
大規模言語モデル間の性能比較まとめ

StableLMのファインチューニングってできるのかな?と調べたところ、GitHubのIssueで「モデル自体の性能がまだ良くないから、ファインチューニングの段階ではないよ」というコメントがありまして。
その根拠として提示されていた大規模言語モデル間の性能比較シートがとても参考になったので共有したいと思います。
シートの中身を見てみる
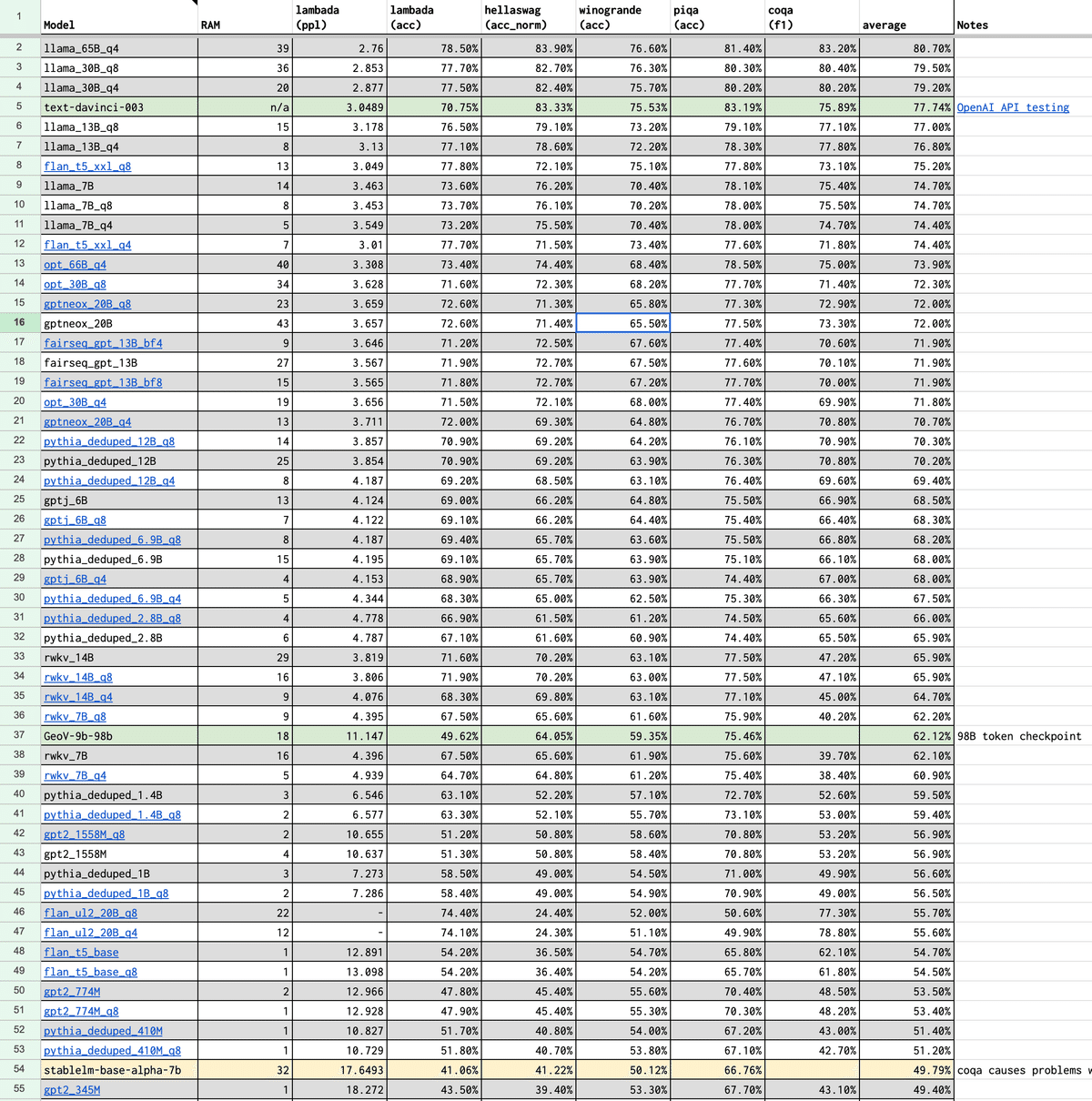
stablelm-base-alpha-7bは54行目にありまして、確かに他の言語モデルと比較するとまだまだな性能のようです。応援したいですね。
シートの列の意味
それぞれの列の意味については推定ですが以下の通りです。
RAM
言語モデルのGPUメモリ消費量。
lambada(ppl)
LAMBADAデータセットによる測定値。ロングレンジの言語理解能力をテストする(文章全体を読まないと答えられないタスクでの評価)。PPLはPerplexityという指標で、モデルの予測の不確かさを示す。PPLが低いほど、モデルの予測精度が高い。
lambada(acc)
LAMBADAデータセットによる測定値。ACCはAccuracyという指標で、正確性(精度)を意味する。ACCが高いほど、モデルの性能が良い。
hellaswag(acc_norm)
HellaSwagデータセットによる測定値。一般的な知識や常識を利用して物語の続きを予測するタスクでの評価。ACC_NORMは正規化された正確性(精度)を意味しており、この値が高いほどモデルの性能が良い。
winogrande(acc)
WinoGrandeデータセットによる測定値。通知識や文脈推論を用いて、文章の空欄を埋めるタスクで評価される。ACCは正確性(精度)。
piqa(acc)
PIQAデータセットによる測定値。言語モデルが物理的な世界についてどの程度学習しているかを調査する質問が含まれている。ACCは正確性(精度)。
coqa(f1)
CoQAデータセットによる測定値。会話型質問応答システムが架空の物語を理解し、推論する能力を評価する。F1スコアは適合率(Precision)と再現率(Recall)の調和平均であり、高いほどモデルの性能が良い。
average
lambda(acc)〜coqa(f1)までの平均値。
RAMが1桁台であればご家庭のゲーミングPCでも動くというわけですが、それを踏まえるとllama_13B_q4あたりは別格の性能ですね。
現場からは以上です。
この記事が気に入ったらサポートをしてみませんか?