
【プログラミング初心者】全くゼロから試しに「機械学習」をやってみる

概要
「機械学習」の意味もわかっていない初心者が、「機械学習」ができるかやってみました。
制作環境
使用言語:Python3
使用するPC:Intel iMac
使用ブラウザ:Chrome
使用するエディタ:Google Colaboratory
課題について
目的:プログラミング初心者が、売上の予測をプログラミングできるか
課題を選択した理由:「売上」を使用したデータを用いて、将来的に自分で機械学習アプリを作れるように、「Restaurant Revenue Prediction」を選びました。
分析の目標:商業データから、店舗の年間売上を予測
評価指標:RMSE ( Root Mean Squared Error )
補足:Kaggleとは 年間通して機会学習のコンペが開かれているサイト。
専門的な言い回しが多いため、Google翻訳でもわかりにくい場合があります。
Restaurant Revenue Prediction
Predict Future Sales
対応手順
データを読み込む
読み込んだデータの中身を見る
データの前処理をする
評価スコアを確認する
予測に寄与した特徴量を確認する
考察
参考にさせていただいたサイト
重回帰分析を用いた売上予測
【Python超初心者】KaggleのRestaurant Revenue Predictionに挑戦してみました。
Kaggle - 初心者でも取り組みやすいコンペの紹介
【scikit-learn】ラッソ回帰、リッジ回帰で過学習の改善・防止
train_test_split()関数の使い方について
リッジ回帰の実装
最短でリッジ回帰とラッソ回帰を説明(機械学習の学習 #3)
Pythonでリッジ回帰を実装
リッジ回帰とラッソ回帰の理論と実装を初めから丁寧に
リッジ回帰(L2正則化)を理解して実装する
プログラミング
1. データを読み込む
Kaggleからデータをダウンロードして、Google Calaboratoryにアップします。今回は、 Kaggleからデータをダウンロード済みのため、以下のどちらかの対応を行う必要がありました。
Google Calaboratoryのフォルダを開いて、ファイルをアップする(この場合、セッションが切れると、ファイルを再格納する手間が生じる)
個人のGoogle Driveにアップし、Google Calaboratoryから常時アクセスさせる許可をする
# ZIPファイルを配置、読み込む
import zipfile
# zipが格納されているフォルダの中に、CSVを保存する
with zipfile.ZipFile('restaurant-revenue-prediction/train.csv.zip') as zf:
zf.extractall('./restaurant-revenue-prediction/')
with zipfile.ZipFile('restaurant-revenue-prediction/test.csv.zip') as zf:
zf.extractall('./restaurant-revenue-prediction/')2. 読み込んだデータの中身を見る
ダウンロードしたKaggleのサイトより、各データのファイルの中身は以下のようになっていました。
train.csv(学習用のデータ)
・店舗のデータが含まれる(137店舗分)
・売上データがある
test.csv(検証用のデータ)
・店舗のデータが含まれる(100,000店舗分)
・売上データがない
csvデータの各見出しの詳細
Id :レストランID。
Open Date :レストランの開店日
City: レストランがある都市。名前にはUnicodeが含まれていることに注意してください。
City Group:都市のタイプ。大都市、またはその他。
Type:レストランのタイプ。FC:フードコート、IL:インライン、DT:ドライブスルー、MB:モバイル
P1、P2-P37:これらの難読化されたデータには3つのカテゴリがあります。 人口統計データ は、GISシステムを使用するサードパーティプロバイダーから収集されます。これらには、特定の地域の人口、年齢と性別の分布、開発規模が含まれます。 不動産データ は、主に場所のm2、場所の正面ファサード、駐車場の空き状況に関連しています。 商業データ には、主に学校、銀行、その他のQSRオペレーターを含む関心のあるポイントの存在が含まれます。
Revenue:収益の列は、特定の年のレストランの(変換された)収益を示し、予測分析の対象になります。値は実際のドル値を意味しないように変換されることに注意してください。
データを「df_train」と「df_test」に格納します。
格納後、CSVの中身を確認するため、表示してファイルの中身を見ながら、前処理(機械学習をするために、データを使いやすいように加工すること)を行います。
import pandas as pd
# データの読み込み
df_train = pd.read_csv('./restaurant-revenue-prediction/train.csv')
df_test = pd.read_csv('./restaurant-revenue-prediction/test.csv')
# データの中身を確認する
print('Train Shape: {}'.format(df_train.shape))
print('Test Shape: {}'.format(df_test.shape))
combine = pd.concat((df_train, df_test), ignore_index=True)
df_train.head()
df_test.head()
3. データの前処理をする
予測分析の対象となる「revenue」をデータから抜き出します
「train(訓練データ)」「test(検証データ)」を1つのファイルにまとめることで、それぞれのファイルに加工するのではなく、まとめて加工処理しました
「Open Date」は「str(文字列)型」のため「int(整数)型」に事前に加工して使いやすいようにしておくことにしました。加工は、年・月・日・営業日数などの数字データとして抽出しました
「City」「City Group」「Type」も「Open Date」と同じように、int型として使用できるように加工しておきました
すべての加工を行った後、データを元に戻します
# 前処理をする
import datetime
from sklearn.preprocessing import LabelEncoder
#目的変数を抽出
revenue = df_train["revenue"]
del df_train["revenue"]
#前処理がしやすい様に、trainとtestを結合
df_whole = pd.concat([df_train, df_test], axis=0)
#Open Dateを年・月・日に分解
df_whole["Open Date"] = pd.to_datetime(df_whole["Open Date"])
df_whole["Year"] = df_whole["Open Date"].apply(lambda x:x.year)
df_whole["Month"] = df_whole["Open Date"].apply(lambda x:x.month)
df_whole["Day"] = df_whole["Open Date"].apply(lambda x:x.day)
combine['Open Date'] = pd.to_datetime(combine['Open Date'])
#オープンしている日数も追加(直近の場合は0)
df_whole['Open Date'] = pd.to_datetime(df_whole['Open Date'])
lastdate = df_whole['Open Date'].max()
df_whole['OpenDays'] = (lastdate - df_whole['Open Date']).dt.days
df_whole['Open Date'] = pd.to_datetime(df_whole['Open Date'])
lastdate = df_whole['Open Date'].max()
combine['OpenDays'] = (lastdate - combine['Open Date']).dt.days
#Cityを数値に変換
le = LabelEncoder()
df_whole["City"] = le.fit_transform(df_whole["City"])
# City Groupを数値に変換 Other -> 0, Big Cities -> 1
df_whole["City Group"] = df_whole["City Group"].map({"Other":0, "Big Cities":1})
#Typeを数値に変換 FC -> 0, IL -> 1, DT -> 2, MB -> 3
df_whole["Type"] = df_whole["Type"].map({"FC":0, "IL":1, "DT":2, "MB":3})
# # このあとDataFrameからPandasに変換して読み込む必要を省略したい場合は、ここを使う
# df_whole.drop('Id', 'Open Date', axis=1, inplace=True)
# 中身の確認
df_whole.head()
#再びtrainとtestに分割
df_train = df_whole.iloc[:df_train.shape[0]]
df_test = df_whole.iloc[:df_test.shape[0]]
# 中身の確認
df_train.head()
df_test.head()4. 評価スコアを確認する
「ラッソ回帰」「リッジ回帰」「ElasticNet」「ランダムフォレスト」を用いて、RMSEのスコアを確認しました
※「import」は省略
arr=df_train.iloc[:,2:].values
X = df_train.iloc[:,2:]
y = revenue
# 学習用、テスト用にデータを分割する(1:1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
names = ['ラッソ回帰', 'リッジ回帰', 'ElasticNet', 'ランダムフォレスト']
models = [Lasso(), Ridge(), ElasticNet(), RandomForestRegressor()]
max_score = 0
best_model = 10**8
# RMSE スコアを表示
for name, model in zip(names, models):
model.fit(X_train, y_train)
score = np.sqrt(mean_squared_error(y_test, model.predict(X_test)))
# score = np.sqrt(mean_squared_error(X_test, y_test)) #model.score(X_test, y_test)
print("{}: {}".format(model, score))
if score < best_model:
best_model = score
best_model_name = name
print()
print("ベストモデル: {}".format(best_model_name))
print("ベストスコア: {}".format(best_model))出力結果:
ベストモデル: ランダムフォレスト
ベストスコア: 2552887.755777927
5. 予測に寄与した特徴量を確認する
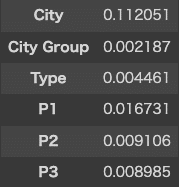
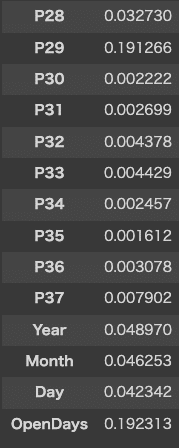
収益を表す「revenue」が、どの値によって変化するのかを確認します。
表示されたグラフから確認する限り、「City」「P29」「OpenDays」で収益が大きく変化があることがわかりました。
# 特徴量を出す
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
%matplotlib inline
sns.set()
# X = revenue
X_train = StandardScaler().fit_transform(X_train)
# StandardScaler y_trainは、このままでは使えないので、変換の必要がある
y_train = y_train.values.reshape(len(y_train),1)
y_train = StandardScaler().fit_transform(y_train)
y_train = y_train.reshape(len(y_train))#元の形に戻す
# ランダムフォレスト
clf3 = RandomForestRegressor().fit(X, y)
plt.plot(clf3.feature_importances_, label='RandomForestRegressor', color='b', linestyle='--')
plt.xlabel('Features', fontsize=12)
plt.ylabel('Coefficient', fontsize=12)
plt.legend();
Coefficientの軸(y軸):寄与度
ランダムフォレストで表示(日本語が文字化けするので欄外に説明記載)
6. 考察
本来であれば、最も利益が高くなる「P29」の値がどのような情報なのかを確認して、収益への影響を調査できたらよかったのですが、Kaggleの「csvデータの各見出しの詳細」の「P1、P2-P37」の項目には、詳細が記載されていないため、影響の理由についての調査は行えませんでした。
例えば、大きなショッピングセンターのテナントの1つだった。例えば、駐車場が広くて家族連れで訪れることのできる店舗だった。
などの理由により、収益が大きく増加したと考えられます。
P1、P2-P37:これらの難読化されたデータには3つのカテゴリがあります。 人口統計データ は、GISシステムを使用するサードパーティプロバイダーから収集されます。これらには、特定の地域の人口、年齢と性別の分布、開発規模が含まれます。 不動産データ は、主に場所のm2、場所の正面ファサード、駐車場の空き状況に関連しています。 商業データ には、主に学校、銀行、その他のQSRオペレーターを含む関心のあるポイントの存在が含まれます。
反省点・今後の課題
収益(revenue)を目的変数とした機械学習のやり方を自分で組み立てることができたおかげで、今後、自分自身がECサイト運用に携わっていった際に、このプログラムを参考に、機械学習を組み立てることができるのではとちょっとだけ思いました。
データの加工、どの学習器を使うのか、評価の方法など、エラーばかりでなかなか進まず、チューターの方にたくさん質問と相談をして組み立てたプログラムなので、教わる度にまだまだ理解ができていないところを見つけるばかりでした。それでも、このプログラムをきっかけに、次もやってみようと思えたのが、何よりの収穫でした。
「機械学習」の意味もわかっていない初心者でも、「機械学習」はできました。
まだまだ、若葉マークは外せなさなそうですけども。
この記事が気に入ったらサポートをしてみませんか?