
【第1回】LlamaIndexチュートリアル|LlamaIndexの仕組みについて学ぶ

LlamaIndexとは
LlamaIndex は、独自データを活用したQ&Aやチャットボットなどのアプリケーションを構築するための技術です。
LLMと外部のデータを連携させる方法は大きく2つあります。
LLMをFine-tuningする
入力プロンプトにコンテキストを埋め込む
LlamaIndexは後者の実装を助けてくれる技術になります。
また、後者の手法で作成されたアプリケーションをRAG(Retrieval Augmented Generation)と呼びます。
RAGの基本構成
RAGは基本的に2つのステップで構成されています。
インデックス:外部データから知識ベースを作成
クエリ:質問に関連するコンテキストを取得して、回答を出力する
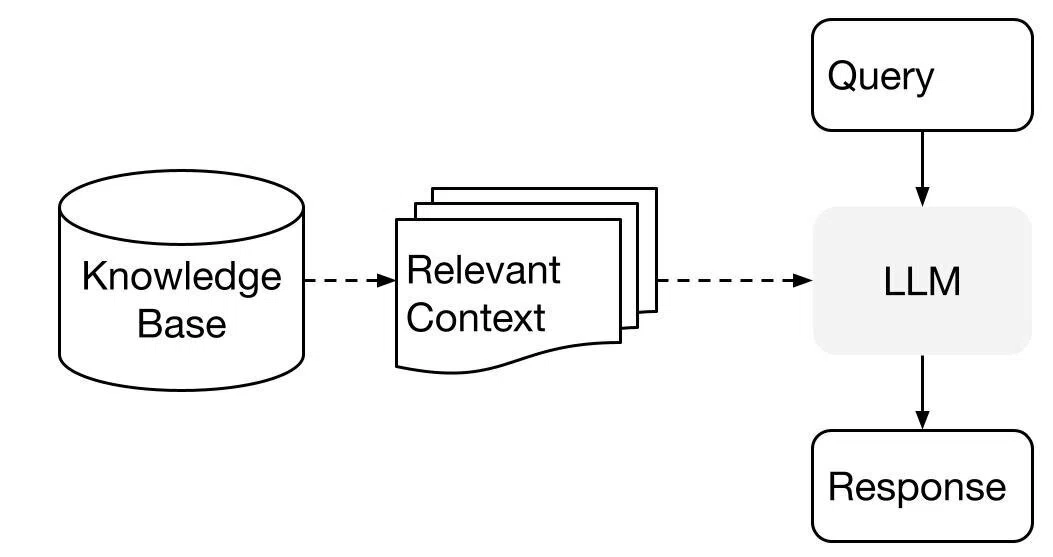
LlamaIndexはインデックスとクエリの両方を簡単に実装するためのツールを提供しています。
インデックス
知識ベースを作成するための流れは次のとおりです。

様々な外部データ(Data Source)を単純なドキュメントに変換します。
必要なデータのみを取得できるように、ドキュメントにインデックス付けを行う。
これらの処理を行うためにツールが提供されています。
Data Connectors(LlamaHub)
API、PDFなど異なるデータソースやデータ形式から単純なドキュメント(テキスト+メタデータ)に取り込みます
data connectors はLlamaHubを通じて取得することができます。
LlamaHubでは様々なサービスやデータフォーマットに対応した data connectorが提供されています。
Documents / Nodes
LlamaIndexの中心的な概念にDocumentとNodeというオブジェクトがあります。
Document は、どんなデータソースでも格納できる汎用的なコンテナです。Documentは手動で作成することも、Data Connectorsを使用して作成することもできます。
Nodeとは、Documentの一部を指します。これはテキストであったり、画像であったりします。
LlamaIndexでは、Documentはさまざまなデータソースを保存するコンテナとして、Nodeはその中の具体的な部分や断片を表すものとして機能しています。
Index
indexは、ユーザーのクエリに関連するコンテキストを迅速に取得するためのものです。
indexにはさまざま種類がそれぞれ向き不向きがあります。indexをうまく使い分けることが非常に重要になります。
クエリ
クエリのフェーズでは、ユーザーからのクエリ(入力)から最も関連性の高いコンテキストを取得し、それをクエリとともにLLM に渡して応答を生成します。
これにより、元のトレーニング データにはない最新の知識が LLM に与えられるのです。

Retriever
クエリが与えられたときに知識ベースから関連するコンテキストを取得する方法を定義するためのものです。
Node Postprocessor
Retrieverにより抽出されたノードについて、後処理を行うためのものです。
Response Synthesizer
ユーザーのクエリと特定のテキストチャンクを使用して、LLM からの応答を生成します。
まとめ
今回はRAGの基本的な仕組みとそれを実現するためのLlamaIndexのモジュールについて学びました。
次回はこれらのモジュールを使って簡単なアプリケーションを作っていきたいと思います。
参考
この記事が気に入ったらサポートをしてみませんか?