Windows PCでStreamDiffusionを利用する手順

Last update 1-6-2024
※(1-6-2024)RealTimeScreenバイナリ版の情報を追加しました。pnpmのインストールコマンドが抜けていたので追加しました。
※(1-4-2024)アップデートに伴い、4.に「Real-Time Img2Img Demo」を、7-5. に「アップデートの手順」を、それぞれ追加しました。また、Demoの実行手順が若干変更されました。
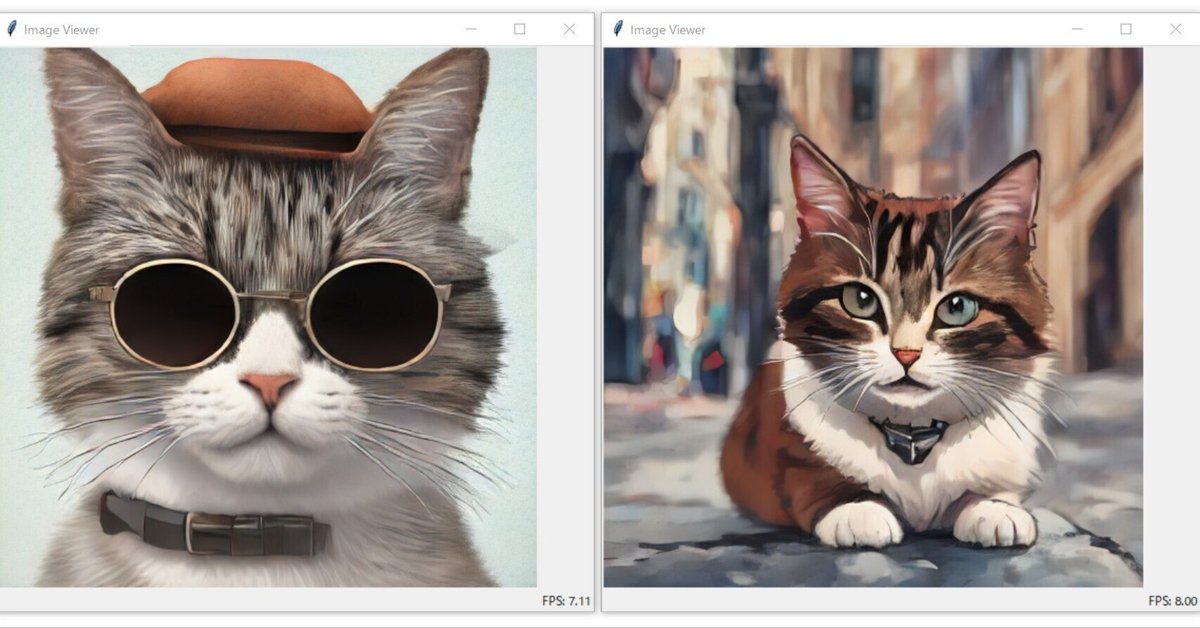
※タイトル画像は「optimal-performance」を2つ同時に実行しています。右側は「 --prompt "close-up, anime, cat, downtown street"」を追加しました。
※手っ取り早く成果を確認したい場合は、サンプルプログラムの「screen」「optimal-performance」や「Demoプログラム」を実行してください。
▼ 1. 本記事について
1-1. 概要
StreamDiffusionはリアルタイムの高速な画像生成を目的としたパイプラインです。Stable Diffusion、SD-Turbo、TensorRT、LCM-LoRAを組み合わせた上で、処理が高速化された専用のプログラムを使用します。
本記事ではStreamDiffusionをインストールして、サンプルプログラムやDemoプログラムを実行する手順を説明します。次に設定変更について簡単に説明します。さらに第三者によるプログラムを紹介した後、アンインストール等の情報を記載します。
1-2. 公式リポジトリ、論文、解説動画等
StreamDiffusion
https://github.com/cumulo-autumn/StreamDiffusion
README
https://github.com/cumulo-autumn/StreamDiffusion/blob/main/README.md
StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation
https://arxiv.org/abs/2312.12491
【リアルタイム画像生成】 StreamDiffusion、著者が使い方解説してみた 【秒間100枚以上】
https://www.youtube.com/watch?v=CnVbZv-6lGE
大変お待たせしました!本日arXivにて公開された私達の論文「StreamDiffusion」について
— あき先生 / Aki (@cumulo_autumn) December 21, 2023
GitHubリポジトリの方も公開しました!100fps以上出すことも可能です!
詳しくは論文、リポジトリのREADMEをご確認ください!#StreamDiffusion
論文:https://t.co/4zQKFyPKgj
GitHub:https://t.co/U1ufvRR9cq https://t.co/5hO1UXT4Ya
▼ 2. インストール
本記事では、Python 3.10、CUDA Toolkit 11.8、Gitが導入済みであることを前提としています。また、VRAM 12GBのRTX 3060で動作確認を行いました。VRAMがこれより少ない場合、一部または全てのプログラムが動作しない可能性があります。おそらく8GB以上が推奨されます。
以降の手順は執筆時のものであり、変更される場合があります。リポジトリのREADMEも参照してください。
2-1. インストール1
作業ディレクトリを「C:\aiwork」としていますので、適宜読み替えてください。コマンド プロンプトを開いて、ディレクトリ「C:\aiwork\StreamDiffusion」が無い状態で下記のコマンドを順に実行してください。
cd \aiwork
git clone https://github.com/cumulo-autumn/StreamDiffusion.git
cd StreamDiffusion
python -m venv venv
venv\Scripts\activate
(ここで行頭に (venv) が付いていることを確認する)
python -m pip install --upgrade pip2-2. インストール2
下記のコマンドを実行してください。大きめのパッケージがダウンロードされます。
pip install torch==2.1.0 torchvision==0.16.0 xformers --extra-index-url https://download.pytorch.org/whl/cu1182-3. インストール3
下記のいずれかのコマンドを実行してください。なお、StreamDiffusionの作者は最新版を推奨しています。
(最新版をダウンロードする場合)
pip install git+https://github.com/cumulo-autumn/StreamDiffusion.git@main#egg=streamdiffusion[tensorrt]
(リリース版をダウンロードする場合)
pip install streamdiffusion[tensorrt]2-4. インストール4
下記のコマンドを実行してください。大きめのパッケージがダウンロードされます。
python -m streamdiffusion.tools.install-tensorrt2-5. インストール5
リリース版の場合のみ、下記のコマンドを実行してください。なお、既にインストール済みの場合は「Requirement already satisfied: pywin32…」と表示されます。誤って実行しても害はありません。
pip install pywin322-6. インストール6(オプション)
下記は開発者向けですので、実行しなくても構いません。
python setup.py develop easy_install streamdiffusion[tensorrt]
python -m streamdiffusion.tools.install-tensorrt2-7. コマンド プロンプトの終了
今まで使用していたコマンド プロンプトを閉じてください。手順を説明する都合上、続きは新規のウインドウで行っていただきたいと思います。
2-8. ディレクトリ名の変更
一部のプログラムでcuDNNの問題が発生したので、対応方法を説明します。「StreamDiffusion\venv\Lib\site-packages\nvidia\」にある「cudnn」ディレクトリの名前を、「cudnn.bak」等に変更してください。これによって参照されるcuDNNの場所が変更されて、エラーのダイアログが出現しなくなると思います。
▼ 3. サンプルプログラム
下記のドキュメントを参考に、様々なサンプルプログラムを実行してみます。おすすめは「screen」と「optimal-performance」です。順番に実行する必要はありませんので、お好みで選んでください。ただし、3-1.だけは最初に忘れずに実行してください。
StreamDiffusion Examples
https://github.com/cumulo-autumn/StreamDiffusion/tree/main/examples
なお、TensorRTを使用する場合は専用のモデルを作成するため、下記のような表示でしばらく停止します。作成済みの場合はスキップされます。
[I] Building engine with configuration:
Flags | [FP16]
Engine Capability | EngineCapability.DEFAULT
Memory Pools | [WORKSPACE: 4239.00 MiB, TACTIC_DRAM: 12287.38 MiB]
Tactic Sources | []
Profiling Verbosity | ProfilingVerbosity.DETAILED
Preview Features | [FASTER_DYNAMIC_SHAPES_0805, DISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805]使用方法は「 --help」を付けると表示されますので覚えておいてください。
python screen/main.py --help3-1. 実行前の準備
新規のコマンド プロンプトを開いたら、最初に下記のコマンドを順番に実行してください。今までの手順で構築した環境に切り替え、サンプルプログラムのディレクトリに移動します。
cd \aiwork\StreamDiffusion
venv\Scripts\activate
(ここで行頭に (venv) が付いていることを確認する)
cd examples3-2. screenの実行
デスクトップの指定した領域をキャプチャして入力に使用し、リアルタイムでimg2imgによる生成を行うプログラムです。実行中はCPUの負荷が高く、こちらの性能も要求されるかもしれません。
初回のみ、下記のコマンドを順に実行してください。必要なパッケージがインストールされます。なお、筆者の環境ではTritonをインストールしても機能しませんでした。無くても動作するようですので、インストールしない場合は2行目を省略してください。
pip install -r screen/requirements.txt
pip install https://huggingface.co/r4ziel/xformers_pre_built/resolve/main/triton-2.0.0-cp310-cp310-win_amd64.whlscreenを実行するため、下記のコマンドを実行してください。
python screen/main.py半透過のウインドウが出現しますので、キャプチャを行いたい箇所へ移動してからEnterを押してください。ただし、筆者の環境では設定座標がずれる現象を確認しています。

半透過のウインドウが消えて、Image Viewerのウインドウが出現します。特定の領域を入力に用いてリアルタイム生成した結果が、Image Viewerに表示されます。ウインドウを動かしたり、動画を表示させたりしてみてください。
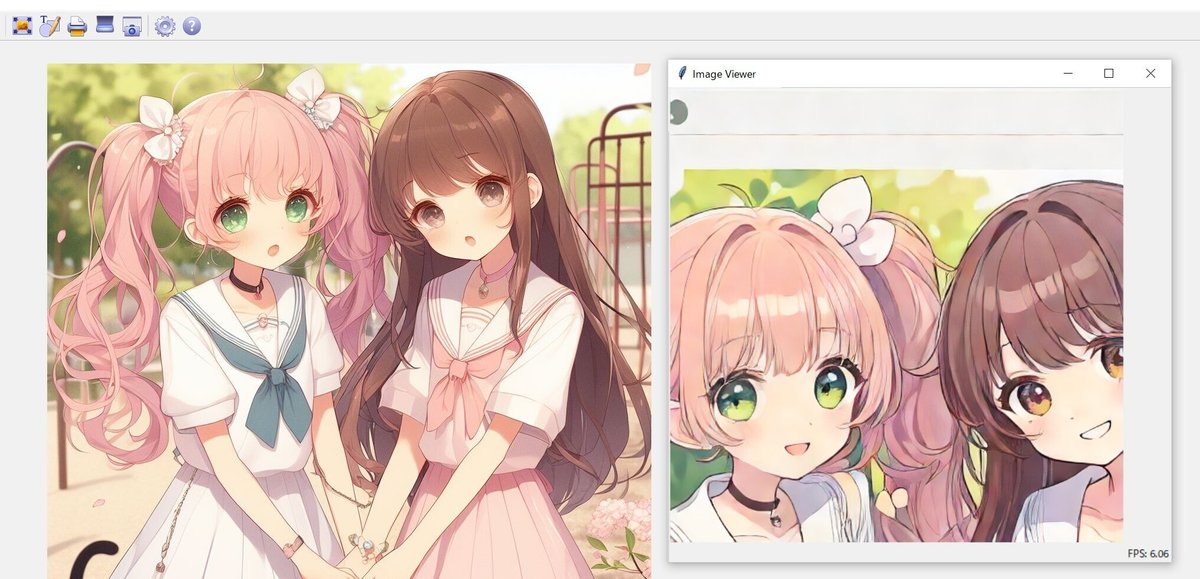
終了したい時は、コマンド プロンプトのウインドウでCtrl+Cを押してください。間違えてImage Viewerのウインドウを閉じてしまった場合は、コマンド プロンプトのウインドウを閉じてください(少し時間がかかります)。
TensorRTを使用する場合は、下記のようにオプションを付けて実行してください。初回はTensorRT専用のモデルを作成するため、実行開始までしばらくかかります。
python screen/main.py --acceleration tensorrtTensorRTを使用しない場合に比べて、2倍前後の速度が出るようです。
3-3. benchmarkの実行
性能を測定するためのベンチマークプログラムです。下記のコマンドを実行してください。「single.py」のほかに「multi.py」があり、前者はシングルバッチ処理、後者はRTX4090に最適化されたマルチバッチ処理とみられます。通常は前者を選択してください。
python benchmark/single.py少し待つとプログレスバーが表示され、100%になると結果が表示されます。
100%|████████████████████████████████████████████████████████████████████████████████| 100/100 [00:22<00:00, 4.50it/s]
Average time: 215.93773559570312ms
Average FPS: 4.630964556710387
Max FPS: 4.733658059656689
Min FPS: 4.200737513516701
Std: 0.09281142820303803TensorRTを使用する場合は、下記のようにオプションを付けて実行してください。初回はTensorRT専用のモデルを作成するため、実行開始までしばらくかかります。
python benchmark/single.py --acceleration tensorrtプログレスバーが100%になると結果が表示されますので、TensorRTを使用しなかった場合と比べてみてください。
100%|████████████████████████████████████████████████████████████████████████████████| 100/100 [00:13<00:00, 7.60it/s]
Average time: 124.47206359863281ms
Average FPS: 8.033931237972855
Max FPS: 8.220270537913702
Min FPS: 7.763662255577496
Std: 0.100697568381995443-4. optimal-performanceの実行
SD-TurboモデルとTensorRTを用いて、リアルタイムでtxt2imgによる生成を行って連続表示するプログラムです。下記のコマンドを実行してください。「single.py」のほかに「multi.py」があり、前者はシングルバッチ処理、後者はRTX4090に最適化されたマルチバッチ処理を行います。通常は前者を選択してください。
python optimal-performance/single.py初回はTensorRT専用のモデルを作成するため、実行開始までしばらくかかります。
準備が完了するとImage Viewerのウインドウが出現して、帽子とサングラスの猫が生成され続けます。
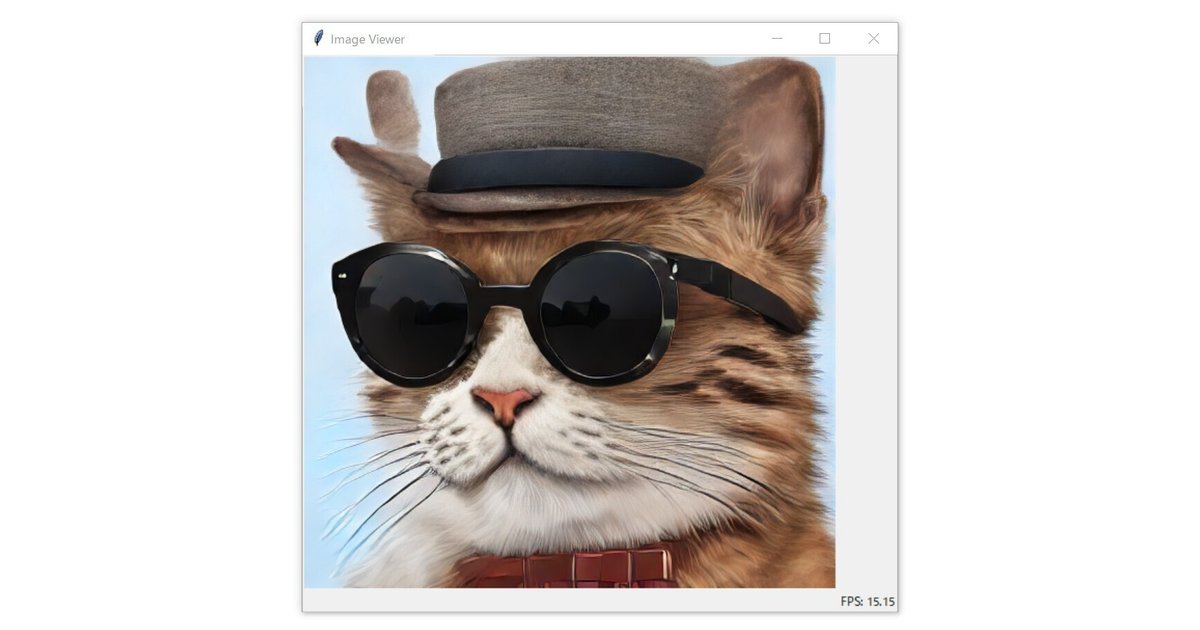
プロンプトを変更して、生成される内容を変えることができます。下記はその一例です。
python optimal-performance/single.py --p "close-up, anime, cat, downtown street"終了したい時は、コマンド プロンプトのウインドウでCtrl+Cを押してください。間違えてImage Viewerのウインドウを閉じてしまった場合は、コマンド プロンプトのウインドウを閉じてください(少し時間がかかります)。
3-5. img2imgの実行
指定した画像のファイルやディレクトリを指定して、img2imgによる生成を行いファイルに保存します。試してみたい方は、下記を参考に実行してください。なお、手元に適当な画像がない場合は、次項のTxt2Imgを先に実行する方法もあります。
本記事では、多数の生成を行って実行時間を計ることを目標とします。まずは、入力画像のみが入ったディレクトリ「C:\aiwork\i2i_in」と、出力先のディレクトリ「C:\aiwork\i2i_out」を作成しました。
それから、入力用に100枚の画像を生成しました。参考まで、生成にかかった時間は9分7秒です。パラメーターは画像の説明に記載しています。

Negative prompt: (worst quality, low quality:1.2), teeth,
Steps: 28, Sampler: Euler a, CFG scale: 7, Seed: 2974552347, Size: 512x512, Model hash: e2c364c195, Model: flexdreamhk_v20, VAE hash: f6dbafc61e, VAE: sr_SDv2vae_kl-f8anime2.safetensors, Clip skip: 2, ENSD: 31337, Version: v1.6.1
最初に、「single.py」を使用して1枚だけ生成してみます。コマンドは下記のとおりです。ファイルのパスは適宜変更してください。
python img2img/single.py --i C:/aiwork/i2i_in/test.png --o C:/aiwork/i2i_out/test1.png次にプロンプトを指定してみます。「 --p "1girl, smile :d, brown pigtail hair, white frill dress, red eyes, farm rural village, spring flower, meadow, distant mountain"」を追加し、出力ファイル名を変更しました。
python img2img/single.py --i C:/aiwork/i2i_in/test.png --o C:/aiwork/i2i_out/test2.png --p "1girl, smile :d, brown pigtail hair, white frill dress, red eyes, farm rural village, spring flower, meadow, distant mountain"次はTensorRTを使用してみます。「 --acceleration tensorrt」を追加し、出力ファイル名を変更しました。初回はTensorRT専用のモデルを作成するため、実行開始までしばらくかかりします。
python img2img/single.py --i C:/aiwork/i2i_in/test.png --o C:/aiwork/i2i_out/test3.png --p "1girl, smile :d, brown pigtail hair, white frill dress, red eyes, farm rural village, spring flower, meadow, distant mountain" --acceleration tensorrtここまでで3枚の画像が生成されました。ぱっと見では分かりづらいですが、TensorRTの有無で出力が少しだけ異なっています。

正しく動作しているようなので、次は連続で100枚の生成を行います。コマンドの「single.py」を「multi.py」に、入出力先をディレクトリに、それぞれ変更しました。なお、出力先の「--output-dir」は「--output」の誤りのようです。本記事では「--i」と「--o」に統一しています。
まずはTensorRTを使用しない場合です。コマンドの実行開始から終了まで約48.9秒かかりました。また、最初と最後のファイルの更新日時の差は約32.82秒で、99で割ると1枚あたり約0.33秒、逆数を取って1秒あたり約3.02枚となりました(プログラム開始後の準備時間を除いた値)。
python img2img/multi.py --i C:/aiwork/i2i_in --o C:/aiwork/i2i_out --p "1girl, smile :d, brown pigtail hair, white frill dress, red eyes, farm rural village, spring flower, meadow, distant mountain"最後にTensorRTを使用した場合です。TensorRT専用のモデルが作成済みの場合、コマンドの実行開始から終了まで約40.2秒かかりました。また、最初と最後のファイルの更新日時の差は約22.66秒で、99で割ると1枚あたり約0.23秒、逆数を取って1秒あたり約4.37枚となりました(プログラム開始後の準備時間を除いた値)。
python img2img/multi.py --i C:/aiwork/i2i_in --o C:/aiwork/i2i_out --p "1girl, smile :d, brown pigtail hair, white frill dress, red eyes, farm rural village, spring flower, meadow, distant mountain" --acceleration tensorrt次項のtxt2imgと比較すると、ファイルの入力がボトルネックになっている可能性が考えられます。
3-6. txt2imgの実行
プロンプトを指定して、txt2imgによる生成を行いファイルに保存します。試してみたい方は、下記を参考に実行してください。
本項では、多数の生成を行って実行時間を計ることを目標とします。出力先のディレクトリは「C:\aiwork\i2i_out」を使い回しました(無計画)。
最初に、「single.py」を使用して1枚だけ生成してみます。出力ファイルのパスは適宜変更してください。
python txt2img/single.py --o C:/aiwork/i2i_out/test4.png --p "1girl, smile :d, brown pigtail hair, white frill dress, red eyes, downtown street"次はTensorRTを使用してみます。「 --acceleration tensorrt」を追加し、出力ファイル名を変更しました。初回はTensorRT専用のモデルを作成するため、実行開始までしばらくかかりします。
python txt2img/single.py --o C:/aiwork/i2i_out/test5.png --p "1girl, smile :d, brown pigtail hair, white frill dress, red eyes, downtown street" --acceleration tensorrt正しく動作しているようなので、次は「multi.py」を使用して100枚の生成を行います。注意点として、こちらは生成時に25GB程度のVRAMを消費しました。他のサンプルプログラム同様、RTX4090に最適化されている可能性が考えられます。
まずはTensorRTを使用しない場合です。コマンドの実行開始から終了まで、約64.4秒かかりました。また、最初と最後のファイルの更新日時の差は約10.01秒で、99で割ると1枚あたり約0.10秒、逆数を取って1秒あたり約9.89枚となりました(プログラム開始後の準備時間を除いた値)。
python txt2img/multi.py --f 100 --o C:/aiwork/i2i_out --p "1girl, smile :d, brown pigtail hair, white frill dress, red eyes, downtown street"最後にTensorRTを使用した場合です。筆者の環境では、このケースのみ実行のたびにモデルの作成が行われて、赤字のエラーも表示されました。ただし、そのまま待っていれば実行されます。
python txt2img/multi.py --f 100 --o C:/aiwork/i2i_out --p "1girl, smile :d, brown pigtail hair, white frill dress, red eyes, downtown street" --acceleration tensorrtコマンドの実行開始から終了まで約203秒かかりました。また、最初と最後のファイルの更新日時の差は約10.11秒で、99で割ると1枚あたり約0.10秒、逆数を取って1秒あたり約9.79枚となりました(プログラム開始後の準備時間を除いた値)。
TensorRTを使用しても速度が上がらなかった原因は、VRAM不足とみられます。TensorRTを使用してもしなくても、生成時は下記の画像のような状態になりました。

なお、「--f」の値を下げれば良いというものではないようです。筆者の環境では「[W] UNSUPPORTED_STATE」の表示を最後に、進行しなくなってしまう現象を確認しています。この状態ではコマンド プロンプトを閉じるしかありません。
[I] Building engine with configuration:
Flags | [FP16]
Engine Capability | EngineCapability.DEFAULT
Memory Pools | [WORKSPACE: 3305.00 MiB, TACTIC_DRAM: 12287.38 MiB]
Tactic Sources | []
Profiling Verbosity | ProfilingVerbosity.DETAILED
Preview Features | [FASTER_DYNAMIC_SHAPES_0805, DISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805]
[W] UNSUPPORTED_STATESkipping tactic 0 due to insufficient memory on requested size of 11056491520 detected for tactic 0x0000000000000000.Try decreasing the workspace size with IBuilderConfig::setMemoryPoolLimit().
3-7. vid2vidの実行
動画を指定して、vid2vidによる生成を行いファイルに保存します。試してみたい方は、下記を参考に実行してください。
初回のみ、下記のコマンドを実行してください。必要なパッケージがインストールされます。
pip install -r vid2vid/requirements.txt変換元の動画ファイルを用意してください。下記のファイルを使用していただいても構いません。筆者が撮影、加工したものですのでご安心ください。転載は自己責任において自由としますが、本記事を紹介いただけると助かります。
vid2vidを実行するため、下記のコマンドを実行してください。ファイルのパスやプロンプトは適宜変更してください。なお、vid2vidでプロンプトにカンマを入れたい場合は、直前に「\(半角の¥)」を付ける必要があるようです(付けないとエラーが出ます)。
python vid2vid/main.py --i C:/aiwork/riddi0908-20231229a.mp4 --o C:/aiwork/output.mp4 --p "sheep standing in a meadow"実行中はPC全体の動作が重くなる場合があります。実行が完了したら、生成された動画を確認してみてください。

▼ 4. Demoプログラム
下記のドキュメントを参考に、Demoプログラムを実行してみます。
Real-Time Txt2Img Demo
https://github.com/cumulo-autumn/StreamDiffusion/tree/main/demo/realtime-txt2img
Real-Time Img2Img Demo
https://github.com/cumulo-autumn/StreamDiffusion/tree/main/demo/realtime-img2img
4-1. Node.jsのインストール(初回のみ)
DemoプログラムはNode.jsが必要です。https://nodejs.org/ にアクセスして、「**.** LTS」のボタンからダウンロードしてください。ダウンロードしたファイルを実行して進めるだけでインストールできます。途中でチェックを入れたりする必要はありません。
プログラムは2つありますので、下記のとおりに進んでください。
Real-Time Txt2Img Demo → 4-2.へ
Real-Time Img2Img Demo → 4-5.へ
4-2. (Txt2Img)実行前の準備
新規のコマンド プロンプトを開いたら、最初に下記のコマンドを順番に実行してください。今までの手順で構築した環境に切り替え、Demoプログラムのディレクトリに移動します。
cd \aiwork\StreamDiffusion
venv\Scripts\activate
(ここで行頭に (venv) が付いていることを確認する)
cd demo\realtime-txt2img4-3. (Txt2Img)セットアップ(初回/更新時)
初回またはStreamDiffusionを更新した場合は、下記のコマンドを順番に実行してください。
npm install -g pnpm
pip install -r requirements.txt
cd frontend
pnpm i
pnpm run build
cd ..\4-4. (Txt2Img)実行
下記のコマンドを実行してください。
python main.py下記のような表示が出たら、Webブラウザで http://127.0.0.1:9090/ へアクセスしてください。9090はポート番号ですので、もし異なる数値の場合は適宜変更してください。
INFO: Uvicorn running on http://127.0.0.1:9090 (Press CTRL+C to quit)下部の入力欄にプロンプトを入力すると、リアルタイムで画像が生成されます。プロンプトを書き換えると更新されます。言葉では表現しづらいので、実際に試してみてください。

終了したい時は、コマンド プロンプトのウインドウでCtrl+Cを押してください。
4-5. (Img2Img)実行前の準備
新規のコマンド プロンプトを開いたら、最初に下記のコマンドを順番に実行してください。今までの手順で構築した環境に切り替え、Demoプログラムのディレクトリに移動します。
cd \aiwork\StreamDiffusion
venv\Scripts\activate
(ここで行頭に (venv) が付いていることを確認する)
cd demo\realtime-img2img4-6. (Img2Img)セットアップ(初回/更新時)
初回またはStreamDiffusionを更新した場合は、下記のコマンドを順番に実行してください。
pip install -r requirements.txt
cd frontend
npm i
npm run build
cd ..\4-4. (Img2Img)実行
下記のコマンドを実行してください。初回はTensorRT専用のモデルを作成するため、実行開始までしばらくかかりします。
python main.py --acceleration tensorrt下記のような表示が出たら、Webブラウザで http://127.0.0.1:7860/ へアクセスしてください。7860はポート番号ですので、もし異なる数値の場合は適宜変更してください。
INFO: Uvicorn running on http://0.0.0.0:7860 (Press CTRL+C to quit)開始するには「Start」をクリックしてください。下部の入力欄に入っているプロンプトを変更すると、リアルタイムで反映されるようです。筆者の環境にはWebカメラが無いため、動作の確認はできませんでした。
終了したい時は、コマンド プロンプトのウインドウでCtrl+Cを押してください。
▼ 5. サンプルプログラムの設定変更
サンプルプログラムはデフォルトの設定が組み込まれており、設定を行わなくてもとりあえず動作するようになっています。本項では設定の一部を変更してみた例を紹介します。
なお、設定可能な項目はプログラムによって異なりますので注意してください。詳細は「 --help」のみを付けて実行することで確認できます。
python screen/main.py --help5-1. プロンプトの変更
プロンプトは、生成する画像の内容を指定する文字列です。適したプロンプトを与えることで内容を変えたり出力が改善したりします。
例えば、screenのソースを見ると下記の内容が見つかります。メガネをかけた出力になりやすい理由は、デフォルトのプロンプトに「thick glasses」が入っているためです。
prompt: str = "1girl with brown dog hair, thick glasses, smiling",
negative_prompt: str = "low quality, bad quality, blurry, low resolution",試しに、下記の内容でscreenを実行してみます。TensorRTを利用する場合は「 --acceleration tensorrt」を付けてください。
python screen/main.py --p "1girl with red eyes, open mouth"瞳が赤くなって口を開きました。img2imgなので、必ずしも期待したとおりの変化になるとは限らない点に注意してください。

optimal-performanceも改めてプロンプトを変更してみます。ただし、こちらのみ特殊なモデル(SD-Turbo)を使用しているため、スタイルの変更はあまり期待しない方が良いでしょう。
python optimal-performance/single.py --p "flat anime style, face close-up, little 1girl, smile, dress, castle"
5-2. モデルの変更
optimal-performance以外のプログラムは、デフォルトで使用するモデルが「KBlueLeaf/kohaku-v2.1」に設定されています。これを任意のStable Diffusion 1.5モデルに変更してみます。なお、LoRAの適用も可能です。
モデルを変更する場合は、DiffusersのIDか、safetensors形式のファイルのパスを指定してください。また、TensorRTを利用したい場合は初回の変換に時間を要するため、予め「 --acceleration tensorrt」を付けずに実行して動作を確認してください。
ここではモデルに「ToraFurryMix v2.0」を使用して、猫耳やマズル等のプロンプトを指定します。モデルのファイルのパスは適宜変更してください。
python screen/main.py --p "furry, kitten girl, cat ears, muzzle" --m "C:/aiwork/sd-data/sdv1/models/ToraFurryMix_v20.safetensors"img2imgなので、必ずしも期待したとおりの変化になるとは限らない点に注意してください。

筆者が推奨するStable Diffusion 1.5モデルについては、下記の記事を参照してください。これらはNAIリークモデルの成分を含まないか、含んでいる可能性が低いです。
実は、optimal-performanceもモデルの変更が可能です。しかし、SD-Turboのモデルが他には存在しないため、どのモデルを使用しても良好な出力は得られないと思います。
▼ 6. StreamDiffusionの活用
StreamDiffusion本体にはサンプル的なプログラムしか用意されていないため、それ以上のことを行うには改造するか自作するしかありません。既にStreamDiffusionを利用した取り組みが進められており、いくつかはコードが公開されています。中級者以上となりますが、挑戦してみるのも良いでしょう。
6-1. 基本コードやカスタマイズの解説
下記の記事は、StreamDiffusionをさらに使いこなす上で参考になります。
金曜日深夜からの作業をまとめました。地味な作業でしたがそれなりに成果はありました。コードも公開しています。せひ読んでください。
— ゆずき (@uzuki425) December 27, 2023
100fps超え画像生成StreamDiffusionのデモに飽きたら次に進もう。Wrapperを使わずに動かすコツ公開|めぐチャンネル @uzuki425 #note https://t.co/Ub6YVqNc02
6-2. カメラ映像の変換
下記の記事は、Webカメラの映像をリアルタイムで変換する試みです。
キャプション画像変変更。
— ゆずき (@uzuki425) December 29, 2023
WebCAMからリアルタイムでキャラに変身できる簡単なコードを公開しています。座っていても立っていても連続変換#StreamDiffusion
リアル画像をキャプチャしてキャラ絵にリアルタイム変換-StreamDiffusionの凄さ|めぐチャンネル @uzuki425 #note https://t.co/dTvCNdn7Xt
6-3. RealTimeScreen
指定領域をキャプチャしながらリアルタイム生成を行う、お絵描きの補助等に使えるプログラムが公開されています。バイナリ版があるので、比較的簡単に導入できます。
手描きお絵描きにも活用できる?生成AIキャプチャアプリ「RealTimeScreen」公開|とりにく @tori29umai #note https://t.co/Y1CJId1ZyR
— とりにく (@tori29umai) January 6, 2024
オープンソースなフリーソフトを公開&解説記事を書いたので是非お使い下さい! pic.twitter.com/vWO6r1QLH7
#StreamDiffusion を用いた高速i2iキャプチャアプリ
— とりにく (@tori29umai) December 26, 2023
で『RealTimeScreen』公開しました!
リアルタイムで自分が描いた絵を見本にAIが生成するお見本を見ながら(生成した画像を取りいれながら)お絵描きできます
TensorRTにも一応対応。動画は20倍速。
等速動画はリプツリーにhttps://t.co/DGZqzksHrs pic.twitter.com/QZ7cmUo2RM
▼ 7. メモ
データの削除、アンインストール、アップデートの手順です。
7-1. pipのキャッシュを削除する
pipコマンドでインストールしたパッケージは、PC内に保存されています。再利用時はダウンロードの手間が省けて便利ですが、例えばPyTorchは容量が2GB以上と大きいため、気になる方もいらっしゃるかと思います。
パッケージのキャッシュを削除するには「pip cache purge」のコマンドを実行するか、「%LOCALAPPDATA%\pip\Cache」の中身を手動で削除してください。なお、必要時は再度ダウンロードされます。
7-2. Diffusersのキャッシュを削除する
プログラム実行中にHuggingFaceからダウンロードした、Diffusers形式のモデルを含むデータがPC内に保存されています。これらは削除しない限り残りますので、適宜整理すると良いでしょう。なお、必要時は再度ダウンロードされます。
保存場所は「%USERPROFILE%\.cache\huggingface\hub」です。下記画像にある「models…」ディレクトリはStreamDiffusionに関連していると思われますので、利用中はそのままにすることをおすすめします。

7-3. TensorRT形式のモデルを削除する
StreamDiffusionで使用したTensorRT専用モデルもPC内に保存されています。「StreamDiffusion\examples\engines」にありますので、名前などを見ながら残すかどうかを決めてください。

7-4. StreamDiffusionを削除する
StreamDiffusionを削除する場合は、必要なファイルがあれば移動してから「StreamDiffusion」ディレクトリを削除してください。また、前項のキャッシュ等も不要であれば削除してください。
7-5. アップデートの手順
未確認ながら、下記の手順にてStreamDiffusionの更新ができます。コマンド プロンプトを開いて下記のコマンドを順に実行してください。最初の行は適宜読み替えてください。
cd \aiwork\StreamDiffusion
git pull
venv\Scripts\activate
(ここで行頭に (venv) が付いていることを確認する)下記のいずれかのコマンドを実行してください。
(最新版をダウンロードする場合)
pip install git+https://github.com/cumulo-autumn/StreamDiffusion.git@main#egg=streamdiffusion[tensorrt]
(リリース版をダウンロードする場合)
pip install streamdiffusion[tensorrt]下記のコマンドを実行してください。もしかすると必要ないかもしれません。
python -m streamdiffusion.tools.install-tensorrt開発者向けの場合は2-6.も実行してください。
Demoプログラムを実行する場合は、手順にあるセットアップも再度実行してください。
▼ 8. その他
私が書いた他の記事は、メニューよりたどってください。
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。
この記事が気に入ったらサポートをしてみませんか?