XHack勉強会 第3回『Ruby「ゼロから」画像共有サービスを作る』で学んだこと【データベース操作編】

Herokuアップロード編
こちら
データベース(postgreSQL)の操作について、
僕が分かるように書いているので
コマンドの書き方が本来の表記とは異なることがあります。
もし参考にするなら、そこだけ注意して見てください。
このノートでざっくり分かること。
【データベースのイメージ】
・前回もデータベースについて軽く触れたが、
今回は操作やもう少し内部についてまとめる。
まずデータベース用語を、エクセル表を例えに使ってイメージする。

エクセルで言うと下記のようになる。
・タイトル = データベース名
・シート名 = テーブル名
・列 = カラム
・行 = レコード(ロウ)
・セル = フィールド
これをイメージすると覚えやすいと思うので、
頭で描くように操作していこう。
【データベースのインストールから起動まで】
まずpostgreSQLのインストール及び確認を下記コマンドにて実行。
Homebrewを使ってインストール
$ brew install postgresql
データベースの初期化
$ initdb /usr/local/var/postgres -E utf8
インストール確認
$ postgres --version
・ "initdb"コマンドのオプション"-E utf8"について
"-E utf8"はセットオプションで、要は文字コードをUTF-8に指定している。
UTF-8は大雑把に言うと「パソコンの世界共通語」に近いもので、
世界中の多くのソフトウェアはUTF-8に対応している。
ガラケーはShift-JIS(日本語表示させるために開発されたコード)
しか読めなかった。
ここのデータベースの初期化だが、新規データベースクラスタ
(データ本体・設定ファイルなど、全データを保存する領域)を
作成することを意味している。
次は起動コマンドを実行。
$ postgres -D /usr/local/var/postgres・"-D"オプションについて
これは簡単に言うと、データベース設定ファイルの場所を指定している。
"-D"後の位置にデータベース初期化にて設定ファイルを作成したので、
そこを指定。
・環境変数PGDATAについて
この位置の指定だがbashなら「.bash-profile」、zshなら「.zprofile」に
"export PGDATA=/usr/local/var/postgres "と記載すれば、次回以降は
無しで起動や初期化が出来る。
起動が出来たらOK。
ただデータベースはアプリケーションなので、操作を行うには
立ち上げ続ける必要がある。
なのでここからはターミナルの新規タブを開き、
再度プロジェクトディレクトリへ移動。
ちなみにデータベースアプリを停止するときは、
起動しているタブを開き”control + c”で停止できる。
■データベース追加・削除
次のコマンドで現在作成されているデータベースの一覧を表示。
$ psql -l初期化時に作成された「postgres」、「template0」、「template1」が
表示されている。
ではまずデータベースの作成・削除のコマンド。
データベースの作成
$ createdb [データベース名]
データベースの削除
$ dropdb [データベース名]※どうでもいい余談
なんでdeleteじゃなくてdropやねん!ってずっと思ってたので、
調べてみると・・・
deleteはテーブルやフィールドのデータ「消去」にあたるらしく、
dropはデータベースやテーブルそのものの「削除」。
という使い分けとのこと。
そして下記コマンドで作成したデータベースに接続。
$ psql [データベース名]そしてそのデータベースの中身を作成していくのですが、
まず下記のように完成形をイメージ。
(仮にpricedataデータベースを作っていく)
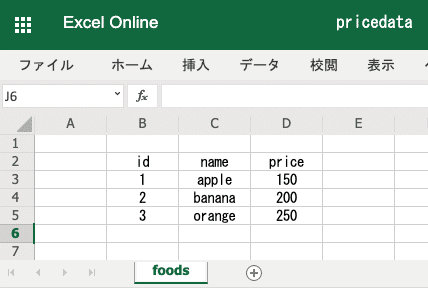
【SQLコマンドの基本操作】
ここからはデータベースコマンドを使って操作していくことになるので、
ターミナルとはコマンドが違うので注意。
以下、基本コマンド。(全て"\"バックスラッシュなので、これも注意)
データベース一覧取得
\l
テーブル一覧取得
\d
対象テーブルの フィールド一覧取得
\d [テーブル名]
データベース切断
\q【テーブルの作成】
テーブル名を決める・・・ではなく下記イメージのような枠を作る感じ。

CREATE TABLE [テーブル名]
([カラム名1] [データ型] [制約],
[カラム名2] [データ型] [制約],
〜
PRIMARY KEY (id));1行目はCREATE TABLE [テーブル名]
2行目以降は、[カラム名 データ型 制約]をスペース区切りで
入力していく。
最後の行に主キーの指定。
(インデックスと呼ばれる情報が自動的に作成されて、検索が早くなる)
・サンプル
CREATE TABLE foods
(id char(2) NOT NULL,
name TEXT NOT NULL,
price int ,
PRIMARY KEY (id));
※「NOT NULL」とはデータを挿入時に空白にしたらエラーが出る。
(入力必須項目)
【データ挿入】
作成したテーブルはまだ空なので、中にデータを入力。
INSERT INTO [テーブル名] ([カラム名1][,カラム名2]...) VALUES ([値1][,値2]...);
もしくは、全てのカラムに値を入れるなら、カラム名は省略可能
INSERT INTO [テーブル名] VALUES ([値1][,値2]...);作成したテーブル名入れて、カラム名に合わせて値をセットしていく感じ。
・サンプル
INSERT INTO foods (id, name, price) VALUES (1, 'apple', 150);
ちなみにこういう改行して書いてもOK
INSERT INTO foods (id, name, price)
VALUES (1, 'apple', 150);
【データ検索】
これがデータベースを使うことの最大の理由と言っても過言ではない。
データベースから必要な情報を加工し、取り出し、利用する。
色んな検索の方法があるので、とりあえず基本的なところをまとめてみた。
■基本型
完成したデータベースから必要な情報を取り出してみる。
SELECT [表示したいカラム名] FROM [テーブル名];これで特定のカラムのデータのみ表示させれる。
カラム名の代わりに「*」を入れれば全てのデータを表示できる。
■WHEREにて絞り込み
あとこれは指定したカラム名のデータのみを表示するので、
もう少し絞り込んだりするには、下記コマンドを使用する。
SELECT [表示したいカラム名] FROM [テーブル名] WHERE [条件式];例えば下記イメージの「price」が「200」以上の全てカラムを
表示させたい時は
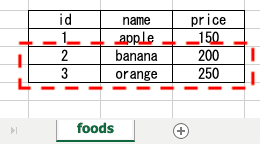
# SELECT * FROM foods WHERE price >= 200;
で「price」が「200」以上のレコードが表示可能。
■ORDER BYにてソート
このままでは順番は変わらないので、ソートしたい場合は
SELECT [表示したいカラム名] FROM [テーブル名]
ORDER BY [ソートしたいカラム名] [asc or desc];例えば先程のイメージにて「price」が高い順に表示したい時は
# SELECT * FROM foods ORDER BY price desc;
とすれば「price」データが降順で表示される。
※asc:昇順、desc:降順
■GROUP BYにてグループ分け
下記コマンドにてグループ分けができる。
SELECT [表示したいカラム名] FROM [テーブル名] GROUP BY [グループ化したいカラム名];例えば下記イメージにてstoreの数ごとに見たい場合は、
下記コマンドにて実行。

SELECT store, count( * ) FROM foods GROUP BY store;
他にも「store」ごとの合計金額を出したい場合は
SELECT store, Sum(price) FROM foods GROUP BY store;
で表示できる。
【カラム追加と削除】
上記のイメージにて「store」を追加していたが、
下記コマンドにてカラムは追加できる。
ALTER TABLE [テーブル名] ADD [追加したいカラム名] [データ型] [NULL or NOT NULL];ALTER TABLE foods ADD store text;
逆に削除したい場合は下記コマンドにて削除可能。
ALTER TABLE [テーブル名] DROP COLUMN [削除したいカラム名];# ALTER TABLE foods DROP COLUMN store;
【データの更新】
入力したフィールドの値を変更したい時は、下記コマンドを実施。
UPDATE [テーブル名] SET [変更したいフィールドのカラム名] = [変更後の値]
WHERE [変更したいフィールドのレコード指定(主キー)];これで特定のデータを変更出来る。
例えば下記イメージの「apple」を「strawberry」にするなら

UPDATE foods SET name = 'strawberry' WHERE id='1';
要は、縦(nameカラム)決めて横(主キー(id)のレコード)決めて、
フィールドを変更する感じ。
ついでに言うと先程追加した「store」カラムは、
追加直後はフィールドにデータが入っていなかったので、
このUPDATEコマンドを使って入力した。
【レコード削除】
テーブルのデータを下記コマンドにて削除可能。
ただし削除出来るのはレコード単位のみ。
DELETE FROM [テーブル名] WHERE [削除したいレコードの指定];例えば下記イメージの「id」が「3」のレコードを削除したい時は

DELETE FROM foods WHERE id='3';
とすれば削除が可能。
【テーブル削除】
作ったテーブルごと削除する時は下記コマンドにて削除が可能。
DROP TABLE [テーブル名];これで基本的な操作は完了。
ちなみに大文字で書かれているところは分かりやすくしているだけなので、
コマンド入力する時は小文字で可能。
あと表示したいカラム名は「,」で区切ることで複数指定が可能。
【SQLコマンドまとめ】
データベース一覧取得
\l
テーブル一覧取得
\d
対象テーブルの フィールド一覧取得
\d [テーブル名]
データベース切断
\q
テーブル作成
CREATE TABLE [テーブル名]
([カラム名1] [データ型] [制約],
[カラム名2] [データ型] [制約],
〜
PRIMARY KEY (id));
テーブル削除
DROP TABLE [テーブル名];
データ挿入
INSERT INTO [テーブル名] ([カラム名1][,カラム名2]...) VALUES ([値1][,値2]...);
もしくは
INSERT INTO [テーブル名] VALUES ([値1][,値2]...);
データ検索
・基本形
SELECT [表示したいカラム名] FROM [テーブル名];
・絞り込み
SELECT [表示したいカラム名] FROM [テーブル名] WHERE [条件式];
・ソート
SELECT [表示したいカラム名] FROM [テーブル名]
ORDER BY [ソートしたいカラム名] [asc or desc];
・グループ分け
SELECT [表示したいカラム名] FROM [テーブル名] GROUP BY [グループ化したいカラム名];
カラムの追加
ALTER TABLE [テーブル名] ADD [追加したいカラム名] [データ型] [NULL or NOT NULL];
カラムの削除
ALTER TABLE [テーブル名] DROP COLUMN [削除したいカラム名];
データ更新
UPDATE [テーブル名] SET [変更したいフィールドのカラム名] = [変更後の値]
WHERE [変更したいフィールドのレコード指定(主キー)];
データ削除
DELETE FROM [テーブル名] WHERE [削除したいレコード指定(主キー)];【Herokuアップロード編】に戻られる方はこちら
この記事が気に入ったらサポートをしてみませんか?