
【ChatGPT】Web会議の録画を文字起こし&議事録作成【Whisper】

水鳥川いると申します。
ZoomやGoogleMeetのWeb会議の録画データを、自動でダウンロードしWhisperを利用してテキスト化、Llamaindexで議事録を作成するスキームを構築しました。(完全自動化)
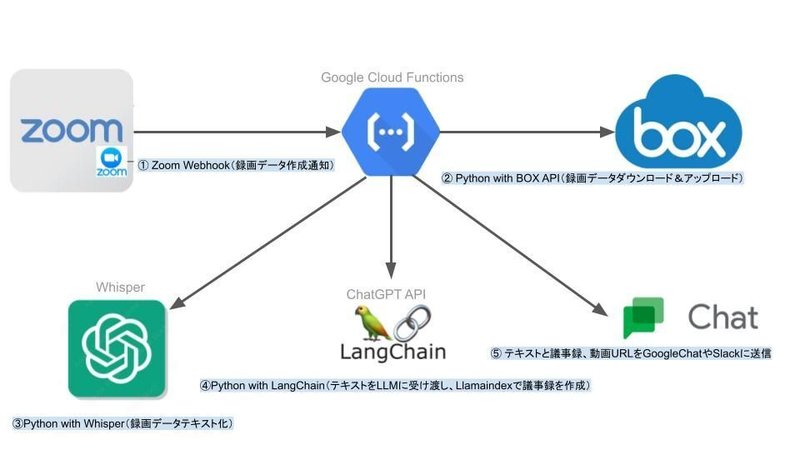
議事録をを自動作成する方法を解説しています。
Zoomの場合の例を記載しますが、GoogleMeetやMicrosoftTeamsでも可能です。Zoomの場合は録画データをAPI経由でダウンロードするために、Zoomライセンスはビジネス以上が必要になってきます。
詳細
① ZoomWebhook(録画データ通知)
Webhookとは、アプリケーションでイベントが発生した際に、外部のアプリケーションに対してHTTPで通知する仕組みです。
今回利用するZoom Webhookは、ZoomでMeetingの録画データが作成された際に、今回用意するアプリケーションに通知する機能です。
具体的な方法は以下のページが詳しいので割愛しますが、ZoomDeveloperに登録して、Webhook OnlyのAppを作成してトリガー先のURLを設定します。
そうすることで録画データが作成されたときにだけGoogleCloudFunctionsが実行されます。
初回設定時にURLを登録して認証する必要があり、認証を通すのに少し苦労しました。
② 録画データをBOXにアップロード
Zoomの録画データをダウンロードして、クラウドストレージのBOXにアップロードします。
録画データのアップロード自体はテキスト化に必須でないため、こちらは省略しても問題ありません。また、BOXではなく別のクラウドストレージへのアップロードも可能です。
BOX APIで特定のフォルダにmp4ファイルを名前を付けてアップロードします。
②~⑤は、ZoomWebhookをトリガーに、GoogleCloudFunctionsにPythonで構築したプログラムで処理しています。
以下はBOXにAPI経由でアップロードするサンプルコードです。
import requests
import json
import datetime
import tempfile
from pytz import timezone
from dateutil import parser
from boxsdk import Client
# Get auth client
client = Client(sdk)
def box_api(y,headers,sub_folder_id):
if len(y['items']) != 0:
for record in y['items']:
url = (record['fileReservation'][0]['url'])
r = requests.get(url,headers=headers,stream = True)
#一時ファイルに読み込んだデータを保存
img = None
with tempfile.NamedTemporaryFile() as fp:
fp.write(r.content)
fp.file.seek(0)
#BOX API
file_path = fp.name
file_name = record['_id'] + "_" + parser.parse((record["_createdAt"])).astimezone(timezone('Asia/Tokyo')).strftime('%Y-%m-%d %H:%M:%S') + "_" + record['fileReservation'][0]['fileName']
box_file = client.folder(sub_folder_id).upload(file_path, file_name)
fp.close()③ Whisperでテキスト化
Whisperは、ChatGPTで有名なOpenAI社が文字起こしサービスとして公開した無料の音声認識モデルです。WhisperはWebから収集した68万時間分の多言語音声データを教師付きデータで学習させており、高い精度で入力した音声を文字起こしすることが可能です。
会話を文字起こしすると、精度が気になると思います。
ノイズがあったり、専門用語が多いと誤字が増えますが、ファインチューニングをすることで専門用語をWhisperに学習させ、より精度を高めることができます。
WhisperはGoogleColaboratoryでGPUを使い、簡単に試すことが可能です。
Whisperで文字起こしをするサンプルコードです
!pip install git+https://github.com/openai/whisper.git
import whisper
import json
model = whisper.load_model("large-v2") #モデル指定
result = model.transcribe("test.mp4", verbose=True, fp16=False, language="ja") #ファイル指定
print(result['text'])
f = open('test.txt', 'w', encoding='UTF-8')
f.write(json.dumps(result['text'], sort_keys=True, indent=4, ensure_ascii=False))
f.close()④ LangChainで議事録を作成
ChatGPTのAPIに入力できるトークン数は、gpt-3.5-turbo-16k-0613で16000(約8000文字)、gpt-4-32k-0613で32000(約16000文字)です。
1分間にスピーチする文字数は350文字が適切と言われており、出力のトークンも考えると8000文字だと約20分、16000文字だと約40分の議事録を作成できます。
このことから1時間以上の会議の場合にトークンがオーバーしてしまう可能性があるため、Llamaindexを利用してトークンを抑えていきます。
LlamaIndexはChatGPTを使用して独自のデータに対して質問できるようにすることができるフレームワークです。テキストやHTML、PDFなどを入力してインデックスファイルを作り、そのインデックスファイルに対してクエリを投げることで、ChatGPTが学習していない最新の情報に対して質問することが可能です。
今回は録画データをテキスト化したファイルのインデックスを作成して議事録を作成します。
!pip install openai
!pip install langchain
!pip install llama-index
import os
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
# インデックスの作成
documents = SimpleDirectoryReader("data").load_data()
index = GPTVectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
index.storage_context.persist()
print(query_engine.query(""""会議の書き起こしが渡されます。
この会議のサマリーをMarkdown形式で作成してください。サマリーは、以下のような形式で書いてください。順番は前後しないようにしてください
- 1.本日の議題(100文字程度)
- 2.連絡事項の確認(発表者を記載すること。連絡事項がない場合は「なし」と記載)(300文字程度)
- 3.社長からの連絡(300文字程度)""""))⑤ 議事録をSlackやGoogleChatに送信
④で作成された議事録やテキスト、動画URLをSlackやGoogleChatに送信します。
会議に出られなかった人は、議事録を見ることで時短で概要を把握することができます。議事録を取る必要もなく、参加者は会議に集中することが可能です。
後記
・教師あり学習のファインチューニングを試したい
・Youtube等のライブ配信に転用して、まとめサイトを作りたい
この記事が気に入ったらサポートをしてみませんか?