブカテゴリです」と言うことがあり、
略して「Viz-LOD(集計粒度)はサブカテゴリです」と表現する。
Viz-LODは万人に通じる言い方ではないが、便利な表現なので今回使わせてほしい。余談だが、分析したい軸のLODが何なのかを常に意識すると実力がアップすると思う。
クエリパイプラインの全体像について
さて、ここから本題のクエリパイプラインについて紹介する。
ここでは公式の図表ではなく、私の方で加工した図表を紹介したい。

全体的に日本語にし、色付けをし、集計/非集計を追加している
図は商用利用以外であれば引用/転載しても問題ないが、本noteへのリンクを張ってほしい。
これで少しとっつきやすくなったと思うが、要素はまだ多い。
そこで頻出する下側の要素について抜粋し、そこを手厚く解説する。
クエリパイプラインの後半部分について
頻出する④ディメンションフィルタ以降を抜粋した図がこちら。

この図表をもう少し優しい日本語で表現するとこうなる
・④ディメンションフィルタに該当するデータをフィルタする
・Viz-LOD(集計粒度)に応じてデータを集計する(非集計/集計の境目)
・⑤メジャーフィルタに該当するデータをフィルタする。
・表計算を実行する
・⑥表計算フィルタに該当するデータを除く
これも暗記するには辛いが、裏側の計算順序を想像すると覚えやすくなる。
④ディメンションフィルタ・集計は気合で最初だと覚えよう(笑)
少なくとも後述の⑤メジャーフィルタや⑥表計算フィルタよりは前になる。
⑤メジャーフィルタは「売上の合計が10万円以上」のような集計された値のフィルタである。従ってメジャーフィルタは集計より後になる。
表計算は集計やメジャーフィルタより後になる。例えば表計算にはRank()があるが、売上合計のランクを出すには集計された値が必要なので、集計の後、といえば覚えやすいだろうか。
⑥表計算フィルタは当たり前だが表計算の後になる。
これを踏まえてクエリパイプラインはまず「ディメンションフィルタ→集計→メジャーフィルタ→表計算→表計算フィルタ」と頭に叩き込もう。計算順序を考えれば、少しは覚えやすくなる・・はずである。
ちなみにSQLが分かる人は④ディメンションフィルタをWHERE、集計をGROUPBY、⑤メジャーフィルタをHAVINGと例えると覚えやすいと思う。
後半部分の具体例について
フィルタ未適用の場合
より具体的なイメージを沸かせるために、少し具体的な解説に移ろう。
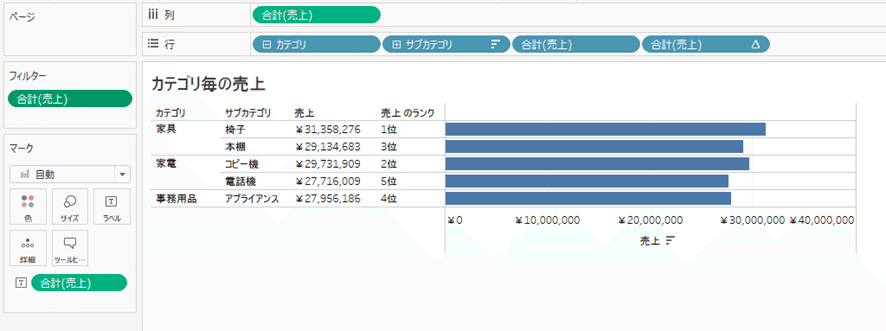
サンプルスーパーストアを元に、売上をカテゴリ・サブカテゴリ毎に合計し、サブカテゴリ毎に売上ランキング表計算で計算してみた。
このViz-LOD(集計粒度)は「サブカテゴリ」である

カテゴリもあるが、サブカテゴリより粗いのでなくても粒度は変わらない。
裏側の計算を想像してみよう。クエリパイプラインは「ディメンションフィルタ→集計→メジャーフィルタ→表計算→表計算フィルタ」である。
今回フィルタはないので、Viz-LODであるサブカテゴリ毎に売上を合計(集計)し、それを元にRank(表計算)が実行されていると想像できる。
表計算フィルタを使った場合
このVizに色々なフィルタを入れてみて、変化を観察してみよう。
まず表計算フィルタで、売上ランクを10位以内に絞ってみる。売上が下位のサブカテゴリは消えたが、合計(売上)の金額は変わってない。

クエリパイプラインを思い出そう。「ディメンションフィルタ→集計→メジャーフィルタ→表計算→表計算フィルタ」である。
表計算フィルタは最後なので、それより前の集計には影響を与えない。
ディメンションフィルタを使った場合
今度はディメンションフィルタを使ってみよう。カテゴリを「事務用品」に絞り「出荷モードが通常配送である」を追加してみよう。
この場合、売上合計とランクが両方変わる。

繰り返すが、クエリパイプラインは「ディメンションフィルタ→集計→メジャーフィルタ→表計算→表計算フィルタ」である。
ディメンションフィルタの結果、下流にある売上の合計(集計)とRank(表計算)に影響を与えているのである。
メジャーフィルタを使った場合
次はメジャーフィルタを使ってみよう。ここから少しややこしい。
売上の合計が2000万円以上に絞る。するとサブカテゴリが減っている。
メジャーフィルタの条件を更に変えてみよう。売上8000万円以上に絞ると要素がなくなる。売上8000万円以上を満たすサブカテゴリがないからである。

ところが、この状態でサブカテゴリを抜くと、家具と家電が復活する。
同じフィルタでも、Viz-LOD(集計粒度)によって結果が変わるのだ。

そろそろ覚えたいクエリパイプラインは「ディメンションフィルタ→集計→メジャーフィルタ→表計算→表計算フィルタ」である。
データの集計粒度はViz-LODによって変わり、今回はカテゴリ単位である。集計が変われば、メジャーフィルタの結果も変わり、Rank(表計算)の結果も変わる。今回の場合は売上が8000万円を超えていない事務用品だけが除外される。
クエリパイプラインの前半部分について
まずここまで理解できれば実務上の結構な割合の計算が出来るはずである。
その上で、抜粋前の図表に戻ろう。

前の解説でディメンションフィルタ、メジャーフィルタ、表計算フィルタは何となく覚えられたと思う。ここの骨さえ覚えられれば、後の要素を肉付けするだけで、割と雑に覚えても割と大丈夫である。
残りの要素について、「ディメンションフィルタより前」・「ディメンションフィルタより後」・「LOD計算」の3つに分けて話をしよう。
ディメンションフィルタより前

まず①・②・③のフィルタはあらゆる計算の前だと覚えればいい。強いていれば、影響範囲の広いフィルタほど上位にある。例えば②データソースフィルタは同じワークブックのシート全てに影響を与えるが、③コンテキストフィルタはワークシート単位で影響を与える。
そしてセット・上位フィルタ・条件フィルタは集計前の生データに対して計算すると覚えよう。なので③コンテキストフィルタより後、④ディメンションフィルタより前になる。
ディメンションフィルタより後

予測・クラスター・総計だが、個人的にはあまり意識した記憶がない。正確には⑤メジャーフィルタと⑥表計算フィルタの間だが、ざっくりディメンションフィルタより後と覚えても、それほど害はないと思う。
トレンドライン・リファレンスラインはVizの最終的な仕上がりによって変わるので、最後の⑥表計算フィルタの後と覚えよう。
LOD計算(Fixed/Include)

まずLOD計算とは、Viz-LODとは別のLODで計算するための手段である。
例えばFixed計算であればViz-LODと違うLODで計算が出来るし、Include/ExcludeであればViz-LODよりも細かくしたり粗くしたりできる。
Fixed計算の場合は生データに対する計算なので、④ディメンションフィルタより前になると覚えよう。余談であるがFIX(日本語で固定)とはいっても、クエリパイプラインの上位にあるので色々なフィルタや集計の影響を受けることがある。ここがLOD計算の分かりづらさだと思うが、長くなるので解説は割愛する。説明するには余白が足りない。
Include/Exclude計算の場合はViz-LODに依存して計算結果が変わる。なのでViz-LODが決まる集計の直前に実施されると覚えてみよう(少し強引ではあるが)。
もっと細かいクエリパイプライン
これでクエリパイプラインについて基本的な要素は抑えられている。
ただ実は海外のコミュニティにて、有志作成の非公式ながらも、
もっと細かいクエリパイプラインがまとめられた資料がある。

https://community.tableau.com/s/idea/0874T000000H9zbQAC/detail
これを日本語に変換したものがこちらである。

図は商用利用以外であれば引用/転載しても問題ないが、本noteへのリンクを張ってほしい。
この辺りの細かい要素は覚えずとも、困ったときに参照すればいいと思う。
ただ一つだけ意識してほしい要素があり、それは⑨非表示である。
基本的に表計算フィルタの結果を更にフィルタすることは出来ないが、ダッシュボードの表現の都合上、消したい要素が出ることがある。そんな時には⑨非表示を使うと解決することがあり、最後のフィルタとして覚えておいて損はない。
結局話しそびれてしまったが、クエリパイプラインを覚えると、やりたい計算の手段に目途がつくのが最大のメリットである。
12/19追記:データデンシフィケーションについて
⑤集計フィルタの直後にある要素について補足する。データデンシフィケーション(Data Densification)とは、本来データとしては1つの要素を複数のマークにするテクニックだ。日本語で表現するなら「高密度化」が近い。0、1のデータを0.1単位で刻んで水増しする様を想像してほしい。この増やしたデータはVizで図形を描く際に活用されることが多い。
詳細な解説は以下URL(英語)に譲るが、この図でいうデンシフィケーションとは、binを使ってマークを増やすテクニックのことである。結合やリレーションを使うデンシフィケーションではない。
Tableauの公式用語ではないが、作り方が分からないVizはこのテクニックが使われていることが多いので、覚えておいて損はない概念である。
余談:参考資料とか
本記事はTabjo Advent Calendar 2022のために作成した記事である。
もっと端的にするつもりだったのだが、書き出すと長くなってしまった。
執筆現在、締切前日23:55とギリギリであるが、なんとかまとめた。
少しでも参考になればうれしい。
より細かい解説については、私が昔勉強した素晴らしい記事たちがあるので
そちらを参考にしてほしい。
ganecoさんの記事 クエリパイプラインの各フィルタの解説があります。
Arakawaさんの記事 私がViz-LODを知ったのはここで
LODの解説もこれが一番秀逸だと思っています。
もし記載誤り等があればTwitterで連絡いただけると助かります。
ご意見・ご感想もお待ちしています。どうぞお手柔らかに・・
ついったー→ https://twitter.com/minoru_tech
noteを作成しました。Tableau Tipsです。
— みのる (@minoru_tech) December 17, 2022
無味乾燥なクエリパイプラインを覚えやすくなるよう解説してみました。巻末には細かい情報も載せています。これらを覚えると #Tableau の実力アップ間違いなしです。
ご参考になれば幸いです。https://t.co/RKiMCiv7b0
この記事が気に入ったらサポートをしてみませんか?