
Pythonを用いた機械学習11日目

これまで機械学習に必要な数学の知識として、数列や確率について学んできた。今回は、大量のデータから標本を取り出すため乱数を生成したり、生成したデータが正規分布に従うのか確認したりしてみる。
前回の学習はこちらからどうぞ。
0.標本と推定
*推測統計学・・・母集団の一部(標本)を使って、母集団の情報(平均や分散)を推測すること
*点推定・・・標本平均を求めて、母平均も同じだとみなす考えかた
*区間推定・・・母集団が「正規分布」と仮定できるような状況で用いられる
*中心極限定理・・・使う標本の数nが十分に大きい場合、母集団からn個の標本を取り出したとき、その標本平均の分布は母集団の分布にかかわらず近似的に正規分布に近づく
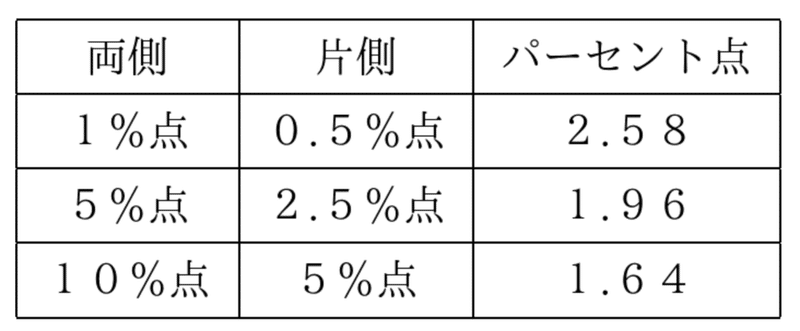
*95%信頼区間・・・母平均が95%の確率でその区間内に含まれるということ
<標準正規分布のパーセント点>
1.乱数の生成
交差検証を行うため、与えられたデータを訓練データとテストデータに分ける必要がある。訓練データをもちいて学習を行うが、訓練データに特化してしまう過学習を防ぐため、乱数をもちいる。
乱数を生成するときにはrandom関数をもちいる。コンピュータが扱う乱数は厳密には「模擬乱数」である。random.random()を繰り返し実行して抽出データを選択する。
*実行するたび違う乱数が生成されるコード
>>> import random
>>> random.random()
0.37425057885708957
>>> random.random()
0.6614368280316254
>>>
このrandom関数は一様分布から生成される「一様乱数」である。(一様分布とは確率変数xのどんな値に対しても、それが起こる確率が同じ確率分布)
*標準正規分布に従うことを確認するコード
>>> import random
>>> import collections
>>> import math
>>>
>>> r = []
>>> for i in range(1000):
... r.append(random.random())
...
>>> print(collections.Counter([math.floor(x * 10) for x in r]))
Counter({3: 115, 6: 103, 5: 101, 2: 101, 7: 100, 9: 99, 4: 96, 1: 96, 0: 95, 8: 94})5〜7行目:乱数を1000件生成しリストに格納
9行目:生成した乱数を、少数第一位で集計し出力
生成される値が正規分布に従う乱数を「正規乱数」といい、NumPyではrandn関数がある。
*乱数の分布を調べるコード
>>> import numpy as np
>>>
>>> n = np.random.randn(1000)
>>> print(np.mean(n))
-0.054786815017745696
>>> print(np.std(n))
0.990909357974588randn関数を使って乱数を1000個生成した。平均がほぼ「0」、標準偏差がほぼ「1」になっている。
一般的に、ニューラルネットワークの重みの初期値には正規分布が使われる。標準偏差などの設定についてはさまざまな研究が行われている。
ちなみに、randn関数の最後のnは正規分布を意味する「normal distribution」の頭文字。
2.確率分布を推定
*ノンパラメトリック・・・データから一切の分布を仮定しない方法
*パラメトリック・・・データがなんらかの分布に従うと仮定する方法
*最尤推定(さいゆうすいてい)・・・パラメトリックの手法の一つ。通常はパラメータを固定してデータを動かすことを考えるが、最尤推定はデータを固定してパラメータを動かす、ということを考えている。
*ベイズ推定・・・パラメトリックの手法の一つ。最尤推定に、事前確率も加味する。(ただし、その事前確率が信頼できない場合もあることに注意
次回は、確率や統計のまとめとして2つの練習問題に取り組む。
よろしければサポートお願いします。いただいたサポートを皆さんに還元していきたいと思っております。