
AI 実装検定への道(12)

AI 実装検定 A級合格へ向けて学習を進めています。
前回投稿が11回目で、引き続きGoogle Colaboratoryを利用してプログラミングの章を進めて書いています。
前回は、その前の回から1か月長怠けてしまっていたので、改めてGoogle Colaboratoryの環境に触れ、「Series」「DataFrame」について「concact」関数を使った連結をしたり、「append」関数についても勉強しました。久々の勉強だったので、少ししか進みませんでしたが、今回は、公式テキスト256ページの下段から再開します。「merge」を使って横方向の連結を学んでいきます。
「merge」を使った横方向の連結
まずは、最初にDF1とDF2を作成します。
公式テキスト通りに、従業員の名前と所属を表す情報を「DF1」、入社年を表す情報を「DF2」として整備します。
(コード記述)
DF1=pd.DataFrame({"employee":["James","John","Maria","Robert"],"group":["HR","Accounting","Engineering","Engineering"]})
DF1
(結果)

(コード記述)
DF2=pd.DataFrame({"employee":["Maria","James","John","Robert"],"hire_date":["2010","2014","2018","2020"]})
DF2
(結果)

上記の「DF1」と「DF2」を、「merge」を使って横に連結します。
(コード記述)
DF3=pd.merge(DF1,DF2)
DF3
(結果)
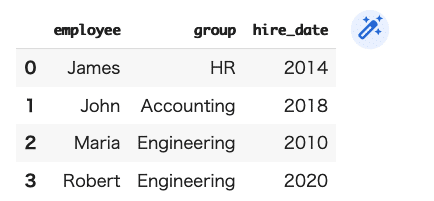
「merge」を利用すると、ここでは名前を軸に揃えることが出来ました。
そんなに便利なものということなのでしょうか?
次に各所属の上司情報を「DF4」に整理します。
(コード記述)
DF4=pd.DataFrame({"group":["HR","Accounting","Engineering"],"supervisor":["Susan","Mary","david"]})
DF4
(結果)
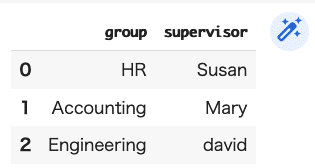
このDF4を、先のDF3に「merge」します。
(コード記述)
DF5=pd.merge(DF3,DF4)
DF5
(結果)

次に、所属部門におけるスキルを「DF6」に整理します。
(コード記述)
DF6=pd.DataFrame({"group":["HR","HR","Accounting","Accounting","Engineering","Engineering"],"skills":["spreadsheet","organization","Math","spreadsheet","coding","linux"]})
DF6
(結果)
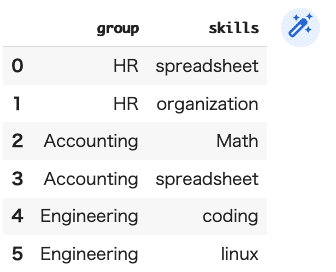
この情報「DF6」をその前の「DF5」に「merge」してみます。
(コード記述)
DF7=pd.merge(DF5,DF6)
DF7
(結果)

「merge」は、項目を指定して、それを軸に「merge」するということもできるそうです。
今一度「DF1」と「DF2」についてみてみましょう。
(コード記述)
DF3=pd.merge(DF1,DF2)
DF3
(結果)
次は、DF8として「employee」を軸として「merge」してみましょう。
(コード記述)
DF8=pd.merge(DF1,DF2, on="employee")
DF8
(結果)
同じ結果になりました。
では、
DF9として「group」を軸として「merge」してみると・・・
(コード記述)
DF9=pd.merge(DF1,DF2, on="group")
DF9
(結果)

ちょっと、良く分からないエラーになってしまいました。
DF5とDF6について、「group」を軸に「merge」してみます。
(コード記述)
DF10=pd.merge(DF5,DF6, on="group")
DF10
(結果)
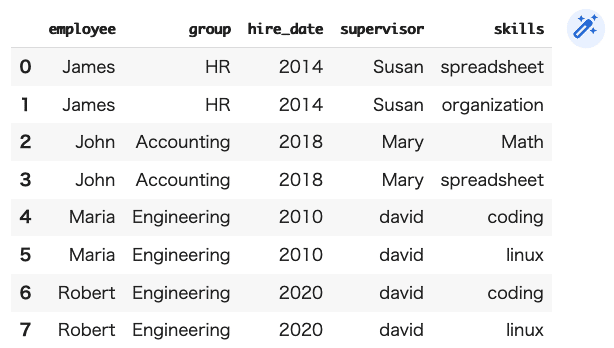
う〜ん、これも前の結果と同じになってしまう・・・
ちょっと、分からないので、次に進みますね。
新しいDataFrameとして「DF11」と「DF12」を用意します。
(これ、英語の入力が面倒なんだけど・・・)
(コード記述)
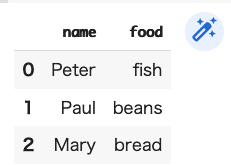
DF11=pd.DataFrame({"name":["Peter","Paul","Mary"],
"food":["fish","beans","bread"]},
columns=["name","food"])
DF11
(結果)
(コード記述)
DF12=pd.DataFrame({"name":["Mary","Josegph"],
"drink":["wine","beer"]},
columns=["name","drink"])
DF12
(結果)

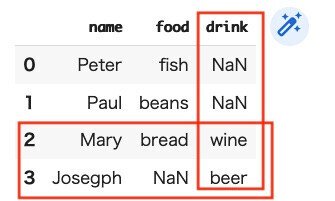
ここで、「DF11」と「DF12」について「merge」します。
(コード記述)
pd.merge(DF11,DF12)
(結果)

公式テキスト261ページの説明でようやく掴めてきました。
普通に「merge」すると『inner』という方法で、共通部分が整理されるわけで、それ以外に『outer』『left』『right』の連結方法があるそうです。この因数の指定は「how=」を利用します。
(コード記述)
pd.merge(DF11,DF12,how="outer")
(結果)

ここで、理解しておかねばならないのは、『outer』で指定した場合、値がない場所には「NaN」(非数)が表示されるということです。一応、試しに『left』と『right』についてもやってみます。
(コード記述)
pd.merge(DF11,DF12,how="left")
(結果)

(コード記述)
pd.merge(DF11,DF12,how="right")
(結果)

『left』とした場合、foodで共通点を見出して抽出されました。一方、『right』とした場合にはdrinkでの共通点という解説になるのだろうか?左方向、右方向という説明が現段階ではできないけど、出てきた情報だけ残しておきます。
その説明が、公式テキスト262ページの最初にありました。

こんな感じに理解したらいいのかな?『outer』で全抽出されたデータに対して、左側の列(ここでは、food)について抽出されたので、そこに情報のない「Josegph」は省略されてしまった。そして右側の列(ここでは、drink)に抽出されたのが下のような場合。こうして、『left』と『right』の違いが理解できたとしておきます。
次に、DataFrameの「集約」と「グループ化」について勉強します。
まずは、ランダムな値が5つ入った『Series』を用意します。
(コード記述)
ser=pd.Series(np.random.rand(5))
ser
(結果)

『Series』の各値の合計を、「sum関数」を使って求めます。
(コード記述)ser.sum()
(結果)3.585907191453766
『Series』の各値の平均を求める場合は、「mean関数」を使います。
(コード記述)ser.mean()
(結果)0.7171814382907532
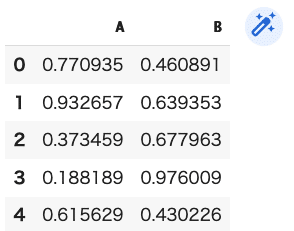
『DataFrame』についても、同じように平均値を表示することができます。
(コード記述)
DF15=pd.DataFrame({"A":np.random.rand(5),"B":np.random.rand(5)})
DF15
(結果)
DF15.mean( )として、A列の平均とB列の平均を表します。
(コード記述)DF15.mean()
(結果)

「axis」で「columns」を指定すると、各行の平均値を示します。
(コード記述)DF15.mean(axis="columns")
(結果)

ちょっとややこしくなってきそうですが、第21講はあと3ページなので、続けます。
このほかに、『pandas』には「平均値(mean)」や「標準偏差(std)」などデータの前処理を行う際に用いる値をまとめて表示する「describe関数」が用意されているそうです。「iris」のサンプルデータを用いて
「describe関数」の動作を確認していきます。
まずは、「iris」のサンプルデータセットを読み込んで『pandas』形式に置き換え、それに対して「describe関数」を用いて統計的な情報整理をしていきます。
(コード記述)
import pandas as pd
from sklearn import datasets
iris=datasets.load_iris()
DF20=pd.DataFrame(iris.data, columns=iris.feature_names)
DF20.describe()
(結果)

次にグループ化を見ていきます。
グループ化は同じものを合体させる処理です。
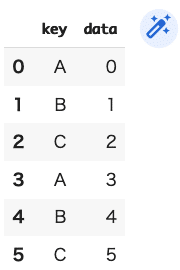
(コード記述)
DF21=pd.DataFrame({"key":["A","B","C","A","B","C"],
"data":range(6)},
columns=["key","data"])
DF21
(結果)
このDataFrameにおいて、key列のA、B、Cについて、まとめます。
(コード記述)
DF21.groupby("key")
(結果)<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7f677d0c88b0>
これで出来ているのかどうか不安ですが・・・
(コード記述)
DF21.groupby("key").sum()
(結果)

確かに、先に表示されたものが合計されています。
(あれ?「iris」のサンプルデータは使わないのか??)
ほかに、列ごとに最小値、中央値、最大値を求める「aggregate」関数があります。(「aggregate」とは集計という意味)
今一度、DataFrameを用意していきましょう。
(コード記述)
DF22=pd.DataFrame({"key":["A","B","C","A","B","C"],
"data1":range(6),
"data2":np.random.randint(0,10,6)},
columns=["key","data1","data2"])
DF22
(結果)

A、B、Cをグループ化します。
(コード記述)DF22.groupby("key")
(結果)<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7f677d0c8280>
今回も出来ているか不安ですが・・・次に「aggregate」関数を使ってみます。
(コード記述)
DF22.groupby("key").aggregate(["min",np.median,max])
(結果)

ちょっと一抹の不安が残る。
折角、「iris」のサンプルデータを読み込んだのに統計処理に利用しなかったのか?それとも、あれで一気にサンプルデータを「describe関数」を使って処理したということだったのかな・・・
兎に角、今回は公式テキスト256ページの下段から再開し、「merge」によるデータのまとめ方、「merge」に対して因数指定「how=」を利用して、『inner』『outer』『left』『right』の連結方法を勉強し、DataFrameの「集約」と「グループ化」に進み。『Series』の各値を合計する「sum関数」(Excelではお馴染みですね)と平均を求める「mean関数」を経験したのちに、『DataFrame』についても確認。最後には、『pandas』における「平均値(mean)」や「標準偏差(std)」などデータの前処理を行う際に用いる値をまとめて表示する「describe関数」について「iris」のサンプルデータを用いて動作確認し、列ごとに最小値、中央値、最大値を求める「aggregate」関数にまで進みました。
次回は、第22講。公式テキスト267ページから『Matplotlibでグラフの可視化』へ進んでいきます。
この記事が気に入ったらサポートをしてみませんか?