
GPTを利用してJSONデータの一部分から全体の構成を推定し、データ項目定義を出力する

noteって非公開ながらもAPIがあるんですよね。
ちょっとnote記事を取得し続けたい用事があって、APIを活用したいなーと思ったところ・・・
シンプルにnote記事のタイトルとURLを取得したいだけなのですが、APIにアクセスしてみるとめちゃめちゃ項目が存在しています。
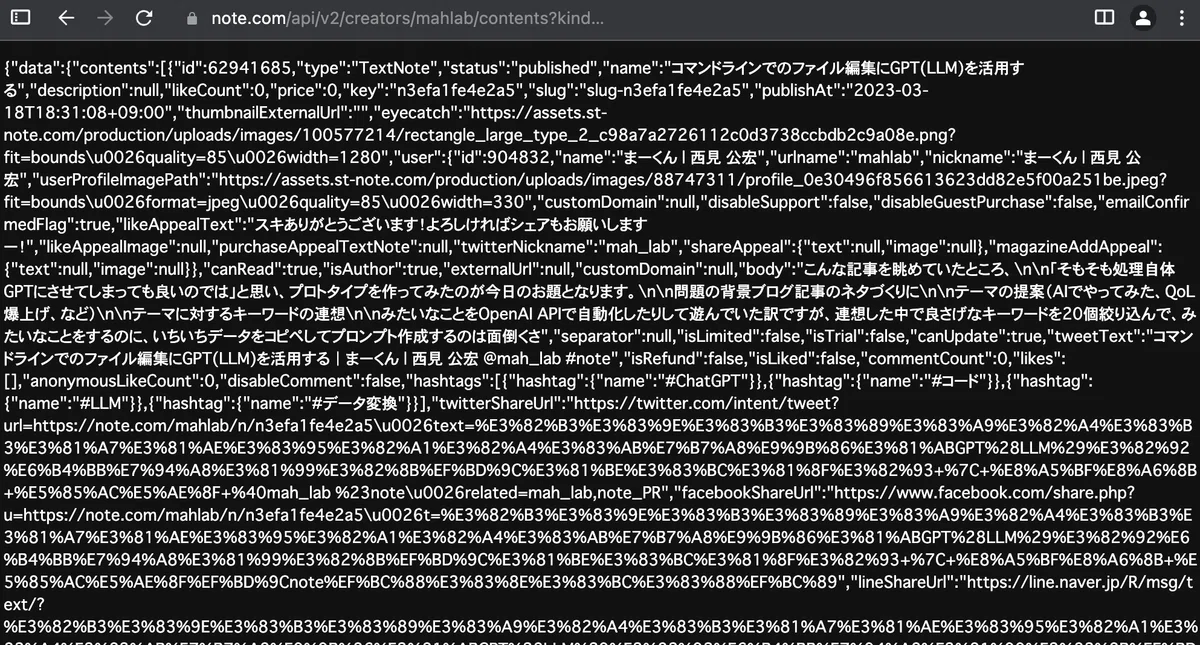
ChatGPTにでもつっこんでざっくりとした構造を把握したいところですが、まるまる投入しようとするとデータ量が多すぎてリクエストエラーになってしまいます。
1記事分だけ投入して構造分析してもらおうにも、イマイチどこが記事毎のデータの切れ目なのかも目検では判断しづらいのです。
さて、どうしたものか。
適当に切り取って渡してみる
GPTさんにはめちゃめちゃな非構造化データを渡してもそれなりに上手くパースしてくれた実績があるので、あんまりデータの切れ目を気にしなくても良い感じに判断してくれるのかも知れない。
というわけで中途半端に切り取ったデータを以下のプロンプトで渡してみました。
以下のデータはあるJSONデータの一部分である。
この部分データからJSONデータの仕様を推測し、以下のタスクを実行しなさい。
# タスク
1. JSON内のデータ項目の定義を整理したい。それぞれの項目について、それぞれ型と内容を整理し、表として出力せよ。
2. このJSONを読み込んで処理を行うPythonコードを記述したい。完全なJSONデータが与えられる場合、このJSONデータを読み込んだ場合のサンプルコードを提示せよ。
# データ
(適当に切り取ったデータ)結果:ちゃんと構造分析してくれる
もはやこのぐらいの仕事ができるのは当たり前だと言わんばかりに、ちゃんと構造分析してくれました。


コードもしっかり出力してくれました。
import json
# JSONデータを読み込む
with open('data.json', 'r') as f:
data = json.load(f)
# ノートのリストを取得する
notes = data['data']['contents']
# 各ノートの情報を表示する
for note in notes:
print('ID:', note['id'])
print('タイトル:', note['name'])
print('投稿日時:', note['publishAt'])
print('ユーザー名:', note['user']['name'])
print('いいね!数:', note['likeCount'])
print('本文:', note['body'])
print('ハッシュタグ:')
for hashtag in note['hashtags']:
print('-', hashtag['hashtag']['name'])
print('-----------------------------------------')note APIは非公開ということもあって構造は不定だという注意書きがあったのですが、定期的にJSONデータを1KBぐらい切り取ってGPTに投げて構造を分析してもらって、タイトルとURLっぽいキーのアクセス方法を生成する、みたいなことをすれば、データ構造が変化したとしてもノーメンテナンスで動き続けるプログラムを書けるんじゃないかなーと思いました。
連携システムのAPIの仕様が予告無しに変更されて芋づる式にサービスがダウンする、みたいな憂き目にあったこともありますが、ちょっとした変更であれば仕様を推測する仕組みを入れることで吸収できるような時代にいるのかも知れません。本当にシステム設計のパラダイムが変わっていきますね。
現場からは以上です。
この記事が気に入ったらサポートをしてみませんか?