
Rを活用した地域課題解決のためのヒント NDB分析編 #4(特定健診)

特定健診データの可視化(その2)
前回までは主に箱ひげ図による特定健診の都道府県別の平均値の分布を見てみました。ただこれだけではBMIの分布はこうなんだくらいの気づきしか生まれません。何かと何かを比較して違いや関係性を見出し、この違いや関係性は何に起因するのかを深堀して初めて分析をやる意味が見えてきます。地域課題設定のための仮設につなげる切り口の創造がデータ分析に関わる当事者には求められると思います。
検査値の分布を可視化する(箱ひげ図+性別・年齢階層比較)PIVOT解除
前回は男性のみの分布をplotしましたので、男女を比較してみたいと思います。変数として「男_中計_平均」と「女_中計_平均」を使って、箱ひげ図のX軸に並べれば良いのですが、あまりスマートな手法ではありません。例えば、40歳台と50歳台の男女別比較をしたいと思った場合、X軸には4つの変数を取り込む長々としたスクリプトを記載する必要があり汎用性がありません。
そこで使えるテクニックがPIVOT解除です。今回使っているデータフレームの場合、性別と年齢階層を横持ちでクロス集計していますが、ここを解除して性別・年齢階層を新たな変数「性別_年齢階層」として設定し、その変数に対応する各検査値を「検査値」という変数にします。
文字で説明すると分かりにくいので、RStudioで実行してみます。libraryはtidyrのpivot_longer関数を使用します。その名の通り横持ちを縦持ちに一気に変換してくれます。エクセルでもpower queryを使用すれば可能ですが、Rの方が慣れれば楽かと思います。
library(tidyr)
library(dplyr)
#性別・年齢階層の横持ちデータを縦持ちに変換する。
df.pref_kenshin_avg %>%
pivot_longer(
cols = c(-都道府県CD, -都道府県, -検査項目CD, -検査項目),
names_to = "性別_年齢階層",
values_to = "検査値"
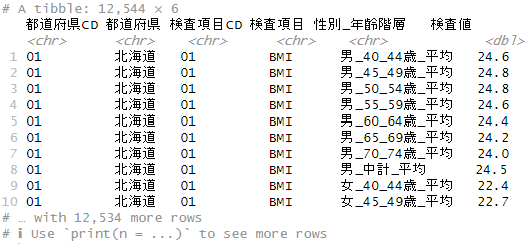
)colsで縦持ちに変換する項目を指定します。この例では、対象が多いので変換しない項目(横持ちのまま残す変数)を除くという処理をしています。names_toとvalues_toで縦持ちにする新たな変数を値を指定します。consoleの出力結果は下記の通りです。
検査値の分布を可視化する(箱ひげ図+性別・年齢階層比較)plot
ここから先は
¥ 250
この記事が気に入ったらサポートをしてみませんか?