なんちゃってデータフィッティング

現実には第1波が終息する117日目の5/31の国内の感染者は16,650人、死亡者は891人でした$${^{1)}}$$。事実を記述できなければ意味がありませんから、実測値にあうように$${S_0}$$、$${I_0}$$、$${Q_0}$$を変化させます。本当は数学的に最適化するのですが、「見た目」で適当に試行錯誤してあわせてみましょう。
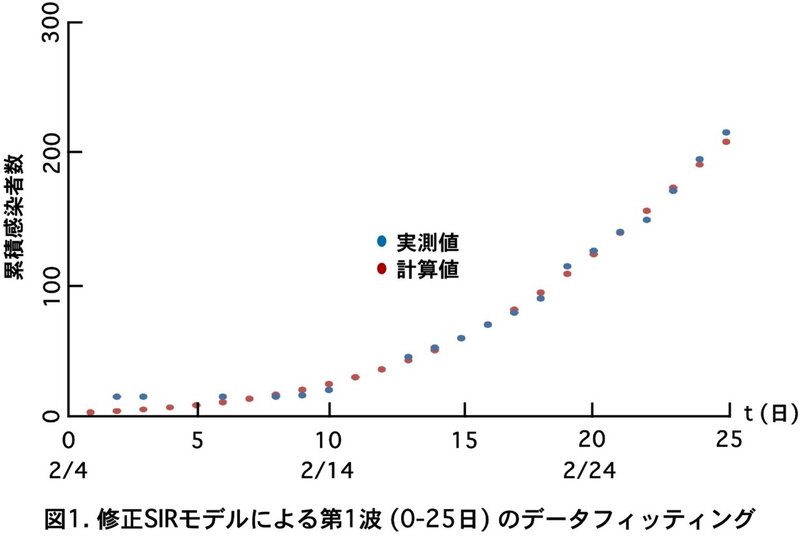
国内での最初の感染者は中国から1/6に帰国した男性で1/3に発熱しています。中国からの帰国者や中国人のツアーを世話したガイド等で感染者が出て2/6には国内の感染者が4人になり、2月中はじわじわ増えていきます。とりあえず2/4を$${t=0}$$として2/29($${t=25}$$)までのフィッティングを試みましょう。
厚労省の出している累積感染者はこのモデルでは感受性者の減少分$${S_0-S_t}$$に最初に流入した感染者$${I_0}$$を足したものですから、$${S_0-S_t+I_0}$$という項目を作ってエクセルで実測値と比較し、適当な$${I_0}$$、$${Q_0}$$とその集団の人数$${P}$$を試行錯誤で探します。日本人はもともと8割の耐性を持っていることを仮定していますから初期値は$${S_0=0.2P}$$、$${R_0=0.8P}$$です。すると$${Q_0=3.0}$$、$${P=2,000}$$、$${I_0=3}$$でほぼ実測値にのるようになります (図1)。
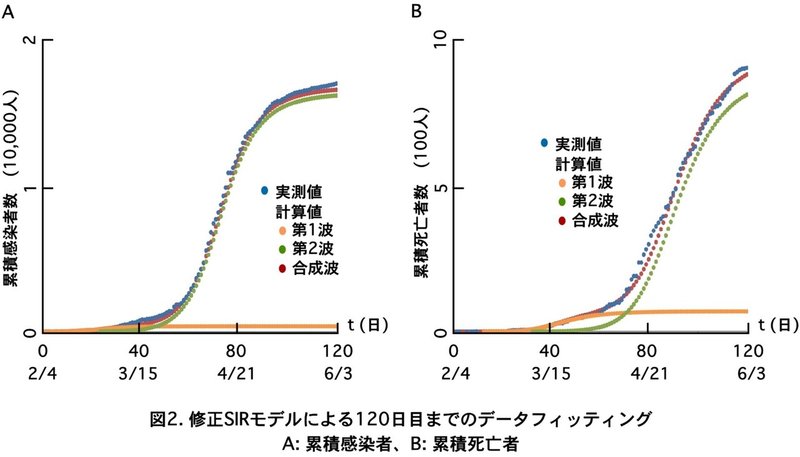
この波は3月に入れば下り坂になるはずですが、実際には3月になって感染者は急速に増えてきました。この第2波を$${t=120}$$すなわち6/3までのデータを元にフィッティングしてみます。第2波は第1波のフィッティングが破綻してきた$${t=24}$$を初日とします。感染者は第1波の感染者との合計になります。この項目をエクセルに作って実測値と比較します。
すると$${P=90,000}$$、$${Q_0=2.5}$$、$${I_0=10}$$でほぼ実測値にのるようになります (図2A)。
死亡者のフィッティングもしてみましょう。感染者数すなわちPCR陽性者は検出率や感度で数値が動くので死亡者数のほうがより信頼度の高いデータとなるでしょう。
回復者のうちの一定の割合で死亡すると仮定します。このモデルの回復者$${R}$$にはもともと耐性を持っていた人が含まれますから、$${t}$$日後に病気から回復した累積人数は$${R_t-R_0}$$、死亡者$${D}$$は致死率を$${s}$$とすると$${D=(R_t-R_0)s}$$となります。
ただし感染してから回復するまでの期間よりも死亡するまでの期間のほうが長くなるでしょうからデータにあうように遅延を入れます。例えば10日間の遅延ならば3/10の死亡人数は3/1の累積回復人数に致死率$${s}$$をかけた値になります。
実際のデータと比べて感染者数と同じ要領で致死率と遅延日数を決めると、第1波と第2波の致死率は0.18と0.054、遅延日数は9日と5日でデータにあうようになります (図2B)。
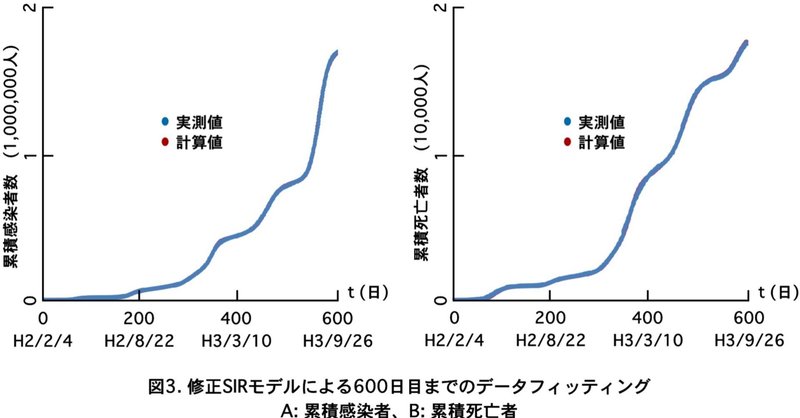
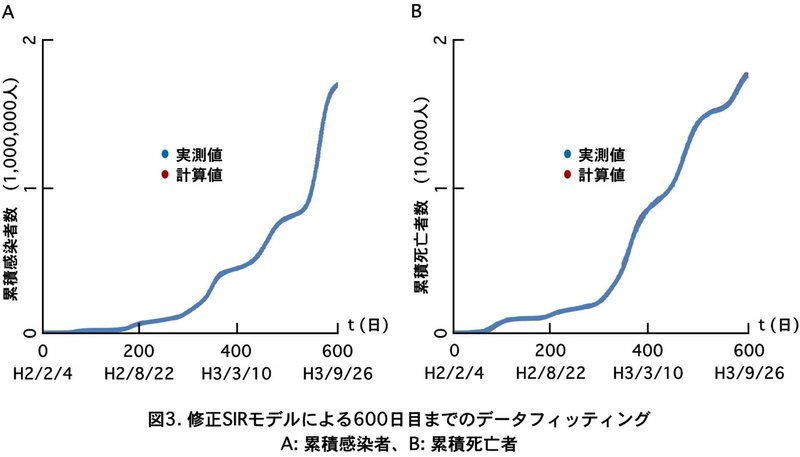
このようにして厚労省が出しているこれまでの感染データ$${^{1)}}$$をもとに実測値に合わなくなるたびに新たな波を想定して合成していくとH4/9/26 ($${t=600}$$)までに10個の波がきていることが予想できました (図3)。実測値と計算値はほぼ重なっていることがわかります。
世間でいう第1波はこのモデルでは第1,2波の合成波、第2波は第3波、第3波は第4-7波の合成波、第4波は第8,9波の合成波、第5波は第10波に相当します。
厚労省の生データをもとに単純な「足し算の積み重ね」と「見た目によるデータフィッティング」で感染曲線を構築してみました。高等数学など使わない「なんちゃって感染モデル」ですが驚くほど感染者や死亡者の変化をうまく表現できています。
モデルの善し悪しは実測値に適合しているかということで評価できます。現実をうまく表現できるモデルなら難しい数学を使っても現実を表現できないモデルよりも数段良いモデルと言えます。むしろ、きちんと表現できれば単純なほど良いのです。このことはしばしば「オッカムの剃刀」に準えられています$${^{2)}}$$。
$${^{1)}}$$https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000121431_00086.html
$${^{2)}}$$https://ja.wikipedia.org/wiki/オッカムの剃刀