AI 実装検定への道(ちょっと道草)

現在、AI 実装検定 A級合格へ向けて学習を進めていおり、学習環境にはGoogleの『Colaboratory』を利用してプログラミングをしています。
今回は、公式テキストから離れて、ちょうど良い勉強課題がニュースで届いたので、やってみようと思います。
数学×Pythonプログラミング入門
Pythonで統計・データ分析!~基本統計量の活用と機械学習の基本
こちらは、アイティメディア株式会社が運営する「ITmedia」サイトのうち『@IT』サイトに掲載された情報です。Google Colabで提供されているカリフォルニアの住宅価格データ('sample_data/california_housing_train.csv')をpandasデータフレームに読み込み、行や列を取り出してみることを最初の目標にする、と紹介されているので、AI 実装検定 A級合格へ向けて学習を進めている途中としては勉強になりそうです。
毎度、忘れないで実施しておきたいのは、Numpyを呼び出すこと。今回は、pandasも使うので、下記記述を行います。その上で、上記サイトに紹介された「カリフォルニアの住宅価格データ」を読み込みます。
(コード記述)
import numpy as np
import pandas as pd
df = pd.read_csv('./sample_data/california_housing_train.csv')
df.head()
(結果)
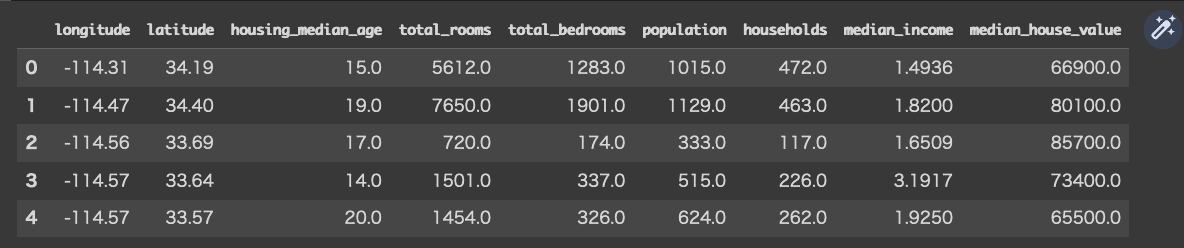
右肩の鉛筆マークをクリックしてみると・・・

英語で意味がわかりませんが、サイトの解説によると・・・longitude(緯度)、latitude(経度)、housing_median_age(築年数の中央値)、total_rooms(部屋数の合計)、total_bedrooms(寝室数の合計)、population(人口)、households(世帯数)、median_income(世帯収入の中央値)、median_house_value(住宅価格の中央値)とのこと。
嫌に部屋数の多いデータだと思っていたら、個々の物件の値ではなく、1区画(ブロック)の合計や中央値となっていると解説されています。
(コード記述)
print(df.index)
(結果)
RangeIndex(start=0, stop=17000, step=1)
このように、Indexを呼び出してみると、0〜17,000までのデータフレームとなっていて、1つずつ配番されていることが分かりました。
(コード記述)
print(df.columns)
(結果)
Index(['longitude', 'latitude', 'housing_median_age', 'total_rooms',
'total_bedrooms', 'population', 'households', 'median_income',
'median_house_value'],
dtype='object')
次に、各項目の列の見出しを columnsを利用して呼び出してみました。先に日本語訳を記述した通り、各項目が呼び出されました。
コラム さまざまな形式のCSVファイルを読み込む
次に、コラムで紹介された「github」にアップされた、これは架空の組織の売り上げデータでしょうか?これを読み込みます。
(コード記述)
dfsales = pd.read_csv('https://raw.githubusercontent.com/Gessys/math/main/data/sales.csv')
dfsales.head()
(結果)
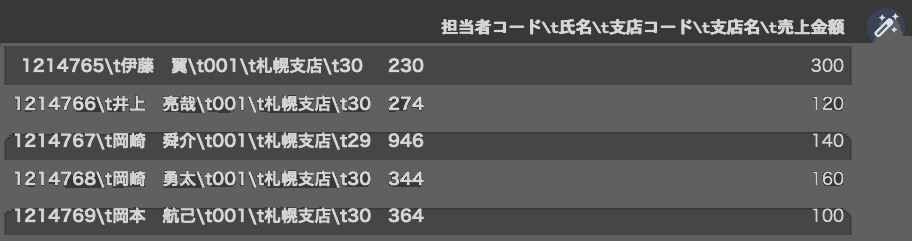
なんか違和感ある表示です。
サイトの解説によると、元のデータが「タブ文字(\t)で区切られたCSVファイル」であり、そのまま読み込んだ場合にはこうなってしまうそうです。あらかじめそれを理解できていれば、「タブ区切り」を指定して読み込むのだそうです。
(コード記述)
import pandas as pddfsales = pd.read_csv('https://raw.githubusercontent.com/Gessys/math/main/data/sales.csv', sep='\t', index_col='担当者コード')
dfsales.head()
(結果)
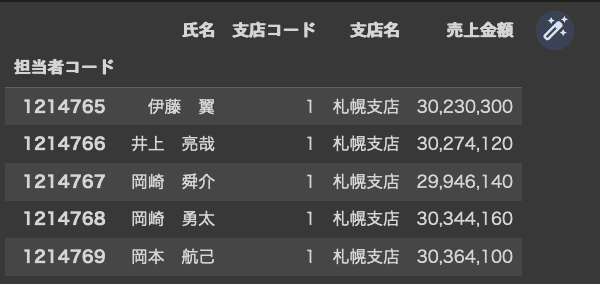
ここでのミソは、「sep='\t'」とタブ区切りである旨を指定した部分ですね。ここでも、indexとcolumunsを呼び出してみます。
(コード記述)
print(dfsales.index)
(結果)
Int64Index([1214765, 1214766, 1214767, 1214768, 1214769], dtype='int64', name='担当者コード')
このindexには、「name='担当者コード'」とタイトルがついています。
そして、1214765, 1214766, 1214767, 1214768, 1214769というように5名の方のコードが配置されていると理解できました。
(コード記述)
print(dfsales.columns)
(結果)
Index(['氏名', '支店コード', '支店名', '売上金額'], dtype='object')
この通り、各列のタイトルとして「氏名」「支店コード」「支店名」「売上金額」と読み込むことが出来ました。
コラム Excelのファイルを読み込む
次は、Excelファイルを読み込むのだそうです。同じように、あらかじめgithubに用意されたファイルを読み込みます。
(コード記述)
dffitts = pd.read_excel('https://github.com/Gessys/math/blob/main/data/fitts.xlsx?raw=true', sheet_name='実験データ', skiprows=2, usecols=[0, 1])
dffitts.head()
(結果)
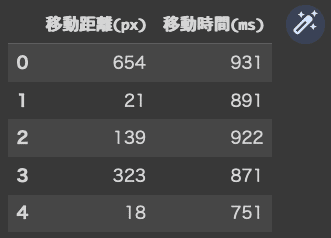
コードには、「fitts.xlsx」というデータを読み込むように指示されています。skiprows=2, usecols=[0, 1]の記述はなんでしょうか?
ひとまず、indexとcolumunsを呼び出してみます。
(コード記述)
print(dffitts.index)
(結果)
RangeIndex(start=0, stop=50, step=1)
このデータは、0〜50まであることが分かります。
(コード記述)
print(dffitts.columns)
(結果)
Index(['移動距離(px)', '移動時間(ms)'], dtype='object')
解説によると「skiprows」で除外する列を、「usecols」で利用する列を指定できるとのこと。元のデータは下記のように3列目(C列)以降にもデータがあるので、「skiprows=2」で最初から0、1の列以降を除外する指定、そして「usecols=[0, 1]」で、0〜1番目の列見出しを利用すると指定しているようです。
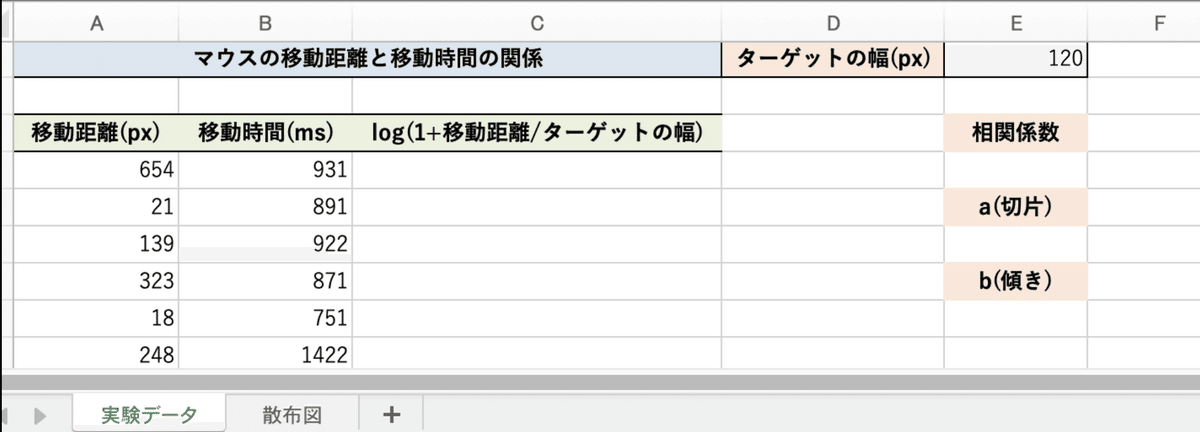
データフレームから単一の列を取り出す
コラムを経て、今一度で最初に読み込んだ住宅価格データ(データフレーム名「df」)から人口(population)の列を取り出してみます。
(コード記述)
df = pd.read_csv('./sample_data/california_housing_train.csv')
print(df['population'])
print(df['population'].mean())
(結果)
0 1015.0
1 1129.0
2 333.0
3 515.0
4 624.0
...
16995 907.0
16996 1194.0
16997 1244.0
16998 1298.0
16999 806.0
Name: population, Length: 17000, dtype: float64
1429.5739411764705
この通り、最初に読み込まれた5行目までのデータに加えて、中飛ばしをして最終17,000行目(0を含むので16,999と表示)までのpopulation(人口)データが読み込まれました。
このようにdf['population']とすると、取り出されたデータはSeriesとなりますが、さらに[ ]で囲って、df[['population']]とすると、取り出されたデータはデータフレームになるとのこと。
一度やってみましょう。
(コード記述)
df = pd.read_csv('./sample_data/california_housing_train.csv')
print(df[['population']])
print(df[['population']].mean())
(結果)
population
0 1015.0
1 1129.0
2 333.0
3 515.0
4 624.0
... ...
16995 907.0
16996 1194.0
16997 1244.0
16998 1298.0
16999 806.0
[17000 rows x 1 columns]
population 1429.573941
dtype: float64
形式はあまり変わったように見えませんが、良く見ると「population」とタイトルがついていて、下端には[17000 rows x 1 columns]と17,000のデータが1つのカラムに収まっているとあるので、データフレームとして表されたと理解していいのでしょう。
次に、このデータフレーム形式で、population(人口)とmedian_house_value(住宅価格)を取り出してみます。
(コード記述)
df = pd.read_csv('./sample_data/california_housing_train.csv')
print(df[['population', 'median_house_value']])
print(df[['population', 'median_house_value']].mean())
(結果)
population median_house_value
0 1015.0 66900.0
1 1129.0 80100.0
2 333.0 85700.0
3 515.0 73400.0
4 624.0 65500.0
... ... ...
16995 907.0 111400.0
16996 1194.0 79000.0
16997 1244.0 103600.0
16998 1298.0 85800.0
16999 806.0 94600.0
[17000 rows x 2 columns]
population 1429.573941
median_house_value 207300.912353
dtype: float64
予め「population」だけをデータフレーム形式に呼び出してみたので、同様に示されたことが分かりました。先に解説された通りdf['population']では、取り出されたデータはSeriesですが、df[['population']]とすると、取り出されたデータはデータフレームとなる。前者は、単一の列見出しのリストを得るときに有効と考え、複数列を取り出したいときにはデータフレーム形式が適当と考えるのがいいのかな?
ここで見せていただいた方法では、これまで勉強してきたようなリストのスライスのように0〜15までをしてしたい「0:14」のような範囲指定はできまない。そのため、population(人口)からmedian_house_value(住宅価格)までを取り出すために、df[['population', 'median_house_value']]のように個々にカンマで区切って記述することとなったようです。
df[['population': 'median_house_value']]としたらエラーにってしまうみたい。
一応エラーも見ておきますか!
(コード記述)
df = pd.read_csv('./sample_data/california_housing_train.csv')
print(df[['population':'median_house_value']])
print(df[['population':'median_house_value']].mean())
(結果)
File "<ipython-input-15-76226ebaf62f>", line 2 print(df[['population':'median_house_value']])
^
SyntaxError: invalid syntax
こんなエラーが出てきました〜
データフレームから行と列を取り出す
特定の行や列を自由に指定して取り出すには、「iloc」メソッドや「loc」メソッドが使えるとのこと。「iloc」メソッドは取り出す行や列の位置を整数で指定。一方、「loc」メソッドは取り出す行や列のインデックス(見出し)を指定。どちらでも、スライスの指定ができますが、「iloc」メソッドの場合は末尾が含まれず、locメソッドの場合は末尾が含まれることに注意が必要なんですって?(知らんけど・・・笑)
整数で位置を指定して行と列を取り出す
→データフレーム名.iloc[行位置, 列位置]
インデックスを指定して行と列を取り出す
→データフレーム名.loc['行見出し', '列見出し']
やってみましょう〜!
(コード記述)
df.iloc[2:5, 6:]
(結果)

今一度、最初の「df」を並べてみます。
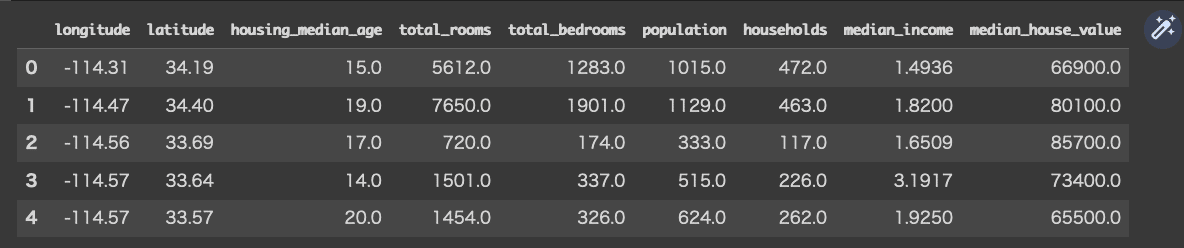
これを見比べるとわかる気がしますが「整数で位置を指定して行と列を取り出す」記述として『データフレーム名.iloc[行位置, 列位置] 』と解説されました。そして、記述としては「df.iloc[2:5, 6:]」。
まず行位置を「2:5」と書いたのは0から始まる行の2つ目の次・・・解りにくくなるのがここなんだけど、0、1、2・・・と続くので、2番目の次、すなわち3番目が「2」、そして5番目「4」まで読むということかな?さらに列の指定では「6:」とだけ書いていますので、6番目の次、すなわち「7」番目から以降最後までを読み込めということか?
では、試しに「df.iloc[1:8, 4:8]」と入れてみます。
(コード記述)
df.iloc[1:8, 4:8]
(結果)
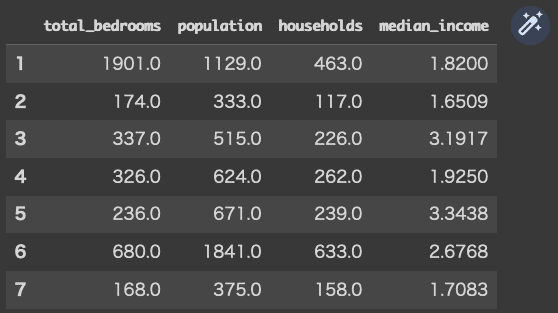
上記の理解で間違いなかったようです。(ホッ)
次は、インデックスを指定して行と列を取り出す「loc」の利用です。
(コード記述)
df.loc[2:4, 'households':]
(結果)

この記述はなんでしょう?
先ほどの「iloc」では、行を何番目と整数で指定しました。
しかし、「loc」では、行の番号を指定して行のindexが2が配番されたところから4までと指定していますので、このようにindex番号2、3、4の3行が表されました。列についても「households」と指定して、そこから最終列までを抜き出しています。
では、今一度「df.loc[5:10, 'total_rooms':'households']」として読み込んでみます。先ほどの理解がそれで良いのかの検証です。
(コード記述)
df.loc[5:10, 'total_rooms':'households']
(結果)
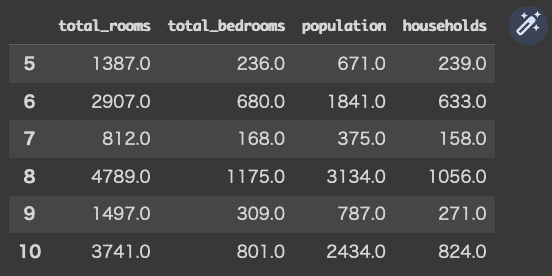
意図した通りに、index番号5〜10までの行について、列見出しが「total_rooms」〜「households」までをデータフレームとして表せました。
これ、ちょっと寄り道のつもりでしたが、サイトの1ページ目の途中でここまでにしておきます。サイトには、5ページまでびっしり解説があるようなので、また機会あればやってみます。
(公式サイトに戻らなきゃ〜)
今回は、アイティメディア株式会社が運営する「ITmedia」サイトのうち『@IT』サイトに掲載された情報をもとに、csvデータやExcelデータを読み込んでデータフレームを示し、そこから行、列を取り出す「iloc」と「loc」を知りました。
『@IT』サイトさん、有難うございました!!
この記事が気に入ったらサポートをしてみませんか?