
Pythonを用いた機械学習10日目

早いもので、更新10回目を迎えた。まだまだ先は長いがこれからも続けていきたい。
前回まで3回にわけて、統計学の知識として「確率」について書いている。今回まではPythonコードは少しそばにおいて、今日はベイズの定理についてまとめる。
前回の記事はこちら。同時確率と条件付き確率について書いている。
1.ベイズの定理
乗法定理におけるAとBを入れ替えると、以下の2つの式ができる。
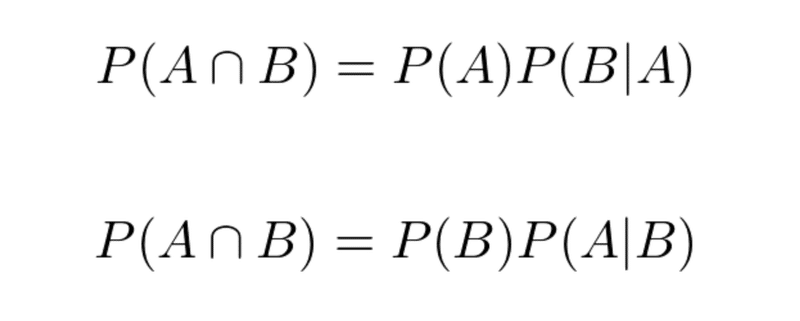
左辺が等しいので、右辺同士を等式で考えることができる。
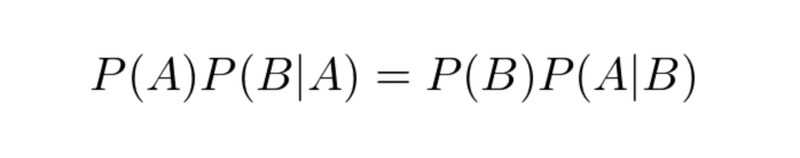
これを整理してP(A|B)を左辺に移動すると、以下のベイズの定理が得られる。
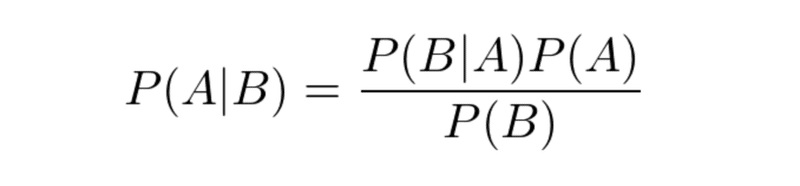
P(A)は「事前確率」、P(A|B)を「事後確率」、P(B|A)を「尤度(ゆうど)」という。
例題)メールが届いたときに、そのメールを見て迷惑メールかどうか判断したい。すでに受診トレイに多くのメールがある場合、このデータを使って分析する。
受診トレイに日本語のメールが200通、英語のメールが50通ある。このうち、日本語のメールのうち10通が迷惑メール、英語のメールのうち20通が迷惑メールだった。
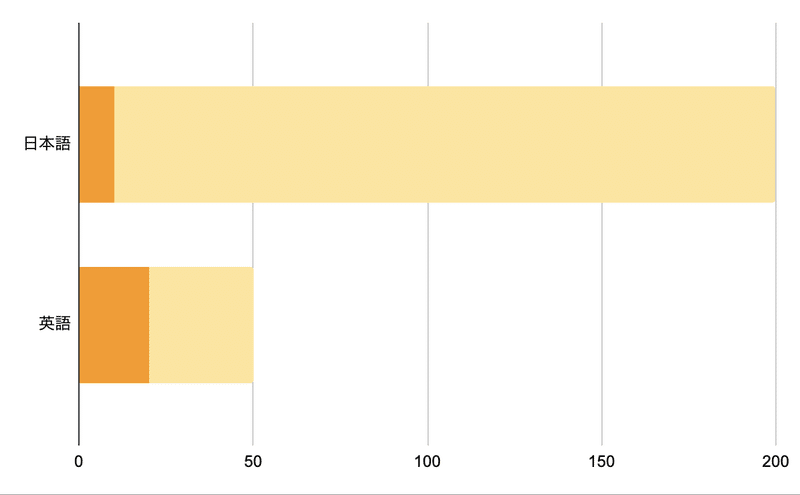
※濃いオレンジが迷惑メール
事象Aを「1通のメールを読んだとき、そのメールが迷惑メールである」、事象Bを「1通のメールを選んだとき、英語である」とする。条件付き確率を使って、P(B|A)とあらわすと、以下のように求められる。
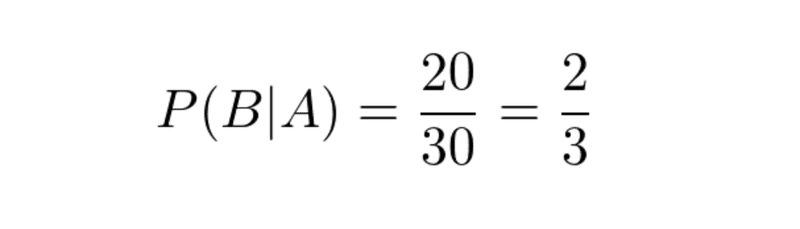
P(A)は250分の30、P(B)が250分の50なので、ベイズの定理に当てはめると以下のように求められる。
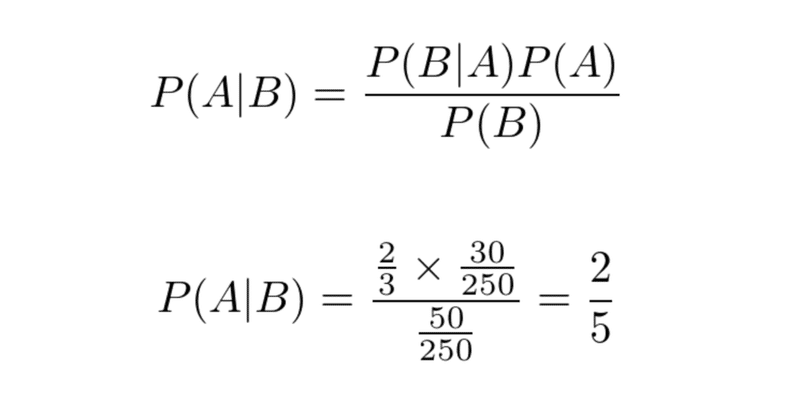
ベイズ更新について以下の資料がわかりやすかった。
2.ベイズ更新
上のメールの例で考えてみる。迷惑メールである場合(A)メールが英語である場合(B)に、さらにメールの特徴を追加してCとすると、以下の2つの式が成り立つ。
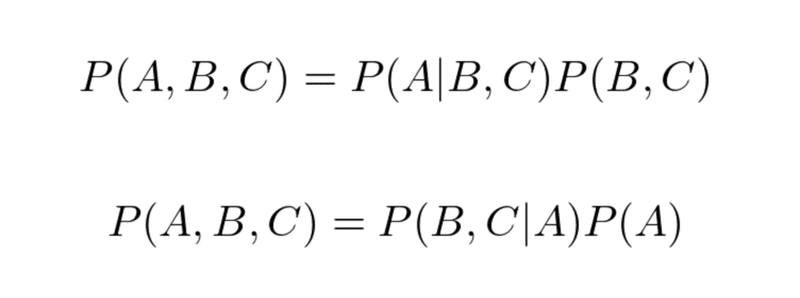
2つの式は右辺が同じなので繋げると、以下の式が得られる。
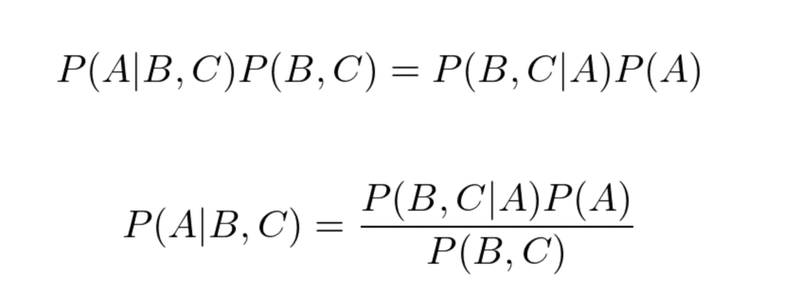
BとCは独立であるから
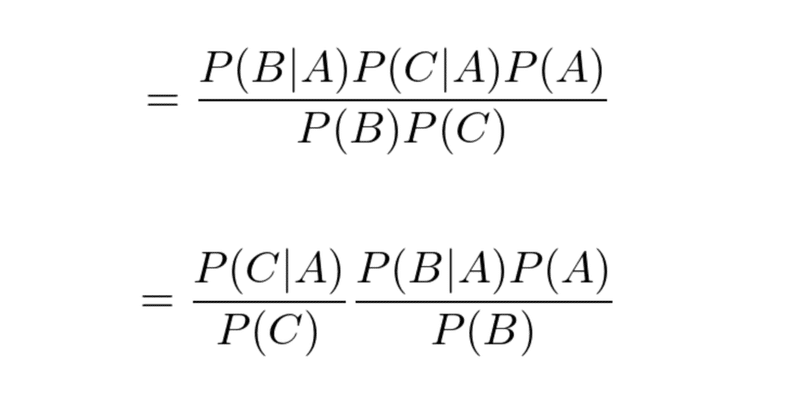
以下のように定義する(追加情報Cの事前確率だと考える)
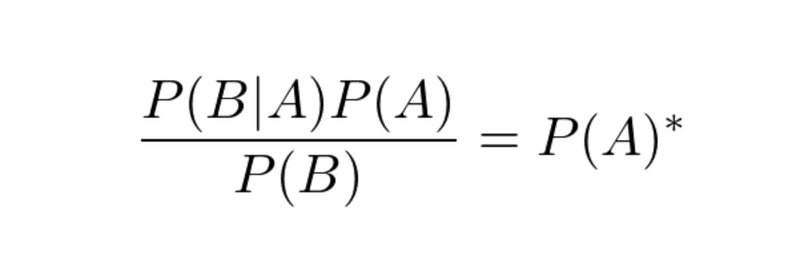
情報Bが与えられたときのAの事後確率を、新たな事前確率として、Cに独立に適用する。これをベイズ更新という。
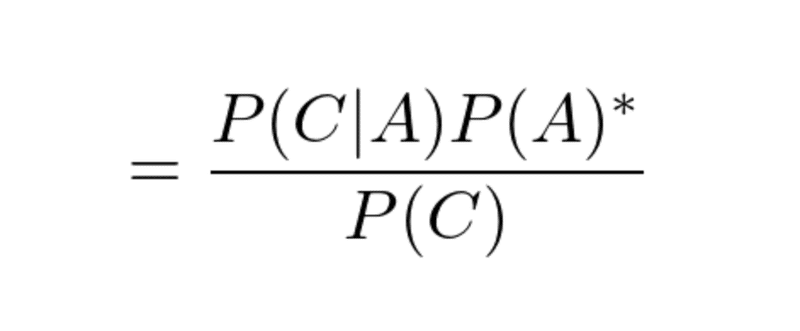
【感想】判断するための要素が増えるごとに、ベイズの定理を応用したベイズ更新を繰り返していくことで、確率が変わっていき、予測(迷惑メールかどうかの判断)の精度を高めていくようだ。
次回からPythonに戻り、大量のデータから標本を取り出すため乱数を生成したり正規分布に従うのか確認してみる。こちらからどうぞ。
よろしければサポートお願いします。いただいたサポートを皆さんに還元していきたいと思っております。