
PythonでPath操作(pathlib)

PythonでPath情報やファイル名を取ったり、名前を変えたりするのっていろんな方法があります。そんな時に、pathlibというのが結構便利だったりします。
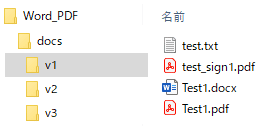
このようなフォルダ構成を題材にします。
基本(パスの登録)
Path("パス名")とするとPathが登録されます。
from pathlib import Path
dir=Path(r"C:\Word_PDF\docs")
print(dir)
dir実行すると
WindowsPath('C:/Word_PDF/docs')と出てきます。ここで出来たdirはどういったタイプなのでしょうか。以下を実行してみます。
print(dir)
type(dir)すると
C:\Word_PDF\docs
pathlib.WindowsPath
と出てきました。printするとテキストのような感じがしますが、typeで確認するとPathを指定する特殊な型のようです。
Pathの存在確認
指定したPathが実際に存在するかどうかの確認はexists()で行います。
dir.exists()あれば”True”なければ"False"が返ります。
Pathのつなぎ方
次にPathのつなぎ方です。
dir2=dir/"v1"スラッシュ(/)でつなぐだけで新しいPathが作れます。+でつないだり、format形式にしたりしなくていいので見やすいです。
ファイル名・拡張子の取り出し

ファイル名を取り出したいときは、.nameを使います。これを実行すると、'test_sign1.pdf'が返ってきます。
pdf_path=dir2/"test_sign1.pdf"
pdf_path.name.suffixだと拡張子('.pdf')が返ります。
pdf_path.suffix.stemで、拡張子のないファイル名('test_sign1')が得られます。
pdf_path.stemファイル名や拡張子の変更
ファイル名の変更には、".with_name"を使います。ただし、例えば、
new_txt = txt.with_name("test2.txt")
だけでは変更はされず、その後に、
txt.rename(new_txt)
とすると初めて実際のファイルに変更が加えられます。
from pathlib import Path
# 元のファイルパス
txt = Path("C:/Word_PDF/docs/v1/test.txt")
# 新しいファイル名に変更
new_txt = txt.with_name("test2.txt")
# ファイルを新しい名前に変更(実際のファイルが変更される)
txt.rename(new_txt)拡張子の変更も同様です。拡張子の変更には".with_suffix"を使います。
拡張子指定のときは
new_csv = txt.with_suffix(".csv")
のように、拡張子の前に"."(ピリオド)が必要です。
globと一緒に

globと一緒に使うと実用的になってきます。
dir.glob("*")これを実行すると、
<generator object Path.glob at 0x0000019C535C3230>
という実行結果になります。この中にr"C:\Word_PDF\docs"の情報が詰まっています。
これを使って、配下のフォルダ構造をリスト化します。
[*dir.glob('*')]とすることで、このようにリスト化されます。
[WindowsPath('C:/Word_PDF/docs/v1'),
WindowsPath('C:/Word_PDF/docs/v2'),
WindowsPath('C:/Word_PDF/docs/v3')]例えば、フォルダ内にあるPDFファイルのパスだけを欲しい時は以下のようにします。
[dir.glob('v1/*.pdf')]結果はこのようになります。
[WindowsPath('C:/Word_PDF/docs/v1/Test1.pdf'),
WindowsPath('C:/Word_PDF/docs/v1/test_sign1.pdf')]他の方法と比べても、とても簡単に取得できますね。
match()で文字列検索
pathの中に特定の文字列が含まれているかどうかを調べるにはmatch()関数を使います。
pdf_path=dir2/"test_sign1.pdf"
pdf_path.match("v1/*")pdf_pathは、'C:/Word_PDF/docs/v1/test_sign1.pdf'なので、"v1"の後に何か文字列があれば"True"が返ります。この場合は"test_sign1.pdf"があります。
ただこのmatch()は、右側から一致しているかどうかを判定するので、"test*とか"*.pdf"とか"docs/*/*"はTrueとなりますが、"docs/*"はFalseとなります。右側で一致しないからですね。

この記事が気に入ったらサポートをしてみませんか?