
新聞社の管理職がChatGPTやデータサイエンスを学ぶ意義とは

はじめに
DXの障壁は管理職?
新聞社もDX(デジタルトランスフォーメーション)が叫ばれて久しいですが、なかなかうまくいっていないかもしれません。今までなかったどうでもいい仕事(いわゆるbullshit jobs)が増えている印象すら抱いている向きも少なくないでしょう。個人的には管理職の理解不足が大きな障壁になっていると感じています。現場の記者がいろいろ試してみたいと思っても、管理職がやらせてくれない、無関心、やるなら勝手にやれ―。口ではハッキリ言われないまでも、なんとなく社内にそんな空気が漂っていないでしょうか。ChatGPTなどのAIやノーコード、ローコードのサービスが急速に普及する中、新聞社の管理職が積極的に学ぶようになってはじめて、新聞社も紙面も近未来に向けてもっと充実していくのではないかと考えています。
このエントリーでは、グーグルカレンダーに入力された膨大なデータ(※架空のデータ)をヒートマップに落とし、「取材が手薄なエリア」を浮き彫りにする方法を書きたいと思います。Google Apps Script(GAS)を使います。※駅やコンベンション施設、大学など日々の取材が実際に多い施設を踏まえた上で今回のエントリー用にランダムに創出した架空データを使用します。現実のデータを使っているわけではありませんので、ご承知おきください。
グーグルカレンダーからヒートマップを作る
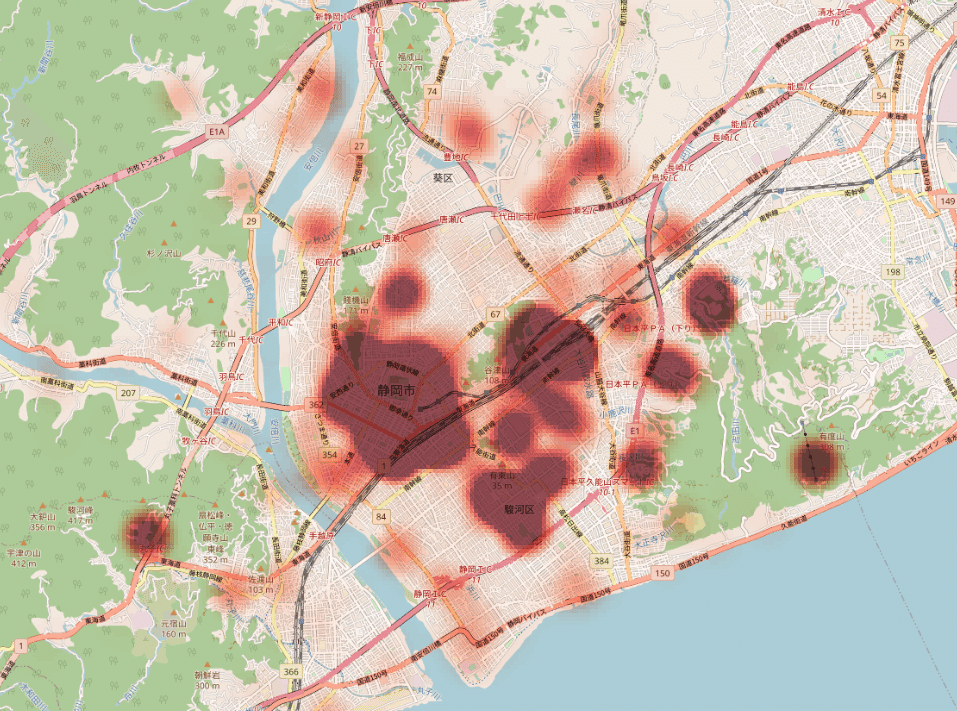
1.「取材が手薄なエリア」を浮き彫りにする
最終的な成果物は次の図です。日々の取材が多い場所と少ない場所が一目瞭然です。浮かび上がった「取材が手薄なエリア」に記者を集中的に投入して街ネタを探してもらうなどという次の手が期待されます。
2.カレンダーデータのエクスポート
まず、グーグルカレンダーで日々の取材予定を管理していることが前提です。カレンダー左下の「マイカレンダー」から任意のカレンダーを選択し、右端の縦3点リーダをクリック→「設定と共有」を選択してください。
設定画面で「エクスポート」を選び、カレンダーのデータを取得します。詳細は公式のGoogle カレンダーを書き出すを参照してください。ICSファイルですが、普通にSpreadsheetなどで開くことができます。
カレンダーのデータは一連の項目がセットになって成り立っています。分かりやすい項目を抽出すると次のような項目です。
DTSTART:スケジュールの開始時間
DTEND:スケジュールの終了時間
CREATED:スケジュールを入力した時間
DESCRIPTION:スケジュールの詳細(メモ)
LAST-MODIFIED:スケジュールの最終更新時間
LOCATION:スケジュールの場所
SUMMARY:スケジュールのタイトル(カレンダーに主に表示される概要)
3.ChatGPTとの共同作業でデータを整形
ここからChatGPTに手伝ってもらいましょう。詳細は割愛しますが、次のようにChatGPTと一緒に処理を作り上げていくイメージです。ヒートマップを描くために、住所が同じ取材予定の数(頻度)をカウントしておきます。
(プロンプト1)
A列からLOCATIONだけを取り出して新しい配列に格納するApps Scriptを書いてください。
(プロンプト2)
A列にアイテム名(スケジュールのタイトル)が並んでいます。アイテム名とカウント数を新しい配列に格納するApps Scriptを書いてください。
(プロンプト3)
A列にアイテム名が並んでいます。明らかに表記ゆれと思われるアイテム名があれば、より長いほうのアイテム名に統一して名前を変更するApps Scriptを書いてください。
(プロンプト4)
処理のタイムアウトやネットワークの負荷を軽減するため、アルゴリズムを見直した上で、バッチ処理を行うように書き直してください。
(プロンプト5)
A列のLocationから半角スペースに続いて"静岡県"で始まる住所を抽出し、新しいシートに出力するApps Scriptを書いてください。
次のようなスクリプト(関数)が完成しました。コピペして実行します。



4.緯度・経度を求める(ジオコーディング)
次に住所から緯度・経度を求めます。いわゆる「ジオコーディング」です。ここでは東京大学空間情報科学研究センターが提供しているCSVアドレスマッチングサービスを使わせてもらいます。
5.QGISでヒートマップを描く
出力されたCSVファイルからヒートマップを作るため、今度はQGISを開きます。ブラウザから「XYZタイル」→「Open Street Map」を選ぶと地図のレイヤが作成されます。メニューから「レイヤ」→「レイヤを追加」→「CSVテキストレイヤを追加」とし、作成したCSVファイルを読み込みます。
追加されたデータのレイヤプロパティを開き、「シンボロジ」→「単一定義(single)」なっているものを「ヒートマップ」に変更、「点の重み付け」をカウントした頻度とします。レイヤの混合モードは乗算にします。細かい部分を調整して完成です。

6.記者単位でヒートマップを描けるようにする
さらに、普段から取材予定のタイトルの冒頭などに取材する(取材した)担当記者名を入力するようにしておくと、記者単位でヒートマップを描けるので便利です。以下のようなプロンプトをChatGPTに伝えることで、記者ごとにヒートマップを描くための初期データを作成するスクリプトができます。
プロンプト
記者名を変数とし、任意の記者名が概要に含まれるデータを抽出して記者名を付けた新規シートに書き出すようにApps Scriptを書いてください。
架空のデータを使って架空の記者Aと記者Bのヒートマップを描いてみたのが次の図です。


こうしたヒートマップを基に、それぞれの記者が行ったことのないような場所に水を向けてみるなんてことができたら、それぞれの記者にとっても、気分転換になり、新しい発見が得られるかもしれません。
まとめ
管理職こそDX模索を
上記の処理をするのにこれまで丸一日かけてコードを書いていましたが、ChatGPTの登場で短時間でやりたい処理ができるようになりました。管理職こそChatGPTやノーコード、ローコードのサービスを賢いパートナーとして活用して取材の効率化や現場の負担軽減を図り、記者のパフォーマンスをいかに100%引き出してあげられるか模索してみてはいかがでしょうか。
新聞社は本来DXと相性が良い
新聞社には日々の記事がデータベースで蓄積するだけでなく、今回書いたように日々の取材スケジュールなどもデータとして膨大に蓄積されていきます。本来、新聞社の仕事とDXは非常に相性の良いものです。次回以降、記者の掲載面(1政、1社など)ごとの行数を機械学習で分析したり、広報メモが出る頻度をポワソン分布と仮定して一定枚数以上のメモが出る確率を求めたり、前日の気象予測データから翌日の広報メモの件数を予測したり―なんてことも書いていきたいと考えています。
お読みいただきありがとうございました。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?