
Pythonでワードクラウド

ちょっとテキストマイニングのまねごとをしてみます。
サンプルデータはこのようなものです。
病名がリスト化されたシンプルなテキストファイルです。

まずはこれをデータフレーム化します。このテキストにはHeaderがないのでヘッダーも指定してデータフレームを作成します。
import pandas as pd
headers = ['AE_Name']
df = pd.read_table('Adverse events.txt',names=headers)
dfheadersというリストを作り、それをnamesで指定してあげることでheaderが作れます。

これを、最近ニュースでもよく見る「ワードクラウド」という視覚化の方法でVisualizeしてみます。
コードはとてもシンプルです。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pandas as pd
headers = ['AE_Name']
df = pd.read_table('Adverse events.txt',names=headers)
txt = " ".join(ae.lower() for ae in df["AE_Name"])
wordcloud = WordCloud().generate(txt)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()WordCloud、matplotlibの2つのライブラリを追加し、対象データをtxtという変数にスペース区切りで格納、それをプロットするだけです。
結果は以下のとおりです。
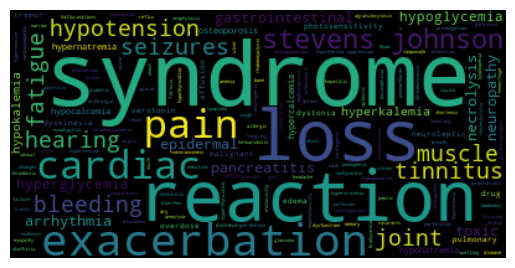
本当はもう少し前処理をしなければいけないのですが、まずはPythonで簡単にワードクラウドが実現できることの紹介でした。
この記事が気に入ったらサポートをしてみませんか?