Elasticsearch RAG と Amazon Bedrock との連携がもたらす AI ソリューションとは?

大規模言語モデルは推論に向く
データベースではない
トレーニングに依存する
最新情報や特定の情報に弱い
生成AIと利点と限界
利点
人間のような処理
自然な会話や文章の作成、サンプルプログラムの作成など
限界
公開されたデータしか知らない
トレーニングされた後にデータは知らない
結果にブレが有り、間違った回答も返す
コストとプライバシー
非公開データへの生成AI対応方法
Fine Tuning
大規模言語モデルを非公開データに対してトレーニング
時間とコストが掛かり、新しいデータに対して継続的にトレーニングが必要
RAG(Retrieval Augmented Generation)
追加データをコンテキストとして元の質問とともに大規模言語モデルに送付
コンテキストのサイズに制限がある
費用が高額になる
文章生成と検索でコストが1000倍違う
文章生成>検索
ESRE(Elasticsearch Relavance Engine)
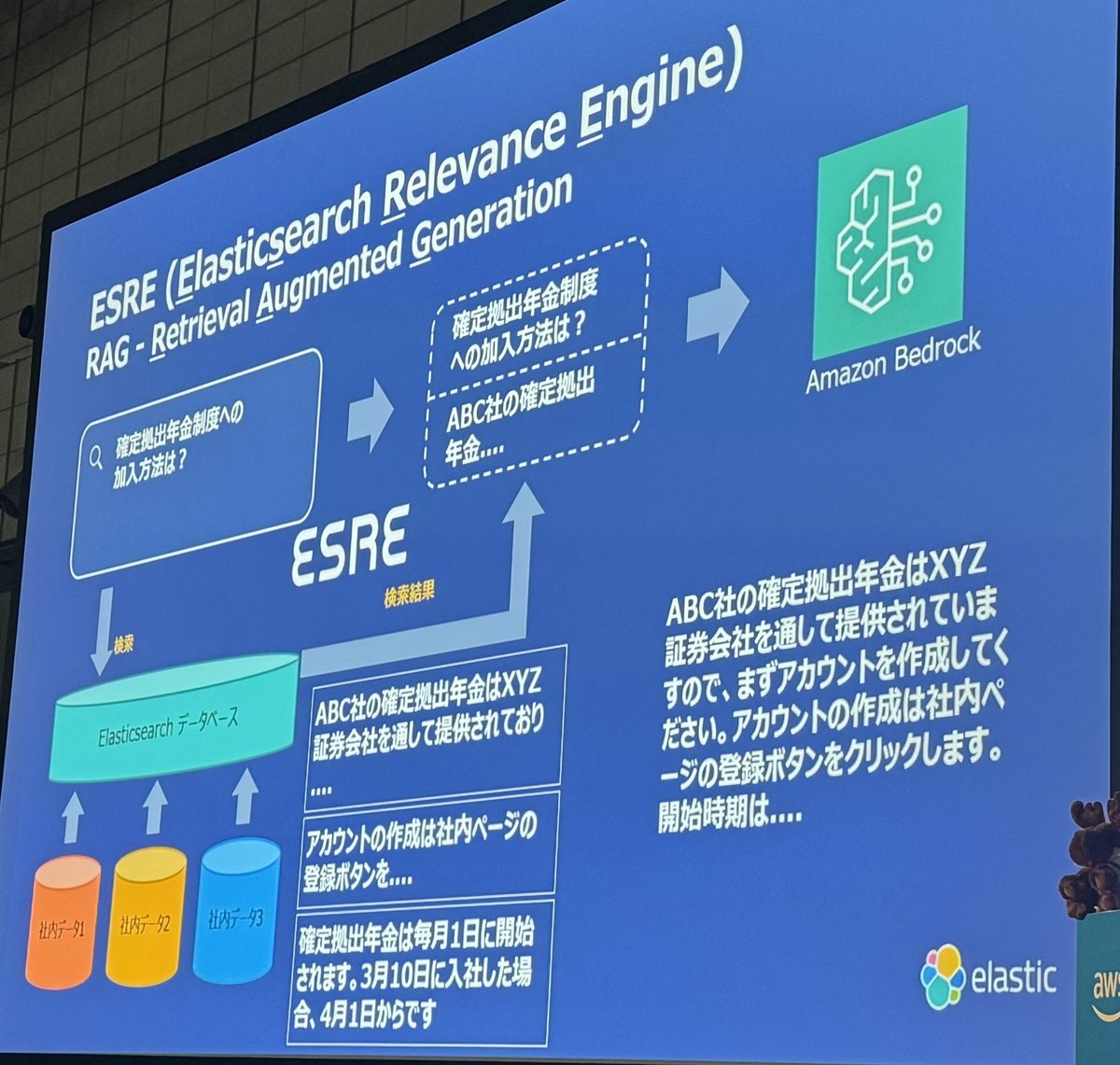
RAGが検索で正しい検索がかえってくるかどうか
検索の重要性
RAGを行う上で、コンテキストに正しい情報が入っている必要がある
元データ
ドキュメントレベルの権限等、元々のデータが正しくないと意味がない
検索
通常検索
キーワードが含まれていれば(同義語辞書を含めて)正しい結果を返す
逆に入っていないと結果が返ってこない
チューニングの方法は豊富にある
ベクトル検索
キーワードが入っていなくても文脈で近しいものを返す
かなり離れたものを返してくる可能性がある
モデル選定も含めてチューニングが難しい
これからハイブリッド検索が注目されると思う
更にそれをReRAGした方が良い
ハイブリット→生成AIで要約が良さそう
→検索という部分をしっかりまず考えてほしい
AI Assistant
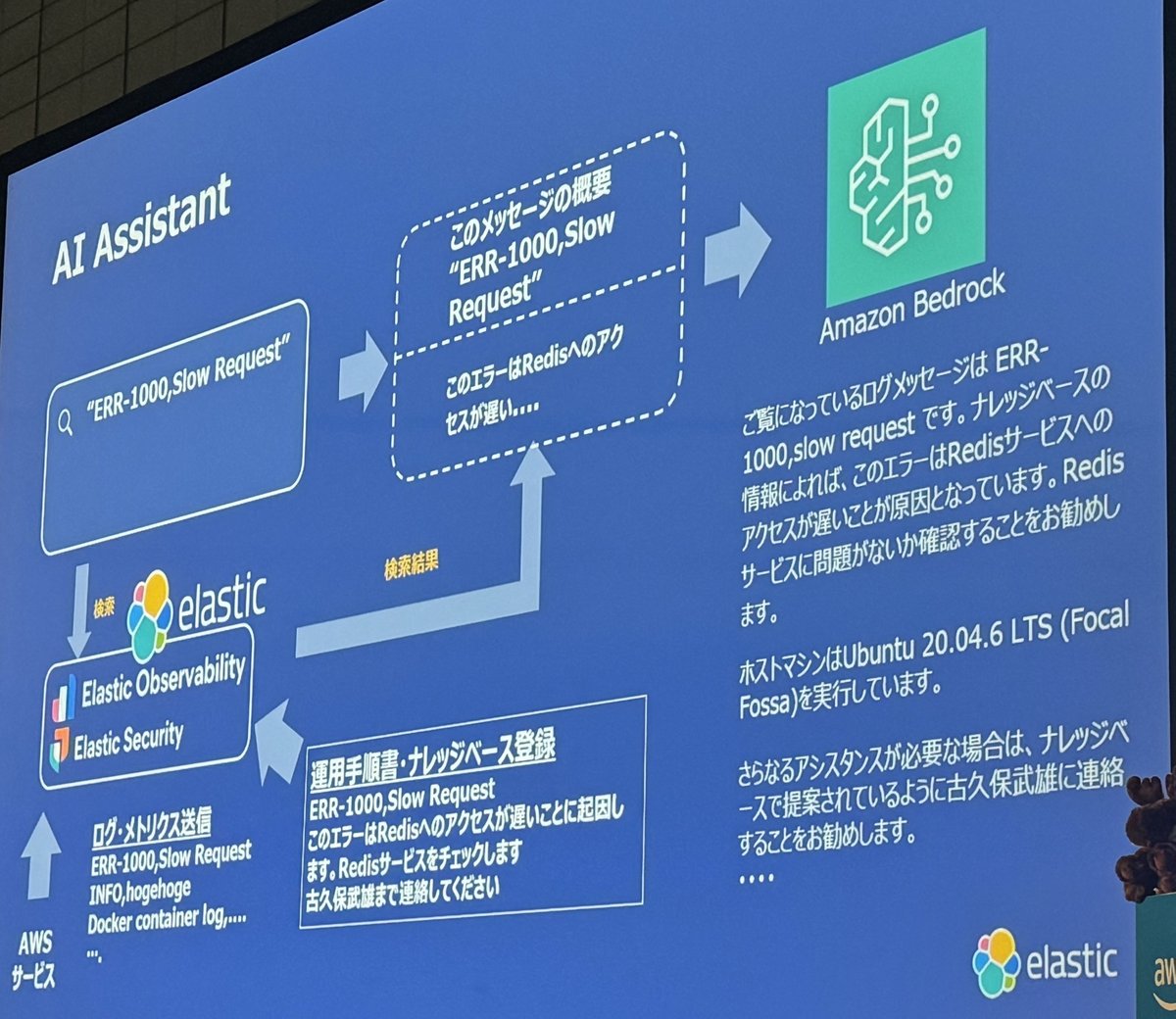
人間が判断できる材料をいかに早く見つけて、人間が判断できるかが今の使命だと思ってる
何故検証がうまくいかないのか?
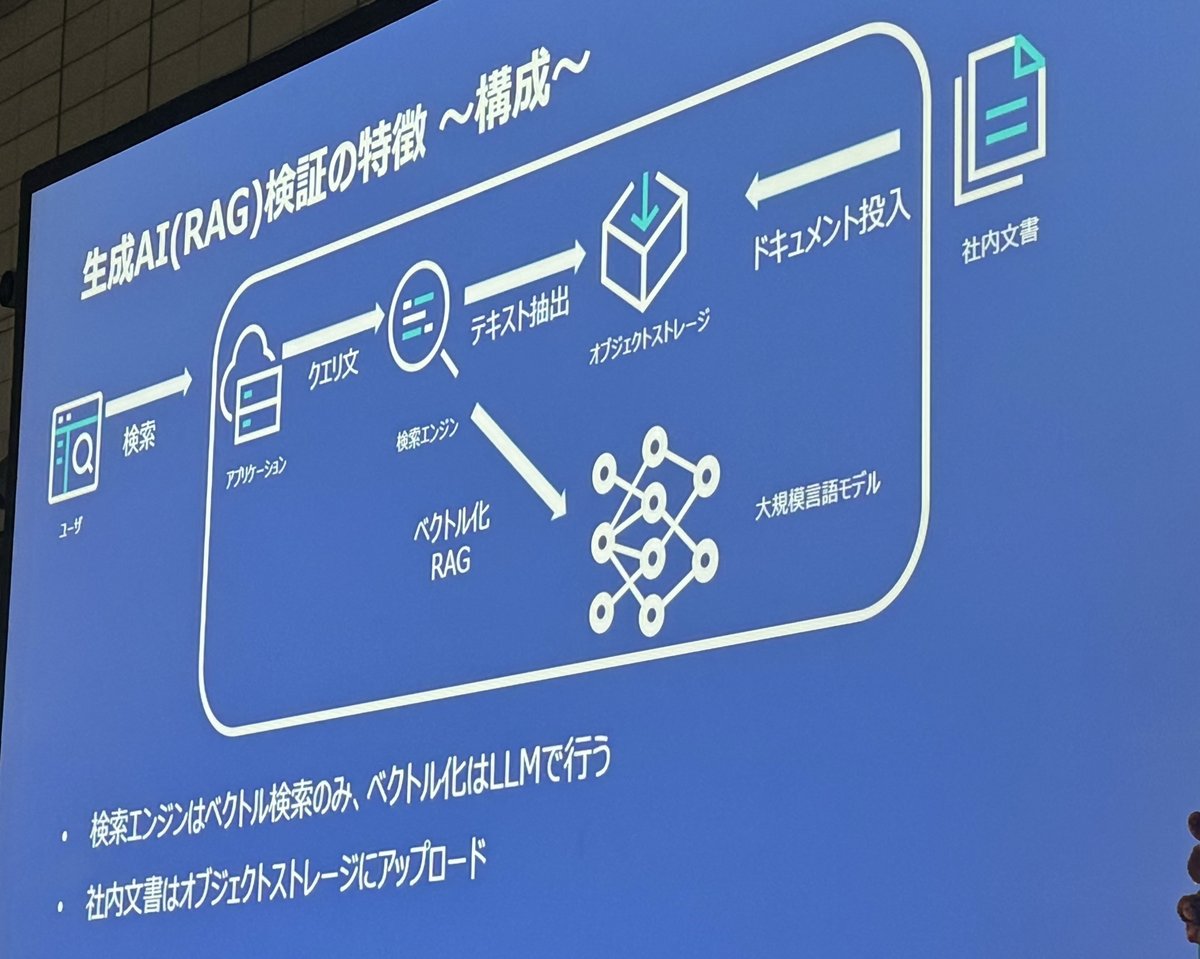
生成AI(RAG)検証の特徴〜問題点〜
出力結果だけ見ていないか?
文書をオブジェクトストレージにとりあえずアップロード
実運用で全てクラウドにアップロードできるのか?
→オンプレミスでの運用が不可能になる
閲覧権限が設定されていない
→人事の資料が一般社員の検索結果に出てしまうような問題が起きる
→ドキュメントをどのようにインデックス化するかを一番最初に決めないといけないのに考慮されていない
→404じゃなくて、見えている時点で問題なので検索から弾くべき
検索エンジン
ベクトル検索のみで行なっている
→検索精度が上がらない時に取れる手段が少ない
→フィルターや並べ替えなどの当たり前の機能が作れない
→最初にインデックスがとにかく大事
→ベクトル検索だけは難しい
→社内用語があると精度が落ちる
キーワード検索の自由度が低い
→日本語検索特有の難しさに対応しにくい
→チューニングが必要
→タイトルでヒットしたらboostしたり、ランキング変更などきめ細やかな調整が難しい
→検索精度が上がらない時に取れる手段が少ない
検索結果の解析
ゼロヒット(検索結果該当なし)やクリックなし(検索結果が妥当ではない)を解析して継続してチューニングを行う基盤が必要
→検索結果の解析をちゃんとしないといけない
→検索結果を残しておくべき
検証の目的
検証の内容が大規模言語モデルの使い方になっていないか?
チャンキングやプロンプトエンジニアリングをどんなに検証しても、コンテキストに入るデータが間違っていたら何も検証できない
→目的と手段が入れ替わっていないか
検証構成
ベクトル検索・大規模言語モデル両方とも深い知見は普通は持っていない
→よくわからないものを2つ同時に検証できるか?
生成AI(RAG)成功の秘訣
検索結果が正しいかどうかから始める
検索にはキーワード検索とベクトル検索の2種類があり、ベクトル検索は必須ではないし、万能でもない
何もチューニングしないと検索精度はあまり高くなく、チューニングの方法はキーワード検索には豊富にあり、ベクトル検索はうまくいかなかった際に改善の手段が少ない
検索として当然持つべきであるフィルター機能等はテキストが入っていないとできない
→でも、強力ではある
実用では必ず必要になるドキュメント権限を考慮する
検索は新しいドキュメントが追加されるごとに検索精度が落ちていくため、検索精度を監視して改善していく仕組みが必要
データの置き場所を考慮する

この記事が気に入ったらサポートをしてみませんか?