
プロンプトエンジニアがプロとして成立する事例: 自然言語処理応用

前回、専門知識を利用したプロンプトの事例を2つだけ紹介しました。
今回は、特に専門知識が必要で、さらにプロンプトの開発そのものが専門的であることを証明する事例を紹介いたします。
応用編: エラーの特定と修正
まず初めに、余力があれば下記の課題にぜひチャレンジしてみてください。

「断片」のテキストファイルは ↓こちらです。
相当工夫をしないと、「100%精度」の条件を達成できず、エラー(ハルシネーション)になってしまいます。この課題自体、半分GPT-4に作らせたのですが、作らせてそのまま解答を聞いたら即間違えたぐらいに、GPTを困らせる内容です。
この "工夫" の部分は、これから紹介する自然言語処理の専門知識で突破することができます。
ちなみに、カテゴリが「人物名」であるというのは、例えば「田中太郎」とか「マイケル」とかです。ある特定の文章から、カテゴリが「人物名」の単語を抽出するタスクを完璧に実出力し続けたい…そんな時に活躍するプロンプトを開発してみます。
ということで、前回と同じ形式で今回もプロンプトを比較していきます。
専門的なプロンプトと一般的なプロンプト
一般的なプロンプト:
「カテゴリが「人物名」であると文脈から判断できる単語だけを抽出してください。」
専門的なプロンプト:
「ネームドエンティティ認識 (NER)の原理と、リレーショナルエンティティ抽出モデルの原理に則って、カテゴリが「人物名」であると文脈から判断できるエンティティだけを抽出してください。」
下記が、一般的なプロンプトの出力結果です。
青色のフォーカス部分が、一般的なプロンプト固有の部分です。

ご覧の通り、とても間違っています。
次に、専門的なプロンプトの出力結果です。
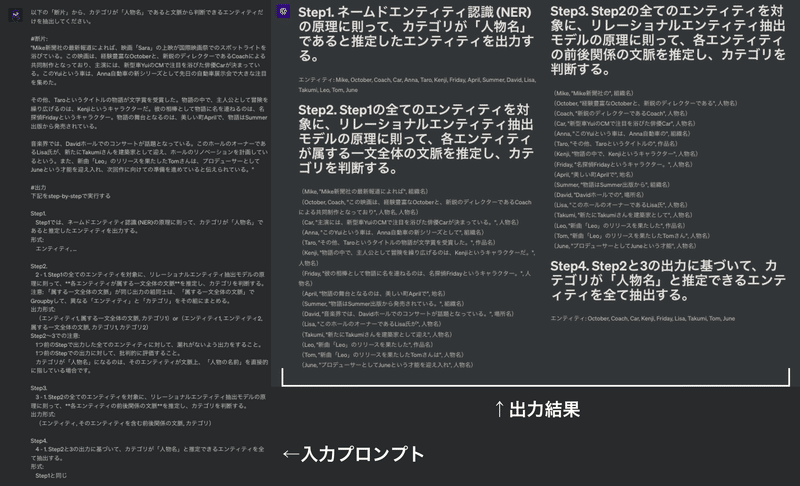
こちらは完全正解していますね。
入力プロンプトが長文に見えてしまうのですが、一般的なプロンプトと異なるのは、概ね、中央あたりの「#出力」以降の下半分のみです。
「100%精度」については、20回中20回、連続でクリアしました。
21回目はまだ試していないのですが、プロセスもバッチリなのでおそらくクリアし続けると思われるので、かなり精度は高いんじゃないかなと思います。
↓実際の専門的なプロンプトは↓こちら。
以下の「断片」から、カテゴリが「人物名」であると文脈から判断できるエンティティだけを抽出してください。
#断片:
"Mike新聞社の最新報道によれば、映画「Sara」の上映が国際映画祭でのスポットライトを浴びている。この映画は、経験豊富なOctoberと、新鋭のディレクターであるCoachによる共同制作となっており、主演には、新型車YuiのCMで注目を浴びた俳優Carが決まっている。このYuiという車は、Anna自動車の新シリーズとして先日の自動車展示会で大きな注目を集めた。
その他、Taroというタイトルの物語が文学賞を受賞した。物語の中で、主人公として冒険を繰り広げるのは、Kenjiというキャラクターだ。彼の相棒として物語に名を連ねるのは、名探偵Fridayというキャラクター。物語の舞台となるのは、美しい町Aprilで、物語はSummer出版から発売されている。
音楽界では、Davidホールでのコンサートが話題となっている。このホールのオーナーであるLisa氏が、新たにTakumiさんを建築家として迎え、ホールのリノベーションを計画しているという。また、新曲「Leo」のリリースを果たしたTomさんは、プロデューサーとしてJuneという才能を迎え入れ、次回作に向けての準備を進めていると伝えられている。"
#出力
下記をstep-by-stepで実行する
Step1.
Step1では、ネームドエンティティ認識 (NER)の原理に則って、カテゴリが「人物名」であると推定したエンティティを出力する。
形式:
エンティティ, ...
Step2.
2 - 1. Step1の全てのエンティティを対象に、リレーショナルエンティティ抽出モデルの原理に則って、**各エンティティが属する一文全体の文脈**を推定し、カテゴリを判断する。
注意: 「属する一文全体の文脈」が同じ出力の組同士は、「属する一文全体の文脈」でGroupbyして、異なる「エンティティ」と「カテゴリ」をその組にまとめる。
出力形式:
(エンティティ1, 属する一文全体の文脈, カテゴリ1)or(エンティティ1, エンティティ2, 属する一文全体の文脈, カテゴリ1, カテゴリ2)
Step2〜3での注意:
1つ前のStepで出力した全てのエンティティに対して、漏れがないよう出力をすること。
1つ前のStepでの出力に対して、批判的に評価すること。
カテゴリが「人物名」になるのは、そのエンティティが文脈上、「人物の名前」を直接的に指している場合です。
Step3.
3 - 1. Step2の全てのエンティティを対象に、リレーショナルエンティティ抽出モデルの原理に則って、**各エンティティの前後関係の文脈**を推定し、カテゴリを判断する。
出力形式:
(エンティティ, そのエンティティを含む前後関係の文脈, カテゴリ)
Step4.
4 - 1. Step2と3の出力に基づいて、カテゴリが「人物名」と推定できるエンティティを全て抽出する。
形式:
Step1と同じこのプロンプトのどの部分が専門的なのか
ポイントは下記です
1. 「単語」ではなく「エンティティ」で表現
2. 「ネームドエンティティ認識 (NER)」と「リレーショナルエンティティ抽出モデル」のそれぞれの "原理" を指示
3. 「属する一文全体の文脈」と「前後関係の文脈」を具体的に指示
4. そもそもの期待値を上げるためにCoT(step-by-stepでタスクを分解指示する汎用的な手法のこと)
1〜3については、自然言語処理の専門知識を有していると可能になります。例えば、ネームドエンティティ認識は↓こちらの記事で触れたものです。
1と2は、専門用語をキーワードとしてプロンプトに打ち込むことで、GPTに対して方向性を指定できる期待があると考えています。
この辺りの専門知識をなくしたの下記のプロンプトでも、比較検証してみました。
以下の「断片」から、カテゴリが「人物名」であると文脈から判断できる単語だけを抽出してください。
#断片:
"Mike新聞社の最新報道によれば、映画「Sara」の上映が国際映画祭でのスポットライトを浴びている。この映画は、経験豊富なOctoberと、新鋭のディレクターであるCoachによる共同制作となっており、主演には、新型車YuiのCMで注目を浴びた俳優Carが決まっている。このYuiという車は、Anna自動車の新シリーズとして先日の自動車展示会で大きな注目を集めた。
その他、Taroというタイトルの物語が文学賞を受賞した。物語の中で、主人公として冒険を繰り広げるのは、Kenjiというキャラクターだ。彼の相棒として物語に名を連ねるのは、名探偵Fridayというキャラクター。物語の舞台となるのは、美しい町Aprilで、物語はSummer出版から発売されている。
音楽界では、Davidホールでのコンサートが話題となっている。このホールのオーナーであるLisa氏が、新たにTakumiさんを建築家として迎え、ホールのリノベーションを計画しているという。また、新曲「Leo」のリリースを果たしたTomさんは、プロデューサーとしてJuneという才能を迎え入れ、次回作に向けての準備を進めていると伝えられている。"
#出力
下記をstep-by-stepで実行する
Step1.
Step1では、カテゴリが「人物名」であると推定した単語を出力する。
形式:
単語, ...
Step2.
2 - 1. Step1の全ての単語を対象に、**各単語が属する一文全体の文脈**を推定し、カテゴリを判断する。
注意: 「属する一文全体の文脈」が同じ出力の組同士は、「属する一文全体の文脈」でGroupbyして、異なる「単語」と「カテゴリ」をその組にまとめる。
出力形式:
(単語1, 属する一文全体の文脈, カテゴリ1)or(単語1, 単語2, 属する一文全体の文脈, カテゴリ1, カテゴリ2)
Step2〜3での注意:
1つ前のStepで出力した全ての単語に対して、漏れがないよう出力をすること。
1つ前のStepでの出力に対して、批判的に評価すること。
カテゴリが「人物名」になるのは、その単語が文脈上、「人物の名前」を直接的に指している場合です。
Step3.
3 - 1. Step2の全ての単語を対象に、**各単語の前後関係の文脈**を推定し、カテゴリを判断する。
出力形式:
(単語, その単語を含む前後関係の文脈, カテゴリ)
Step4.
4 - 1. Step2と3の出力に基づいて、カテゴリが「人物名」と推定できる単語を全て抽出する。
形式:
Step1と同じこちらの成績が17/20回でしたので、この3回の差分が上記の1と2による影響かなと考えています。なぜなら、出力に最も影響を与えるのはプロンプトであり、そのプロンプトの差分はこの1と2のみだからです。
次に、3についてちょっとギークな話をします。
「 "原理" に則って」の意味
このプロンプトの目的は「その原理のロジックを模倣して処理又は演算してほしい」と指示することなのですが、この時に注意があります。
その原理が、入力するLLMにそもそも内蔵されている処理であれば、プロンプトで指示する必要はない(だろう)という点です。
前回の↓こちらの記事に書いた内容を引用します。
原理原則に立ち返ると、出力結果に最も影響を及ぼすのはプロンプトであるはずです。そのプロンプトが違うのに、出力結果に差分がないとすると、下記のいずれかだと思われます。
A)そのプロンプトの差分は、指示として機能しない自然言語である
B)そのプロンプトの差分は、本来は指示として機能する自然言語だが、その機能がモデルの処理に内蔵されているため、処理の方向性に結果として変化がない
この引用におけるBのケースです。
話を戻すと、今回の「 "原理" に則って」というプロンプトは、「ネームドエンティティ認識 (NER)」と「リレーショナルエンティティ抽出モデル」のどちらもGPTには内蔵されていない(だろう)と判断して、指示しています。
つまり、内蔵されていないがGPTが理解しているプログラムについては、「 "原理" に則って」というプロンプトで指示している意図です。このプロンプトの効果は、繰り返しですが、1と2のみを変えて検証した17/20→20/20への上昇要因だと結論づけています。
ちなみに、上記のようなモデルは特化したモデルが別で存在するので、更なる精度を求める場合は、その用途に合わせてGPTではないモデルを選定する必要があるかもしれません。
「属する一文全体の文脈」と「前後関係の文脈」の意味
自然言語処理において、文脈をより精度高く理解するためには、
・その単語(エンティティ)の直前後
・その単語を含む一文全体
の両方を理解することが望ましいです。
基礎知識編の記事では書けていなかったのですが、これはtransformerモデルの「隠れ状態」や「文脈ベクトル」の概念から個人的に着想しました。気になる方はぜひGPT-4にそのまま聞いてみてください。
着想してプロンプトで試してみたら、この2つの処理をしていた方が出力のプロセスから精度が良くなったので、そのまま採用しました。
マジで万能 "Chain-of-Thought"(CoT)
CoTはかなり有名な汎用的手法です。
GPTをはじめとするLLMは「ああしてこうして、今度はこれを…」といった手順が混み合うようなタスクにおいて「step-by-step」で実行するよう伝えると、出力の精度が上がるというものです。
例えば、数学の難問で「まずはこの値を出してほしい」など、難問を分割して指示すると、元々解けていなかった問題が解けるようになった、と海外の論文で報告されているものです。
話を戻すと、今回の課題でも複数の原理に則ってもらったり、精度を上げるために目的を細分化してタスクをstepに分けたかったので、僕もCoTを採用しました。個人的には、このCoTの影響力は今回のプロンプトでも相当大きい影響力があったなと感じています。
こういった汎用的な構造の設計力も、専門知識とは別のプロンプトエンジニアとしてのスペシャルスキルかなと思います。
ちょっとした工夫
実は今回のプロンプトでは「Groupby」を指示しています。
SQLを書ける人は気づいてると思いますが、重複する出力分があったときに、それを1つにグルーピングして出力させることが目的です。
今回のプロンプトだと、Step1〜3において、文脈の確認をするためにわざわざプロセスを出力させています。この時、各エンティティを含む全体の文章や直前後の文章が、共通している部分もあるのに個別で全て出力させていたので、出力全体が長すぎる、という問題が途中で発生しました。
なので、出力結果をできるだけシンプルで構造的にするためにも、Groupbyで指示した背景です。このGroupbyを思いつくことも、SQLを書ける人間だからこそなので、これもまた一つのプロンプトに活用できる専門知識かなと思います。
ちなみに、Step1〜3のような、途中計算の結果は省略させず、わざわざ出力させた方が最終出力の精度が上がると考えています。
今回100回以上実験した経験から実感していることに加えて、そもそもGPTは前すぎる文脈は忘れてしまうので、「直前にAの情報材料があって今Aを判断する」、Bを判断させたいときはAの判断の次にBの情報材料を与えて直後にB判断、次にCの材料情報を…
が有利です。
こう考えると、先ほどのCoT(step-by-stepで指示するべき)話が有効なのも、同じ話なので納得ができますね。
ということでたくさん書き込みましたが、最後まで読んでいただいた方、貴重なお時間を本当にありがとうございます。
どんどん新しいプロンプトを開発していくので、また読みきにてくれると嬉しいです。長文、お疲れ様でした!
他のSNS発信
この記事が気に入ったらサポートをしてみませんか?