
LLM-jp-13B, LLMプロンプト技術まとめ, etc - Generative AI 情報共有会 #11

今週、11月7日(火)にZENKIGEN社内で実施の「Generative AI最新情報共有会」でピックアップした生成AI関連の情報を共有します(OpenAI DevDayの内容は間に合わなかったので後日機会があれば…)。
この連載の背景や方向性に関しては 第一回の記事 をご覧ください。
LLM-jpから、13B LLM公開
LLM-jp: 国立情報学研究所(NII)が主催し、日本の錚々たる研究者が集まり日本語LLMの構築を目指す会。2023年5月15日にスタート(第一回勉強会開催)。
LLM の研究開発は日進月歩ではありますが、現状では GPT-3 級 (175B) のモデルにおいて創発が起こる可能性も示唆されており、知識蒸留などによる小さなモデルの検討はその後取り組むべきことと言えます。日本においても少なくともこのスケールのモデルを構築し、原理解明に取り組む体制を作る必要があります。
LLM 研究進捗のスピード感を考えると、研究開発プログラムのトップダウンな設計は必ずしも最適ではありません。最も重要なことは土壌を作ること、すなわち、計算基盤と言語モデル構築基盤(エンジニア等の人材を含む)を整備し、国内外の研究者が様々な試行錯誤を行う環境を構築することです。
「LLM-jp-13B」モデルの公開。
同モデルはLLM研究開発としては初期段階のものであり、モデルの性能を示す評価値はこれまでに国内で公開されたモデルと比較して同程度
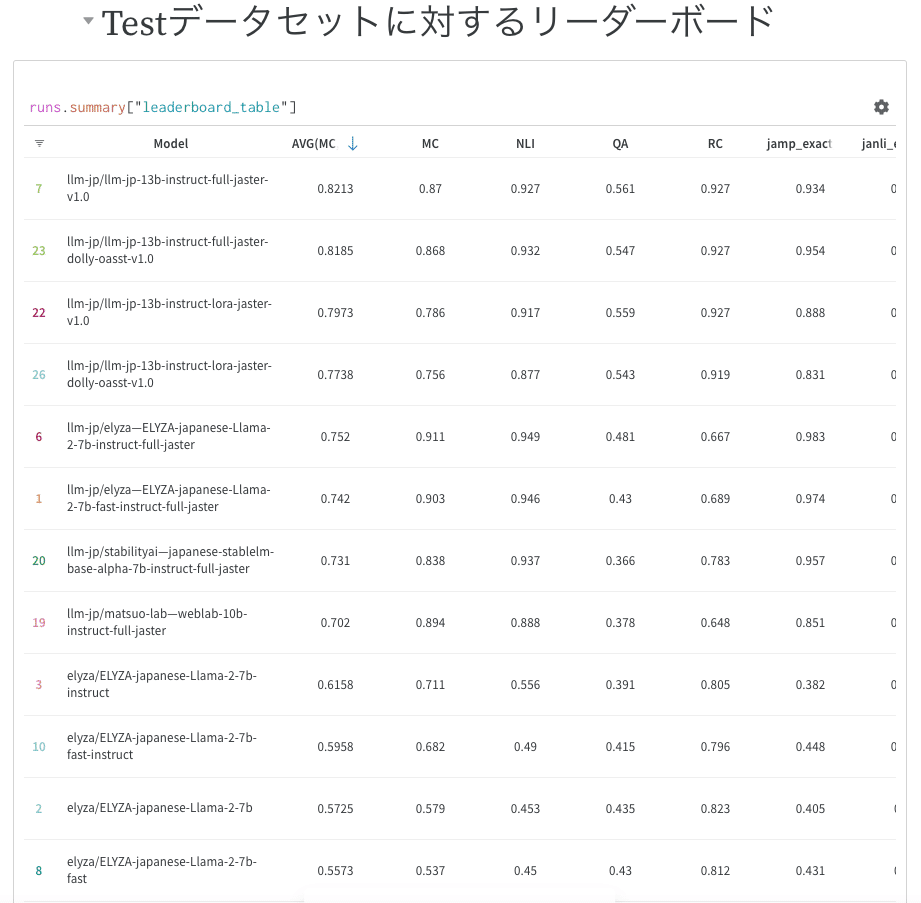
日本語LLMを自動評価する llm-jp-eval と、そのリーダーボード(llm-jp-eval リーダーボード)が公開。 上位はllm-jp-13Bモデルにファインチューニング(インストラクトチューニング)をしたモデル群。ファインチューニングしていないモデルでは、ELYZA-japanese-Llama-2-7b がAVGでトップか。
他の日本語LLMのリーダーボードとして、Nejumi LLM リーダーボード

このリーダーボードに対するX(Twitter)上でのやり取りがLLMの評価の参考になる。
久しぶりにNejumi LLM リーダーボード見に行ったら llm-jp のモデルが GPT-3.5を圧倒的に凌駕してGPT-4に迫ってた。え、マジこれ?w
これはまさにこの評価の難しいところですね。(中略) jstarとSuffixがついているものはJGLUEを含む日本語公開データを学習しています。勿論評価データは学習していないですが、つまりこれは純粋なzero-shotではなく教師あり学習後に相当すると思います。
なお、JGLUEなどを含まず、dollyなどのみでtuningしたものは別途真ん中くらいにあります。Unseen taskに対して形式含めての適応能力を評価しようとすると、Seenであることこの上ないJGLUEでは難しい部分もあるのかもしれませんね。
ライセンスは Apache License 2.0(商用利用可能)
"今後のアカデミアや産業界の研究開発に資するため、コーパス等を含めてすべてオープンにする" とのこと。
今回構築・公開した130億パラメータのLLM構築の知見に基づき、1750億パラメータのLLMの構築に10月より着手したとのこと。
Stability AI Japan、比較的小規模ながら高性能な2つのLLMモデル公開
「Japanese Stable LM 3B-4E1T」及び「Japanese Stable LM Gamma 7B」を公開。
以前(Stability AI Japan、70億(7B)パラメータの日本語LLM公開 )紹介した「Japanese Stable LM Alpha」シリーズ(日本語データでゼロから学習)と異なり、英語モデルとして制作・公開された大規模言語モデル「Stable LM 3B-4E1T」「Mistral-7B-v0.1」を元に日本語を主としたデータを用いて更に事前学習(継続事前学習, Continued Pretraining)を行うことで、日本語の能力を追加したモデル。
Japanese Stable LM 3B-4E1T
Stability AI が2023年10月に公開した、「Stable LM 3B-4E1T」英語LLM(3Bと比較的小規模だが、4Tトークンという非常に多い量のデータで学習が行われており、7B級のモデルに匹敵する性能)に日本語で継続事前学習をしたモデル。
Japanese Stable LM Gamma 7B
Mistral AI が2023年9月に公開した、「Mistral-7B-v0.1」英語LLM(7BのLLMだが、先進的なモデル機構を利用し、英語タスクでの性能評価において Llama-2 13B を全項目で上回り注目を集めた)に、日本語で継続事前学習をしたモデル。
性能 : 3Bモデルで、7Bモデル(ゼロから日本語で学習した Japanese Stable LM Base Alpha 7B)を上回る性能。


ストックマーク、ビジネスドメインや最新情報に対応した13B LLM公開
ビジネスのドメインや最新情報(2023年9月まで)に対応した13B LLMを公開。
独自に収集しているビジネスに関連するWebページや特許などのデータも用い事前学習をしたことで、既存のモデルと比べ、最新の情報やビジネスのドメインに対応したモデル。
以前(ストックマーク、14億(1.4B)パラメータの日本語LLM公開 )紹介したモデルのより大規模版?
【評価】
ビジネスに関連した知識
市場動向、時事問題、社会課題、ビジネストレンドなどの知識を問う問題 を作成し、評価(人手評価)

※ ChatGPT以外の全モデルは、日本語に翻訳されたAlpacaデータセットでInstruction tuningを行ったモデル。
※ ChatGPTは gpt-3.5-turbo-0613。gpt-4での評価なし。
日本語の言語理解

テキスト生成の効率性
同規模のモデルの中で、生成速度が速い。
要因の一つとしてトークナイザを上げ、トークナイザの語彙数、トークナイザの語彙が日本語のみか日英混合か、トークナイザ学習時にデータに対して事前分割を行うかどうかなどの要因により、本モデルが効率よくトークン生成できていることを述べている。

その他、会の中で紹介できなかった日本語LLM
(※ 以下のモデルが上記より重要でないなどの意味は一切ありません。シンプルに資料準備する余裕がなかった)
rinnaのLlama-2 7Bベース日本語LLM
Stability AI JapanのLlama-2 70Bベース日本語LLM
70Bで(ほぼ)自由に使えるモデルが公開されたのは大きい。
LLMのプロンプト技術まとめ
LLMの性能を引き出すための様々なプロンプト技術が提案され、まとめ記事も色々出てきている。
基本 : OpenAIから公開されている「Best practices for prompt engineering with OpenAI API」
OpenAI社が ”確実にうまく機能すると判断したプロンプトの形式”(”we present a number of prompt formats we find work reliably well”)を紹介。
1. 最新のモデルを使うこと。
2. 指示をプロンプトの先頭に置き、### または ””” を使用して指示とテキストを区切る。
効果が薄いプロンプト❌
以下の文章に対して、最も重要な点を箇条書きにまとめてください。
{入力テキスト}より良いプロンプト ✅
以下の文章に対して、最も重要な点を箇条書きにまとめてください。
文章: """
{入力テキスト}
"""3. 求める文脈、出力、長さ、形式、スタイルなどについて、具体的、説明的かつ可能な限り詳細に記述すること。
効果が薄いプロンプト ❌
OpenAIについての詩を書いてください。より良いプロンプト ✅
最近発表されたDALL-E(DALL-Eはテキストから画像へのMLモデル)を中心に、
OpenAIに関する感動的な短い詩を{有名な詩人}のスタイルで書いてください。4. 例を通して、希望する出力形式を明示する。
効果が薄いプロンプト ❌
以下のテキストに記載されているエンティティを抽出してください。
会社名、人名、特定のトピック、テーマの4種類のエンティティを抽出してください。
テキスト: {入力テキスト}より良いプロンプト ✅
以下のテキストに記載されているエンティティを抽出してください。
最初にすべての会社名を抽出し、次にすべての人名を抽出し、次に内容に合った特定のトピックを抽出し、
最後に一般的な包括的テーマを抽出してください。
望ましい形式:
会社名: (コンマで区切られた会社名リスト)
人名: -||-
特定のトピック: -||-
一般的なテーマ: -||-
テキスト: {入力テキスト}5. zero-shotから始めて、few-shotを行い、それでもうまくいかない場合はfine-tuning。
✅ zero-shot
以下のテキストからキーワードを抽出してください。
テキスト: {テキスト}
キーワード: ✅ Few-shot
以下のテキストからキーワードを抽出してください。
テキスト1: Stripeは、Web開発者がWebサイトやモバイルアプリケーションに決済処理を統合するために使用できるAPIを提供しています。
キーワード1: Stripe、決済処理、API、ウェブ開発者、Webサイト、モバイルアプリケーション
##
テキスト2: OpenAIは、テキストを理解し生成するのに非常に優れた最先端の言語モデルを訓練してきました。私たちのAPIはこれらのモデルへのアクセスを提供し、言語処理を含む事実上すべてのタスクを解決するために使用することができます。
キーワード2: OpenAI、言語モデル、言語処理、API
##
テキスト3: {テキスト}。
キーワード3:6. “ふわっとした”不明確な説明を減らす。
効果が薄いプロンプト ❌
この製品の説明文は、かなり短く、数センテンスのみで、それ以上は書かないこと。より良いプロンプト ✅
この製品について3~5文で説明してください。7. やってはいけないことを言う代わりに、やるべきことを言う。
効果が薄いプロンプト ❌
以下は、エージェントとお客様の会話です。ユーザー名やパスワードを尋ねないでください。繰り返さないでください。
お客様: アカウントにログインできません。
エージェント:より良いプロンプト ✅
以下は、エージェントとお客様との会話です。エージェントは問題の診断と解決策の提案を試みますが、PIIに関する質問は控えます。ユーザ名やパスワードなどのPIIを尋ねる代わりに、ヘルプ記事 www.samplewebsite.com/help/faq を参照してください。
お客様: アカウントにログインできません。
エージェント:8. コード生成専用: 特定のパターンに誘導するために「リーディングワード」を使用する。
効果が薄いプロンプト ❌
# Write a simple python function that
# 1. Ask me for a number in mile
# 2. It converts miles to kilometersより良いプロンプト ✅
# Write a simple python function that
# 1. Ask me for a number in mile
# 2. It converts miles to kilometers
import応用 : 様々なプロンプト技術
以下を参考に社内で紹介しました。(ほとんど以下記事と同内容(コピペになってしまう)なのでここではリンクだけ)
お知らせ
前回から1ヶ月ほど空いてしまいました。
これまで基本的に毎週実施してきていましたが、いろいろ状況が変わってきており、今後は不定期の実施(現状月一の予定)になります。
そのため、このマガジンも不定期の更新となります。よろしくお願いします!
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。
この記事が気に入ったらサポートをしてみませんか?