
深層学習を用いたポーカーエージェントの発展
最近選択肢がいくつか出てきた深層学習を利用した機械学習系のソルバーですが、その元祖と言えるのがDeepStackです。
DeepStackはナッシュ均衡を近似して、不完全情報ゲームであるNLHEのHUをプレーすることを主眼に研究されていましたが、その目玉と言えるのが深層学習を利用してプレー中の迅速な再計算を可能とする機能です。
深層学習モデルはフロップとターンで利用されており、リバーに関してはモンテカルロで解いています。すべてのプレーをAIが判断するのではなく、ソルバーのような計算結果と機械学習モデルを組み合わせてプレーを構築します。
今回の記事ではこの深層学習を利用したソルバー及びポーカーAIについて、筆者が感じた疑問とそれなりの答えにたどり着くまでに教えていただいたこと、調べた内容をまとめてみたいと思います。
なお筆者は機械学習が専門ではありませんが、業務で多少扱うためモデルのコーディングくらいはできるという理解度です。そのため記事内での間違い等は筆者の不理解によるものとお考えください。
事の発端
これはRuseという深層学習ベースのソルバー開発元が書いているブログ記事です。この記事の以下の部分にベンチマークがあります。
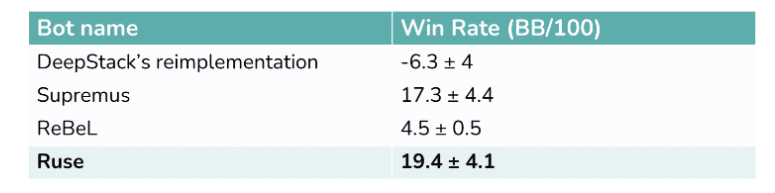
これはSlumbotという既存のボットに対してRuse, ReBeL, Supremus, そしてDeepStackがどういった成績を残したかを示しています。
彼らの主張によると、Slumbotに対してDeepStackはおそらくマイナス、Ruseは大きく勝ち越しているとのことです。深層学習系のソルバーというとDeepSolverという商品もありますが、彼らの情報も合わせて読むと、深層学習を利用したツールは概ねDeepStackの方法を踏襲しているように思えます。
DeepStackが発表されたときはSlumbotに優位性があると主張されていましたが、おそらく近年はSlumbotも進化しており、逆転したものと思われます。
とはいえDeepStackも深層学習をベースとしたモデルであることには変わりないのですが、ここでわかるようにDeepStackとRuseにはかなり力の差があるように見受けられます。
筆者の当初の疑問は以下です。
深層学習ソルバーの訓練に使われるターゲット
訓練用のターゲットが作成される際の戦略
深層学習ソルバーが出せる現実的な精度
筆者は当初、訓練のターゲットはEVであり、ボットとしてはそのEVをもとに最終的なアクションを決める、というようなぼんやりとした理解でした。
そこで友人であるヒガシ氏にDeepStackの論文を紹介していただき、それを読んでから色々質問、さらにDeepStackの論文を補うSupplementも紹介してもらって理解を深めました。
論文
補完情報
その過程で曖昧な理解だったCFRに関する論文も読み、概ね当初の疑問は解決出来たと思っています。
結論としては、以下となります。
ターゲットはCFRで求めるベクトル
ターゲット作成時に使われる戦略は事前実験を元に抽象化されたもの
精度に関しては原因となる部分については詳しくわかっていないのですが、具体的な損失については論文で記載されており、同様の指標で評価されているSupremusの論文から一部抜粋し、DeepStackと比較するという形を結論としたいと思います。
以降の章では、この章で触れた用語を簡単に解説しながら、疑問に対する答えについて掘り下げます。
Slumbot
ベンチマークとして使われたSlumbotですが、これは実際にPIOで計算したシミュレーションを大量に集めて作られたモデルのようです。深層学習等は利用しておらず、アクションを抽象化(つまりベットサイズの限定など)することで戦略を決めます。
簡単に言うと簡易GTOを丸暗記してみました!というボットだと思われます。相手のベットに対しては近い値に丸め込んで戦略を決定します。
作成元によりUIが公開されておりHUの壁打ちができます。また、APIも公開されているので自分でなにか作ることもできそうですね。
あくまで研究用という意図が見られ、機械学習系のソルバーやボットが評価指標の一つとして扱いやすいのではないかと思います。
CFR
https://poker.cs.ualberta.ca/publications/NIPS07-cfr.pdf
Counterfactual Regretという概念を導入して不完全情報ゲームを解くための方法を提示した論文です。
イメージとしては、あるアクションの期待値です。ですがいわゆる期待値、つまり算術平均のようなものではなく、あるアクションを取ったときと他に取り得たアクションの利得をすべて求めて、その他の利得から対象とするアクションを引いて、全て足し合わせた値です。本稿ではこの値をRegretと呼ぶこととします。
たとえばポットベットのRegretを求めるとします。あなたはチェック、スモールベット、ポットベット、オールインというアクションを想定しています。ここで、それぞれの利得(効用関数CFR utilityとして定義される)を求めて、それぞれからポットベットの利得を引きます。それらを合計した値がこのアクションのRegretということになります。つまり他のアクションで得られるチップが大きいほど、この値が大きくなります。
PIO Solverなどはこの計算を更に過去に遡って別のアクションを選択した場合なども求めながら全体の戦略を計算していくことになります。
この利得自体をどうやって求めるかというと、力技でリバーまでのアクションをすべてシミュレーションします。先程の例で言うと、フロップでポットベットしてから起こり得ることをすべてシミュレーションして、得られるであろうチップの平均を求める、という感じです。
このように大量のループ処理を行うことでナッシュ均衡の近似を求めるのがSolverということになります。かなりの計算力が求められるのも自然ですね。
DeepStackの訓練ターゲット
前提となる知識を簡単に紹介したので、最初に挙げた以下の疑問についてDeepStackの論文から得た知見をまとめます。
深層学習ソルバーの訓練に使われるターゲット
その答えは以下でした。
ターゲットはCFRで求めるベクトル
前章で触れたように、CFRというのはRegretを計算するための方法でした。ソルバーというのはこのRegretを求めますが、DeepStackはこの計算部分を事前に行い、各アクションのRegretをターゲットとして深層学習モデルで訓練します。
ベクトルという部分に関しては、Regretを各ハンド(正確にはハンドを1000種類に抽象化したBucketと呼ばれるデータ)で求めるため複数ある、ということです。ポーカーはアクションやハンドなどその場で起こりる、あるいは選べる選択肢が複数ありますから、それらを同時に考慮した答えは単純な10とか100といった数値ではなく、数字で埋まった列や表のようになるということです。これを予め用意し、モデルを訓練します。
この事前に準備する答えは、PIOのような計算機で計算してしまいます。そして深層学習でこのベクトルを答えとして、それに近い値を求められるように少しずつ内部の重みを調整していく、ということになります。具体的にはあるレンジ、ポットサイズ、ハンド、などの情報を与えて、PIOの計算結果を予測してもらいます。その結果がいまいちなら内部のパーツを少し調整して、もう一回予測してもらいます。これを何度も繰り返すことでなるべく近い答えを予測できるように育てるということです。
実際の対戦ではこのRegretをモデルで予測することで、ソルバーによる再計算を代替することができます。仮に元々の計算結果を参照するだけの仕組みだとすると、ターン時点で想定していなかった展開が訪れた場合、その値を想定していたアクションのどこかに丸め込むか、フロップから再計算することになります。一方、DeepStackのように機械学習を利用する場合、そのときに得られる情報を入力すれば何らかの答えが返ってくるため、再計算の必要がありません。
あくまでDeepStackはレンジ、ベットサイズ、ボード、ポットサイズといった情報から次に適切なアクションを予測するという仕組みですから、珍しいベットサイズに対しても統計的に良さそうな対応を行います。もちろん対応がまずい可能性はありますが、ある程度人間のようなアクションを行うことができる、と言っても良いかもしれません。
DeepStackの訓練用戦略
前章では一つ目の疑問とその答えをまとめました。ここでそれに連なるもう一つの疑問が湧きました。
訓練用のターゲットが作成される際の戦略
完成したモデルはどういった事態が起きても、そのモデルなりに答えを出せるということはわかりましたが、一方で訓練時のベットサイズはどうでしょうか。
たとえば訓練用のターゲットを求める際のソルバーの設定が非常に粗いものであったなら、そもそも予測したRegretが現実的な精度ではないかもしれません。
この部分については論文に記載がありました。戦略はシンプルで、ポットベットとオールインのみだそうです。このベットサイズですが、事前にいくつかのボードで計算して、計算量とのトレードオフで設定したとSupplementの方に記載がありました。

これはSupplementに掲載されていたベットサイズに関する資料です。一番上はフォルド、チェック、ミニマムベット、各X%ポットサイズベット、そしてオールインという設定です。つまりベットサイズは9種類となります。そしてリバーを100種類ほどランダムで取り出して計算、それを1セットとして、これを4000回繰り返してベンチマークとします。
次にそれ以外の設定で1000回計算してRegretを予測し、一番上のベンチマークと比較します。右に並んでいるL1, L2, L∞はそれぞれ評価指標で、ベンチマークとの差を表しています。
この中からサイズが小さく、ロスが比較的ましなものとして真ん中の方にあるF, C, P, Aが選ばれた、ということだそうです。
実際にプレーする場合はどうなるのか?という点ですが、その際はハーフポットベットと2ポットサイズベットが加えられるそうです。ですから、戦略がほぼポットサイズベットのみ、ということではなさそうですが、非常に小さいベットサイズなどは用いないようです。
現在の主流からすると少しベット戦略が粗い感じもしますが、リソースとの兼ね合いから調整されたことが伺われます。
DeepStackと近年の深層学習モデル
この章では近年の深層学習ベースのポーカーボット、Supremusについて簡単に取り上げたいと思います。最初の章で紹介しましたが、Ruseに近いパフォーマンスを出したもう一つのボットがSupremusです。
Ruseは開発元に問い合わせたところ論文は未発表、今後の予定もないそうで、一方Supremusは論文が出ており、ありがたいことに予測精度が定量的にDeepStackと同じ方法で記載されていました。そこで、今回は当初目をつけたRuseではなくこちらの論文から抜粋した情報を紹介します。
https://arxiv.org/pdf/2007.10442.pdf
SupremusとDeepStackのわかりやすい違いは、アクション空間がより現代的な種類になっていることです。33%ポットベットや75%ポットベットなど実戦でよく見るサイズが追加されています。

訓練モデル用の設定が確認できていないのですが、実戦ではSupremusは小さなベットサイズを取り入れていることがわかります。また、セカンドアクションとして25%のようなレイズの選択肢が存在します。これは4ベットポットなどで違いを生むと考えられます。
さらに、予測精度自体も向上が確認できます。
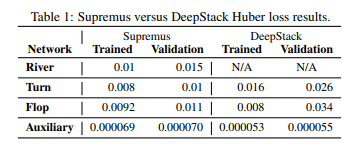
この指標はHuber lossという値を使用しています。少しわかりにくいのですが、あるポットサイズにおいてソルバーで求めたRegretと予測したRegretにどれだけ差があるかを最小二乗法と線形を組み合わせて求めた値となります。よって単純にポットのX%失っている、というような見方はできないのですが、DeepStackに比べて進化している様が伺えます。
やや専門的な話になりますが、Supremusは訓練時にDeepStackとは異なるメソッドを採用しています。リバーのモデルを作り、そこでランダムにRegretを求めて、それをターン学習時のターゲットとしています。さらにそのターンのモデルから得られる結果をフロップのターゲットにして訓練します。そのためDeepStackには存在しないリバーのモデルが存在しています。
もう少し専門的な話
Supremusは評価関数を呼ぶ回数も大幅に増やしています。フロップを例に取るとDeepStackはフロップのアクションが閉じたタイミングでRegretを求め、その値を次のストリートのモデルのインプットとします。Supremusは同様にターンのインプットとしますが、ターンのカードが開いた時点でもう一度Regretを求めて、軌道修正を図ります。DeepStackはリバーでは総当たりで解いてしまうのに対し、Supremusはもう一度予測しており、そのためリバーのモデルが存在します。このように戦略の精度を高める工夫がそのまま精度差につながっているものと思われます。
なおDeepStackの時点でフロップの入力用のベクトルに関してはAuxiliary networkが作成されており、そのモデルでいったんフロップが得るであろう予測値を計算してます。Supremusはこの方法を更に拡大して各ストリートに応用したようにも見えます。
簡単に言い換えると、よりたくさん予測と訓練を組み合わせることで、より逐次的に評価及び予測を行うことができるように作成されており、予測精度の向上を図っている、ということになります。
プレーに際しても予測をより細かく行うことで、精度を高めています。このあたりはDeepStackはプレー速度に対してかなり意識していたことが論文にも記載されており、当時の計算力との兼ね合いから調整されたものだったように思います。
このように、計算力の向上に伴い、より丁寧に計算と予測を繰り返し、純粋な予測精度の向上とアクション空間の拡大に成功しています。このような経緯から近年の深層学習ベースのボットはより強化されていると言えるでしょう。
Slumbotは深層学習を用いず、あくまでアクションの丸め込みを軸として戦略を決めていますが、Ruseはそれに対して大きく優位を得ていました。SupremusとRuseの間に差異がそこまで無いことを前提としますが、Supremusの論文によるとSupremusはSlumbotを搾取するようには調整されておらず、与えられた条件からナッシュ均衡を予測しているだけです。しかし、柔軟なプレー空間とナッシュ均衡の再現度の高さにより、ここまで大きな差がつくということがわかります。
おわりに
本稿では深層学習を利用したソルバーとAIについて、筆者の個人的な調査内容と近年の発展について簡単に紹介しました。発端はRuseのパフォーマンスに興味を抱いたことからでしたが、基本構造についてはDeepStackを、また同程度のパワーを持つと考えられるSupremusをRuseに代わって取り上げました。
余談となりますが、Ruseの記事で取り上げられているもう一つのAIであるReBelは強化学習を取り入れたモデルのようです。NLHEのHUでは抽象化を利用した教師あり学習が今のところ上手く行っているように見えますが、今後強化学習を利用したより汎用的なモデルが既存の深層学習ポーカーエージェントを凌駕する日が来るかもしれません。
https://arxiv.org/pdf/2007.13544.pdf
この記事が気に入ったらサポートをしてみませんか?