
【Aidemy成果ブログ】#清澄白河に関するインスタの投稿をワードクラウドで可視化してみた

自己紹介
こんにちは。3月からPythonの学習を始めた初心者です。
前職ではマーケティングの仕事をしていましたが、自分の知識不足からエンジニアやプロダクトマネージャーとのコミュニケーションが困難で、理解できないことが多くストレスを感じていました。そこで、プログラミングの学習を決意しました。
また、マーケターとして仕事をする上で役立つ言語について、ChatGPTに尋ねたところ、Pythonのデータ分析がオススメとの回答が返ってきましたので、この講座を受講することにしました(笑)。
本記事の概要
1.対象読者
プログラミング学習に興味があるも、習得できるか不安がある人。
私のように文系でかつ日常の業務でもプログラミングを使わない方。
2.この記事を読んでわかること
この記事では、インスタグラムのハッシュタグに関連する投稿をワードクラウドを用いて可視化する方法について説明しています。具体的には、自分が好きな清澄白河という街について、どのような特徴があり、どんなインスタグラムの投稿が多く行われているのかを一目で把握するためのプログラムを作成しました。
実行環境
Google colaboratory
作成したプログラム
制作の目的
ハッシュタグ「#」に紐づくインスタグラムの投稿の頻出単語をワードクラウドで可視化し、そのハッシュタグを利用してどのようなインスタグラム投稿が行われているのかを一目で把握することです。具体的には、私のお気に入りの街である清澄白河に関して、どのような投稿が多く行われているのかや、この街にどんな特徴があるのかを検証するために、『#清澄白河』に紐づけられている投稿をワードクラウドで可視化します。
用語について
ハッシュタグとは?
ハッシュタグはSNSの投稿に対する“タグ”として利用され、ハッシュタグの後に特定のキーワードを付与することで投稿がタグ化されます。タグ化されることによって同じキーワードでの投稿を瞬時に検索できたり、趣味・関心の似たユーザー同士で話題を共有したりすることが可能です。
ワードクラウドとは?
ワードクラウド(wordcloud)とは、文章やテキストから単語の出現頻度にあわせて文字の大きさを変えて視覚化したグラフのことです。
手順
下記の手順でコードを作成、実行していきます。
インスタグラムAPIの取得
ワードクラウドの作成と可視化
1.インスタグラムAPIの取得
まず最初に、Instagram Graph API実行に必要なアクセストークンとビジネスアカウントIDを取得する必要があります。Instagram Graph APIは、Meta for Developerで提供されるInstagram運用の効率化ツールであり、サードパーティーのアプリケーションがインスタグラムの情報にアクセスするためのAPIです。これにより、ハッシュタグを使用した投稿の検索が可能になります。
アクセストークンとビジネスアカウントIDを取得するには、次の手順を踏む必要があります。
インスタグラムプロアカウントの開設
Meta Business Suiteへアカウントの登録
FacebookとInstagramをリンクすることが必要です。
詳細な手順はこちらの記事をご覧ください。
アクセストークンとビジネスアカウントIDの取得が完了したら、コードを書いていきます。
まずは必要なライブラリーを呼び出します。
import requests
import pandas as pd
pd.set_option('display.max_rows', None)
import jsonインスタグラム側で決められている、『#清澄白河』固有のハッシュタグIDを取得する関数を定義します。
# ハッシュタグIDの取得(清澄白河固有の#ID)
def hashtag_id(business_account_id,query,token):
id_search_url = "https://graph.facebook.com/ig_hashtag_search?user_id={business_account_id}&q={query}&access_token={token}".format(business_account_id=business_account_id,query=query,token=token)
# APIに情報取得を指示(Jsonで取り出す)
# json形式は辞書型が基本
response = requests.get(id_search_url)
return response.json()['data'][0]['id']ハッシュタグIDに基づく投稿を取得する関数を定義します。
def hashtag_info(hash_id,search_type,business_account_id,query,token,fields):
all_response = []
count = 0
count_limit = 3
request_url = "https://graph.facebook.com/{hash_id}/{search_type}?user_id={business_account_id}&q={query}&access_token={token}&fields={fields}".format(hash_id=hash_id,search_type=search_type,business_account_id=business_account_id,query=query,token=token,fields=fields)
response = requests.get(request_url)
result = response.json()
all_response.append(result['data'])
# 25件以上データがある場合は取得
# next URLがあるかぎり続ける(While...)
if 'next' in result['paging'].keys():
next_url = result['paging']['next']
while next_url is not None:
request_url = next_url
response = requests.get(request_url)
result = response.json()
all_response.append(result['data'])
#次のページがあるか 、かつCountという変数がCount_limit未満であるかどうか - 79以降が動く
#次のページがあるかぎり 、条件式が満たされる
if 'next' in result['paging'].keys() and count < count_limit :
next_url = result['paging']['next']
count = count + 1
else:
next_url = None
return all_response
mainを定義します。mainには下記の内容が含まれます。
取得したアクセス情報(ビジネスアカウントIDとトークン)を記載。
投稿に対する情報と検索タイプを指定
検索キーワード(調べたい#)を”清澄白河”と指定
ハッシュタグIDの取得
ハッシュタグ検索結果の取得
データを結合し、重複を排除
データフレームに変換
CSVで出力
def main():
# アクセス情報
business_account_id = "XXXXXXX"
token = 'XXXXXX'
# インプット情報
# 投稿に対する情報
fields = 'id,media_type,media_url,permalink,like_count,comments_count,caption,timestamp'
search_type = "top_media" #検索タイプ recent_media or top_media
# 検索キーワード指定
query = "清澄白河"
# ハッシュIDの取得
hash_id = hashtag_id(business_account_id,query,token)
# ハッシュタグ 検索結果取得
result = hashtag_info(hash_id,search_type,business_account_id,query,token,fields)
# データの結合、重複排除
df_concat = None
# データフレームに変換
df_concat = pd.DataFrame(result[0])
if len(result) != 1: #要素数が1ではない場合以下のコードを実行
for i,g in enumerate(result): #要素の番号も一緒に取得 (iが番号、gは利用していない)
df_concat = pd.concat([pd.DataFrame(result[i]), df_concat], sort=True) # DFを連結 df_concat に代入、並び替え有効
df_concat_sort = df_concat.sort_values('timestamp').drop_duplicates('id').reset_index(drop='true') # 'timestamp'列で並び替え→古い順に並び替え、'id'の重複を排除(同じ投稿)、reset_inde、番号を振る
df_concat_sort.to_csv(f"{query}.csv") # CSV出力
# 結果出力
display(df_concat_sort)ハッシュタグ情報に基づく投稿のデータを取得します。
# ハッシュタグ情報に基づく投稿のデータを取得する
def hashtag_info(hash_id,search_type,business_account_id,query,token,fields):
all_response = []
count = 0
count_limit = 3
request_url = "https://graph.facebook.com/{hash_id}/{search_type}?user_id={business_account_id}&q={query}&access_token={token}&fields={fields}".format(hash_id=hash_id,search_type=search_type,business_account_id=business_account_id,query=query,token=token,fields=fields)
response = requests.get(request_url)
result = response.json()
print(result)
all_response.append(result['data'])
# 25件以上データがある場合は取得
#next URLがあるかぎり続ける(While...)
if 'next' in result['paging'].keys():
next_url = result['paging']['next']
while next_url is not None:
request_url = next_url
response = requests.get(request_url)
result = response.json()
all_response.append(result['data'])
#次のページがあるか 、かつCountという変数がCount_limit未満であるかどうか - 79以降が動く
#次のページがあるかぎり 、条件式が満たされる
if 'next' in result['paging'].keys() and count < count_limit :
next_url = result['paging']['next']
count = count + 1
else:
next_url = None
return all_responsemainを実行します。
# mainの実行
main()mainを実行すると下記のCSVファイルが取得できました。
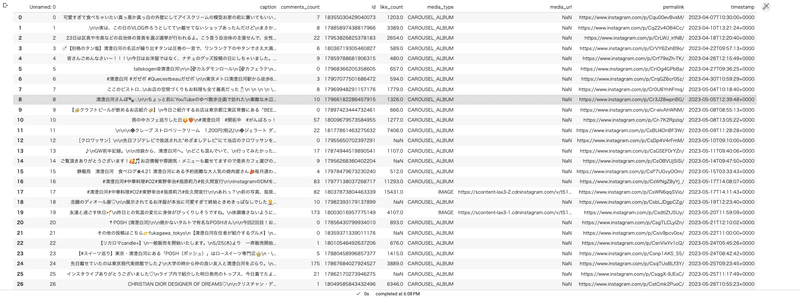
2.ワードクラウドの作成と可視化
次に、先述の手順で取得したCSVファイルを使用して、『#清澄白河』に関連付けられた投稿の頻出単語をワードクラウドで可視化していきます。この作業には、こちらの記事を参考にしました。
まず必要なライブラリやフォントをインストールし呼び出しを行います。
# Janomeのインストール
!pip install Janome==0.3.7
# pandasのimport
import pandas as pd
# Tokenizerを使用
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# フォントのインストール
!apt-get -y install fonts-ipafont-gothic
# WordCloudとmatplotlibをインストール
from wordcloud import WordCloud
import matplotlib.pyplot as plt CSVファイルを読み込み、Data Frameを作成します。
import pandas as pd
df=pd.read_csv("/content/清澄白河.csv")CSVの中からCaption列のみ抽出します。
text = df["caption"]
リスト型に変換し、””で接続します。
text=text.to_list()
text = " ".join(text)形態素解析処理を行い、投稿文を言語において意味を持つ最小の単位に細分化ます。
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text) word_listの中に、名詞のみを抽出し、非独立名詞、代名詞、数を除くという条件条件を満たした単語を追加し、リストを””で接続します。
word_list=[]
for token in tokens:
word = token.surface
partOfSpeech = token.part_of_speech.split(',')[0]
partOfSpeech2 = token.part_of_speech.split(',')[1]
# 名詞のみ抽出 (非自立名詞、代名詞、数を除く)
if partOfSpeech == "名詞":
if (partOfSpeech2 != "非自立") and (partOfSpeech2 != "代名詞") and (partOfSpeech2 != "数"):
word_list.append(word)
# リスト内の単語を””で接続
words_wakati=" ".join(word_list)
print(words_wakati) 除外ワード、フォントを指定します。
# 除外ワード
stop_words = ['清澄','白河','さん','君','江東','東京', 'グルメ', '森下', '木場', '門前仲町', '好き', '区', '日', '店']
# 日本語フォント指定
fpath = '/usr/share/fonts/truetype/fonts-japanese-gothic.ttf' 下記のコードでワードクラウドを作成します。
wordcloud = WordCloud(
font_path=fpath, # フォント指定
width=900, height=600, # default width=400, height=200 画像の縦横のサイズ
background_color="white", # default=”black” 背景色の指定
stopwords=set(stop_words), #表示したくない文字をリストで渡す set関数は重複を排除
max_words=500, # default=200 #500単語まで抜き出す
min_font_size=4, #default=4 最小フォントの指定
collocations = True #default = True #複合語を分割しないように表示設定する
).generate(words_wakati) matplotlibで作成したワードクラウドを可視化します。
# 表示設定
plt.figure(figsize=(15,12))
plt.imshow(wordcloud)
plt.axis("off")
plt.savefig("word_cloud.png") #保存する
plt.show()コードを実行すると、下記のワードクラウドが作成されました。

考察
今回のプログラムより、『#清澄白河』に紐づくインスタグラム投稿文の中でよく使用される単語を可視化することができました。作成したワードクラウドから、清澄白河の街について多く投稿されている内容や街の特徴を推測することができます。
ワードクラウドには、カフェやランチ、料理、スイーツ、ベーグルなど、食事に関連する単語が多く現れました。これから、清澄白河が美食の街であることが想像できます。また、美術館やデザイン、スタジオ、コーデなどの単語も見受けられ、清澄白河がアートやファッションの街である可能性もあります。
一方、プログラム作成後、インスタグラム自体が食事やカフェ、ファッションに関連する投稿をする人が多い傾向があると感じ、以前よく行っていた池袋の街と比較してみることにしました。
以下は、『#池袋』に関連する投稿のワードクラウドです。(地名の『池袋』と『豊島』をコード内の除外ワードに追加しました)

『#池袋』の投稿をワードクラウドで可視化した結果、カフェという単語が大きく表示されており、清澄白河同様にカフェに関する投稿が多いことがわかります。一方で、清澄白河と比べると、ラーメン、つけ麺、そばなど、麺類に関連する単語が目立つ印象です。
また、『#池袋』の投稿では髪に関連する単語が多く見られます。髪、ロング、ブリーチ、トーンなどの言葉が頻出し、美容院に関する投稿が多いことがわかります。これから、池袋には多くの美容院が存在している可能性や、美容院がインスタグラムを積極的に活用している可能性が推測できます。
以上の結果から、作成したプログラムを使用して、インスタグラムの「#」に関連する投稿文の頻出単語を可視化し、その地域でよく投稿されるトピックや街の大まかな特徴を把握することができました。
終わりに
全くのプログラミング学習初心者でしたが、受講期間を通じて、全くのプログラミング学習初心者からスタートしましたが、Pythonの基礎から機械学習の概念やデータ分析の手法を学び、実際に実装することができ、達成感を感じています。今後は、Kaggleを活用したり、友人に課題を出してもらったりするなど、実践を積んでいくことを考えています。成果物を作成する際に協力してくれた方々に心から感謝申し上げます。
この記事が気に入ったらサポートをしてみませんか?