
手書き数字を機械学習させて人事ワークをスムーズに

筆者について
人材開発部門で働く30代女性です。
人事領域でも人の成長のアルゴリズムを可視化するために、AIやデータ分析の活用が近年注目されています。人事×データ分析を行うにも基本的な技術は知っておきたいよな〜、そして今後キャリアに役立つスキルも身に付けたいと思いAidemy Premiumにて「データ分析コース3ヶ月」の受講を開始しました。
ちなみに理系の「り」の字すら知らないアラサーです⭐︎
当ブログの情報が有益となる方
私自身、超文系ということもあり、プログラミング学習開始のハードルは正直高かったです。「私にできるかな?」「スクールに結構お金がかかるな」という雑念に1年程惑わされていました。
そんな過去の私のように悩みを持たれている方に有益な情報として、受講者側サイドの成長をお届け出来れば嬉しいです。
本記事の内容
このブログでは以下4つの事項についてご理解いただける内容となっております。
・分析結果
手書き数字の画像を機械学習させ、正しく予測を出すフローの紹介
・分析の応用アイデア
手書き数字認識がどのように研修領域で活かせるか
・Phythonを学習した感想
契約したスクールAidemy「データ分析コース3ヶ月」の受講感想
分析結果
今回は実行環境としてGoogle Colaboratoryを使用し、手書き数字画像を学習させ、何の数字が描かれているかを予測させるコーディングを作成しました。
ではでは、順を追って説明いたします!
◻︎データセットの取得
まずは、scikit learnに付属している手書き数字データセット「Optical recognition of handwritten digits dataset」と使用するライブラリを読み込みます。
import pandas as pd
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.metrics import accuracy_score
from PIL import Image
import numpy as np
digits=load_digits()初心者なので、都度「ではこれで何が表示されるのか?」を確認します。
#表をデータフレームに入れる
df=pd.DataFrame(digits.data)
df
行が数字の画像データでそれが1797行ある...つまりは1797個画像のデータがあることがわかりました。
はて、その画像データとやらはどんな形なのでしょうか?
機械学習に渡せるように横1列に並べたものを先頭の10個を取り出してみます。
#画像データを確認する
for i in range(10):
# 縦に10こ並べる
plt.subplot(10,1,i+1)
plt.axis("off")
plt.title(digits.target[i])
plt.imshow(digits.data[i:i+1],cmap="Greys")
plt.show()
え、ナニコレ?こんなので読み取れなくね?
ということでこれを8*8のサイズで横に10個並べてみます。
for i in range(10):
#横に10個並べる
plt.subplot(1,10,i+1)
plt.axis("off")
plt.title(digits.target[i])
plt.imshow(digits.images[i],cmap="Greys")
plt.show()
こうなってるのか!がわかりました。
しかしこのデータだと機械学習できないので、8*8の画像を1行64*1に変換したものを学習させます。
◻︎データを学習用とテスト用に分割
#数字の画像データ (digits.data)をXにする。何の数字か(digits.target)をyに入れる
X=digits.data
y=digits.target
#データを分割する
X_train, X_test ,y_train,y_test= train_test_split(X,y,random_state=0) #分割結果
print("train=", len(X_train))
print("test=", len(X_test))
念のためどのように分割されたかを確認すると、1795個あるうちの75%の1347個がtrain用に、25%がtest用に分かれていることを確認!
◻︎モデルを選んで学習開始
今回モデルには、画像認識で使われるSVM(サポートベクターマシン)を用いて予測モデルを作成し、評価します。
◽︎SVMとは?
SVMは、ロジスティック回帰と同じくデータの境界線を見つけ、サポートベクトルとよばれるベクトルを用いて境界線を作成してデータの分類を行う手法です。
サポートベクトルは、他クラスとの距離が近いデータ点です。それぞれのクラスのサポートベクトルからの距離(マージン)が最大となる位置に境界線を引きます。
出典:Aidemyカリキュラムより
SVMには線形SVMと非線形SVMが存在し、線形はロジスティック回帰と同様に入力データが線形分離可能でないと正しく分類ができないこともあるので、今回はカーネル関数と呼ばれる変換式に沿って非線形SVMを使用します。
#SVM サポートベクターマシンを使って学習を開始する #カーネル法のCVMを使用 #学習用データXとその答えyを渡して学習させる
model= svm.SVC(kernel="rbf", gamma=0.001)
model.fit(X_train, y_train)
#正答率をテストデータで調べる
pred=model.predict(X_test)
score= accuracy_score(y_test, pred)
print("正解率", score*100,"%")
正解率が99.5%となりました。
◻︎実際のデータで予測
ここから新しい値を渡して予測して行きます。
しかーし、その前にデータを用意しなければならないので、自分で数字をPC上で手書きしてみました。
ここから行うことは5つ
1:画像をアップロード
2:画像読み込んでグレースケールの画像に変換
3:画像を8*8に変換
4:色の濃度を変換
5:8*8データを1行データに変換
今回は試験的に「0」と書いた画像を用意して展開します。
1:画像データの取り込みは以下記事を参考にしました。
参照先:【Google Colaboratory】ファイルをアップロード・ダウンロードする方法
2:画像読み込んでグレースケールの画像に変換
#ファイルを読み込みこみ 、グレースケールに変換するためにconvert("L")を追加
image= Image.open("0.png" ).convert("L") #グレースケールでアウトプットしてみる
plt.imshow(image,cmap="gray")
plt.show()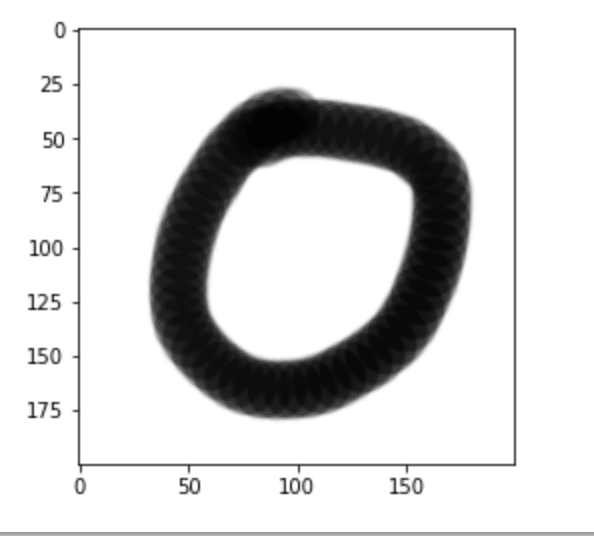
3:画像を8*8に変換
#8 *8に画像を変換する
image=image.resize((8,8), Image.ANTIALIAS)
plt.imshow(image, cmap="gray")
plt.show()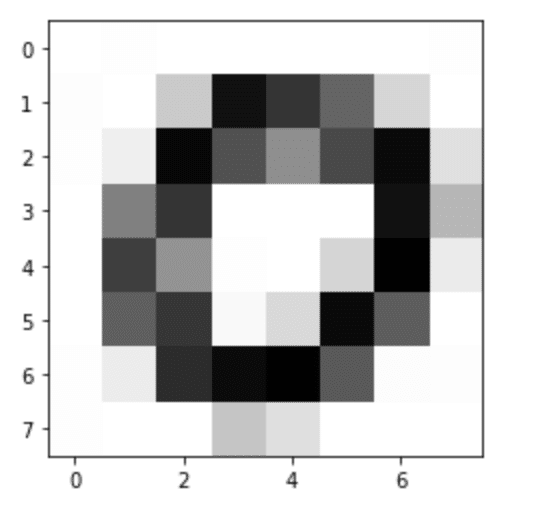
でた!これはデータを用意していた時に出力された感じと似ている事を確認。
4:色の濃度を変換
ここでは色の濃度を0~16の17段階に変換するのですが、手配したデータがどのような数値かを確認します。
img= np.array(image, dtype=float)
print(img)
え、全然17段階ではない...。ので今256段階のデータを17段階に変換しなければならないんです。
というわけで、0~255を17*値/256と計算して17段階に変換します。
#色の濃さを0 ~16の17段階に変換して1行データにする
img=16-np.floor(17*img/256)
img=img.flatten()
print(img)そして最後にmodel.predictで予測です。
predict= model.predict([img])
print("予測=", predict)![]()
うまく出ました!予測が「0」とデータと合致!良かったです!
同様に他のデータ1~9も無事に予測も外れることなく出来ました。
本来ならば、ここから混同行列(Confusion matrix)正解率(Accuracy)などを使用して多角的な考察をしたかったのですが、長くなってしまうので当ブログでは割愛させていただきます。
この機能をビジネスに活かすには?
昨今新型コロナウイルスの影響で、研修が全てオンラインへとシフトしました。人材育成側はいかに受講者の集中力を保たせるか必死なんです。つまりは研修にゲーミフィケーションを取り入れることが必須です。
例えば、ホワイトボードソフトを使用して「手書きで3択問題の答えを書いてみよう!」などを組み込み、それぞれの数字を上記のコードを元に予測させれば、研修進行に遜色なく、よりスムーズに楽しく受講者は参加できるかなと企んでいます。
Phythonを学習した感想
正直最初は分からないことだらけで不安になりました。
まずはコードの基礎を学ぶのですが、一体これを将来何に使うんだ..。みたいな絶望感に苛まれていました。
多分これってプログラミング初心者誰もが誰もが躓くところなんじゃないかと思います。どんな学習方法でも。
Aidemyさんは評判にもあった通り、チューターによるカウンセリングを受けることができ、躓いて先に進めないときにも「本当に優しく」導いてくれました。泣
実は始めた当初は「カウンセリングって言ったって、どうせ予約枠がすぐに埋まっちゃって、対応日が2営業日先とか何だろうな」と思っていました。しかし、バーチャルオフィスオープン時間であれば分からないところをすぐに聞けるという神対応で「分からない」→「分かる」スピードが非常に早かったです。ちなみにチューターの方から「分からないので、次回までに調べますね」という対応は一切なかったので、質の高い講師陣を揃えていることが伺えました。
私のような文系出身でプログラミング初心者の方は、Aidemyさんのようなサポートの厚いスクールに課金されることをオススメします。
他の会社さんは入学時に比較をしなかったのでわかりませんが、サポート内容を比較して、ご自身にあったスクール選びをされるといいと思います。
反省点としては6ヶ月コースにすれば良かったと思います。
プログラミングを学び始めて、もっと学びたい!これはどうなっているのだろう?と興味が湧いたのと、惰性で学習が後半詰め詰めになってしまったので、受講料は上がりますが十分な学習期間で契約すれば良かったかなと。
まだまだコードを書くのに時間はかかりますが、このスキルで研修および人事データからの分析に革命を起こすべく、PM目指して頑張ります!
この記事が気に入ったらサポートをしてみませんか?