
HADを使ってみた:9.平均値の推定

HADを使ってみたときのあれこれを書いていますが,【分析】フォームの「データの要約」をひととおり終えたので,ここからは「差の検定」グループに入ります。なんとなーく始めてしまった感じなのですが,まあ,やり始めたことだし,放送大学の学生が心理統計を勉強するときの参考になればいいなあと思いつつ,HADの出力通りにRに出力させることを目標に,Rのスキルを高めるという,どうでもいいような楽しみを目指して,続けていきましょう。
平均値の推定
【分析】メニューには「平均値の推定」とありますが,これは「一標本t検定」のことですね。平均値の区間推定を行うことと,平均値が指定した値と等しいかどうかを検定する分析のようです。
サンプルデータの中から, factor を使ってみましょう。このデータの出所を私は良く知らないのですが,要約統計量を見ると,最小値が(v1だけは2ですが)1,最大値が5,すべて整数のデータなので,何かの尺度(5件法)を用いた調査結果,という想定ですね。平均値がほぼ3なので,回答がある方向に偏っていることはなさそうです。これを用いて,平均値の推定をしてみます。分析手順は次の通り。
検定したい変数を好きなだけ並べる
⇒【分析】
⇒「平均値の推定」
⇒「検定値」を指定してOK
以下では,v1, v2, v3, v4, v5 の5つを使用変数に指定し,検定値には「3」を指定しました。出力はこんな感じです。

95%信頼区間の右にある「95%精度」は耳慣れない用語ですが,95%信頼区間の半分の値になっています。グラフの設定を調べると,この値をエラーバーの描画に使っていますので,そのための数値でしょう。「差」は指定した検定値(出力では「基準値」となっています。今回は3を指定しました)と,平均値との差,その右側が検定結果ですね。v1 と v5 だけが,p値が0.05を下回っていますので,平均値が3よりも有意に高いことがわかります。ただし,差はせいぜい 0.15 程度ですので,これがどれくらい意味のある差なのかは研究者の判断ですね。
さて,グラフは差がものすごく強調されて描かれています。Y軸原点が3になっているのは,検定値を3に指定したからで,いろいろ試すと,グラフの設定で,Y軸原点を指定した検定値にしているようです。しかし,平均値より高い点(たとえば4とか)にしたら棒グラフが下向きになるか? というと,なりません。どうしてもしたい場合は自分で設定する。
そんなことより,Y軸の値が 3~3.3 と狭い範囲であることに注意が必要ですね。実際,Y軸の設定を変えると下の図みたいになって,「どこが有意差なの?」ってなるので。(5件法なので値の範囲は1~5です。なのでY軸を1~5の値に設定し直しました。そのほかの設定は触っていません。)

…なんか,「統計でウソをつく法」って本に似たようなことが書いてありましたね。おお,懐かしい。懐かしいので(?)リンク張っておきましょう。
Rでやってみよう
HAD2Rは,こんなコードを出してくれました。
dat <- read.csv("... /csvdata.csv")
t.test(dat$v1, mu = 3)
t.test(dat$v2, mu = 3) ...
t.test( ) はt検定をする関数で,mu= で真の平均値を指定していますね。これを実行すると,たとえば,

というふうに結果が出ますね。平均値(mean of x)も,95%信頼区間(95 percent confidence interval)も,t検定の統計量もp値も出てきます。余談ですが,Rの出力って基本,英語なので,この出力結果を読みながら,alternative hypothesis とか, confidence interval とか,統計用語の英語の言い方を多少覚えた,というか,慣れたように思いますね。estimate とかも頻繁にお目にかかります。HADは日本語で出してくれるので,両者を見比べると訳語がわかる。というか,HADは英語モードや中国語モードもあるので,そこでわかる。それってけっこうすごいかも。閑話休題。
しかし,残念ながらプロットは出てきません。まあ,そこまで必要なプロットかどうかはわからないのですが,Rの練習としてやってみましょう。barplot( )関数を使うのですが,この関数は,具体的な数値を渡してやらないとグラフを描いてくれない。そこで,要約統計量を出して,平均値の部分だけを渡してやることにしましょう。とりあえず,
subdat <- dat[, c("v1","v2","v3","v4","v5")]
x <- describe(subdat)
barplot(x$mean)
で,出力されるのがこんな感じ。うーん,地味。というかつまらん。

これに,エラーバーをつけて,変数名を下に表示する,ぐらいはやってみよう。ということでコードを追加して,ついでに出力される統計量もHADに合わせてみた。けっこう長くなってしまったけど。
MU <- 3
library(psych)
d1 <- describe(dat[, c("v1","v2","v3","v4","v5")], skew=F)
d1$diff <- d1$mean - MU
for (i in 1:(nrow(d1))) {
res <- t.test(dat[,row.names(d1[i,])], mu=MU)
d1$df[i] <- res$parameter
d1$t[i] <- res$statistic
d1$p[i] <- res$p.value
d1$CI.low[i] <- res$conf.int[1]
d1$CI.up[i] <- res$conf.int[2]
d1$CI.wid[i] <- (res$conf.int[2]-res$conf.int[1])/2
}
d <- d1[,c("mean","se","CI.low","CI.up","CI.wid","diff","df","t","p")]
colnames(d) <- c("Mean","Std Err",
"CI.lower","CI.upper","CI.width",
"diff","df","t-value","p-value")
print(d, digits=3)
bp <- barplot(d1$mean, ylim=c(0, ceiling(max(d1$mean)+max(d1$se))),
names.arg = row.names(d1), col = "white")
arrows(bp, d1$mean-d1$CI.wid, bp, d1$mean+d1$CI.wid,
code=3, lwd = 1, angle=90, length=0.1)
abline(0, 0)


出力はこんな感じ。漢字の使用をやめてみた。理由は表示したときに列幅がずれるから。フォントをMSゴシックにするとずれないけれど,フォントの見た目が好きではない。
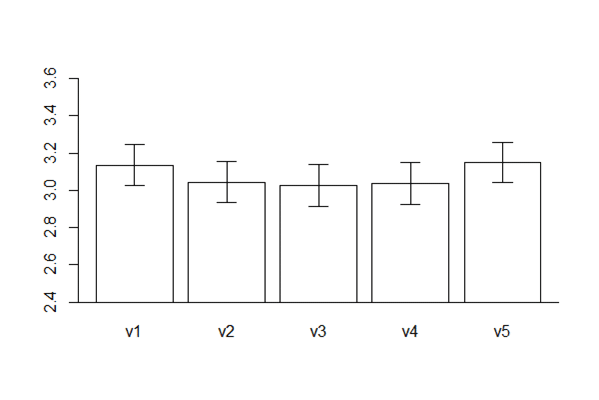
もうちょっと差を強調したいなあと思ったら,プロットの設定をいじる必要があって,たとえばこんな感じ。ofs という変数でY軸の範囲を指定しているのだけれど,これをデータから自動的に判断させるのはどうすればいいんだろう。ちょっと面倒な感じがするのでやめておいたけれど。あと,指定した検定値の高さに水平線入れても良かったかも。今気が付いたけれど。
ofs = c(2.4, 3.6)
bp <- barplot(d1$mean-ofs[1], ylim=ofs, names.arg = row.names(d1),
col = "white", offset=ofs[1])
arrows(bp, d1$mean-d1$CI.wid, bp, d1$mean+d1$CI.wid,
code=3, lwd = 1, angle=90, length=0.1)
abline(ofs[1], 0)
今回参考にしたのはこのサイトでした。平均値差の検定で,プロット上にアスタリスクを描く方法も解説されているので,いずれ試してみましょう。