#6 newの魔術

プログラムをやったことある人なら知っている…..かもしれないnew演算子。JavaやC#、C++とか、そのほかいろんな言語を触ると出てくるnew。これのすごさについて語りたい。
テキスト
Mikan本様、いつもお世話になっております。
そもそもnew演算子とは
class Hoge
{
...... クラスの内容......
}
Hoge hoge = new Hoge(); new Hoge()のnew。これがnew演算子。といきなり具体例を出したですが、どうでしょう。息を吸うように使っているのでは?
いちいちnewを書くのが面倒くさいって?いやいや、こいつの素晴らしさたるや!
プログラマーではない人への例え話チャレンジ
チャレンジなんで、わからなかったら許してください。ちゃんとわかりたい方、あなたもプログラム始めましょう!!
さてヤケクソの言い訳はともかく、プログラムでは変数というものを使います。変数というと、数学で使ったやつのイメージが強いが、プログラムの変数は少し違うイメージ(を私は持っている)。
プログラムで言う変数とは
データの保管場所
である。この変数にデータを入れておくと、プログラムの中で何回も使いまわせてすごく便利。え…それって、どういうこと?

さてここで、図を使ってみる。手書きかつ汚くて少々見づらいがご容赦を。これが変数のイメージ図。
int a = 10; 図にもあるこのプログラムは、整数型変数 a に10を入れてねという命令。それを図にしたのが右側。こんな感じでコンピューターが処理してくれる。
つまり
intの大きさの箱を作る
10を持ってきて箱に入れる。
という2段階で変数を作る。そこまで難しい話ではないと思う。しかし、『intの大きさって何?』
箱(変数)の大きさの重要性
この大きさは案外重要なところ。これを理解するためには、このマガジンの4つ目、メモリ管理のお話で書いたことを復習します。
(詳しく読みたい人は拙い文ですが、以下をどうぞ。)
箱の大きさと関係してくるお話としては、メモリ・CPUにはデータと処理の間に区別がないというくだりです。だからメモリ管理ではどこが処理で、どこがデータのかチェックしないといけないわけです。
この「どこが何を表しているのか」を管理するために大きさが必要なわけです。つまり「この場所は○○というデータが入ってるよ」というのを、プログラムがコンピューターに教えるわけです。

とこんな感じでメモリ上に変数aを置くわけです。この時aの大きさがわからないと、どれくらい場所を取ったいいのかわからなります。だから、箱に大きさをつけて変数を作るわけですよ。
結局、箱の大きさとは?
さて、変数は箱。この箱の大きさは重要だ!と主張してきたわけですが。重要性は分かった。が、実際のところ箱の大きさってなんだよ!というお話を。 復習にもう一度、最初のプログラムを。
int a = 10;これ。このintが箱の大きさなわけです。みなさい、intが箱の大きさなんです。この箱の大きさをデータ型といいます。箱の大きさは、実はデータの種類を表したものなんです。
さっきのメモリ管理の話、データと処理に区別がないという話。実は秘密がもう一つ。メモリではデータの種類にも区別がないのです。
嘘じゃないんです。本当なんですよ!結局、どんな種類のデータでもCPU君から見たら、0と1の集合なわけで。それを区別できるように、ラベルを付けてあげるのがデータ型です。
データ型を指定してあげることで、CPUに
「ここから、ここまでのデータは○○っていうデータです」
と教えてあげることができます。(CPUはこの命令を元からわかるように設計されてます。)

データの種類が分かれば、その扱い方もわかる。ので、プログラム先生がCPU君に教えるわけです。これ以上の詳しいことは長くなるので書きませんが、だいたい以下のような種類のデータ型があります。
int型:整数の箱(例:1、100、1232、-100)
float型:実数の箱(例:1.00、12.25、3.14、-1.414)
double型:実数の箱(float型より正確に数字を保管できる)
char型:文字の箱(例:a、b、c) 文章は入れられない
long型:整数の箱(intより大きな箱。大きな数字も入る)
あともう少しだけあったりなかったり。プログラム言語によりますね。
箱をnewする
やっとnew演算子のお話。newとはざっくりいうと、箱を新しく作ってねという指示。え、さっきのintの箱を作るときには、new使ってないじゃん。
int a = 10;そうなんです。実はいままで紹介したデータ型は、基本データ型と呼ばれるもので、基本データ型ではnewを使いません。プログラムが勝手に箱を作ってくれるわけです。
しかしこのデータ型、プログラム言語によっては自分で作ることができるんです。この自分で作ったデータ型をユーザー定義型と呼びます。ユーザー定義型の中には、クラスと構造体があって….
と細かく話すときりがないので、今回はクラスにフォーカス。クラスとは、『基本データ型の変数と関数をまとめて一つのデータ型としてしまおう』、というものです。
例えば車について考えてみましょう。クラスを作るには、
車(クラス)はどんな値を持っているか・知っているべきか
車(クラス)にはどんな機能があるか
という問いが大切です。
じゃあ車が知っておかないといけないことは何?
例えば…
ガソリンの量
自分の速度
とかでしょうか。
車に必要な機能は何?
走る(アクセル)
ブレーキ
とかでしょう。細かいことを抜けば。
上記のデータと機能をまとめて新しい自作の箱、Carクラスを作ります。こんな感じで。
class Car
{
int speed; // 速度
int gas; // ガソリン量
// アクセル機能
void accelerate()
{
speed += 1; // speedに1を足す(加速)
}
// ブレーキ機能
void breaking()
{
speed -= 1 // speedから1を引く(減速)
}言語によって書き方はいろいろありますが概ね、似たようなものでしょう。
さてこのCar型の変数を作るとき、newの真価がまみえるわけです!
Car car1 = new Car(); // Car型の変数、car1を作るで!!見えますか!!すごいでしょ、new!!!
え…newの必要性がわからないって?
それは本筋に戻ってのお話。
(余談)クラスがないと大変だよ
とここで一息。だいぶ文章も長くなってますし、新しい知識盛りだくさんなんで。
さらっとクラスについて紹介しましたが、そもそもなんでクラス・構造体なんているんだって話しです。読者の中には
「基本データ型をまとめるだけなら、別に個別の変数があればいいのでは」
と思った方もいるのでは?
しかしこれは大きな勘違いです。残念ながら、人の脳みそはそこまで大きなものを扱えません。変数が増えてくると、何がなんだかわからなくなります。例えば、さきほどの車を複数台プログラムで扱ってみましょう。
int gas_car1 = 10;
int gas_car2 = 22;
int gas_car3 = 19;
int speed_car1 = 50;
int speed_car2 = 100;
int speed_car3 = 45;
int accelerate(int speed)
{
return speed + 1;
}
int breaking(int speed)
{
return speed - 1;
}試しに3台の車を扱うプログラムを書いてみました。クラスがないときは、こんな感じで各項目を書きまくらないといけないです。
しかも、変数の宣言のし忘れなどで、すべての車がspeedとgasを持っているとも限らない。めちゃくちゃ混乱します。
これがクラスを使うと….
Car car1 = new Car();
Car car2 = new Car();
Car car2 = new Car();だけで済むわけです。しかも設計図にクラスを使っているので、必ずspeedとgasは持っているし、加速と減速も確実に使えます。
こんな風にクラスがあることで、人間がコードを理解することが格段に簡単になります。
ただクラスが万能、というわけではないとは思います。実際、関数型言語と呼ばれる、全く違う発想を採用している言語なんかもあります。
ただ、便利なのは間違いないですね。
What is ”new"?
さて、いよいよnewの役割について解説したいと思います。ここで重要になってくるのが、スタックとヒープです。どちらもメモリの使い方の名前。先人たちが工夫を凝らした、素晴らしいものです。
まずスタック。データをFirst In First Outで整理するメモリの使い方。これは、箱を垂直に積み上げるイメージ。食器をしまう時とか、垂直に重ねますよね。アレをイメージしていただけると、ばっちりです。
どんどん上に重ねていくので、最初に入れたデータが最初に取り出されます。この仕組みをうまく使うと、小さなデータを高速で操作することができます。小さなデータ――つまり、基本データ型をスタックで管理します。
一方のヒープ。これは自由に確保できて、自由に使うことができる空間です。順番とか、大きさとか細かいことはともかく考えない。とりあえずしまい込んじゃえ!という発想。
大きなデータも扱えるのですが、アクセスしづらいのが難点。具体的にはポインター、すなわちデータがある住所を直接に指定することでしかアクセスできません。
クラスなどのユーザ定義型は、複数の基本データ型を組み合わせるので、大きなデータとなってしまいます。つまり、ヒープで管理します。
そしてスタックには、クラスのポインターを保管して、必要な時に取り出す。何か遠回りな感じがしますが、これでユーザ定義型を扱えます。いやー最初にクラスを考えた人、すごいなぁ。工夫が凝ってる。
このヒープに新しくデータの場所を確保するのが、new。
newの処理が行われると、ヒープの大きさを変更してデータを格納してくれるわけです。コンピュータの処理の中で、ヒープの大きさはメモリのポインタで管理しています。ヒープの一番後ろの場所をポインタで示していて、それより手前のメモリはいくらでも使ってOKという方式です。
行列の最後尾に立ってる看板みたいなものですね。この看板を後ろにずらして、データをしまう準備をしてくれるのが、newです。
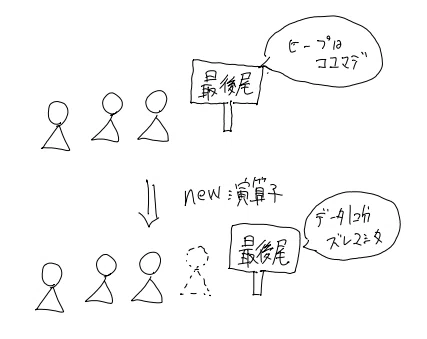
こうやって文章で書いてみると、そんなに凄そうには見えないな…. けど実装を自分でしてみると、これのありがたさが身に沁みます。何も考えずにクラスが使えますから!!
それに、この方法を考えた人のすごさも感じます。後知恵バイアス抜きでこれを編み出すのは、想像以上に難しい気が….
いやでも本当にすごいじゃん。メモリの中のことを(ある程度)考えなくて済むんですよ!!ありがたやー。
なんか文だとうまく伝えきれてないけど、これ僕的にはめちゃくちゃ革新的で、刺さりました。現場からは以上です。
この記事が気に入ったらサポートをしてみませんか?