
AUTOMATIC1111 WebUIをチューニングしよう!WebUIの高速化を解説!(2023.6.13追記)

はじめに
今回は、AUTOMATIC1111版WebUI(以下WebUI)の高速化にフォーカスを当ててお伝えします。
WebUIは日々更新が続けられています。
最新版ではバグなどがある場合があるので、一概に更新が正義とは限りません。
但し、新しいPythonパッケージに適用するように更新されていることが多く、その恩恵を受けるためにも正しくチューニングしましょう!
今回は、とても技術的な要素が多く出てきます。
コーヒーでも飲みながらゆっくり読んでみてください。
[2023/6/13追記]
本記事はA1111WebUI v1.2.0以前の情報となります。
v1.3.0以降では、最適化項目が拡張されていますので、本記事の内容は現在の情報よりも古いものになります。
準備はいいですか?
Python環境及びWebUIのアップデート方法
これはお決まりですね。
恐らく、ローカル環境やクラウドに環境構築している方なら、ご存じの方が多いと思いますが、念の為ご紹介します。
WebUIのPython仮想環境をアクティベートする
WebUIをインストールし起動すると、必ずPythonの仮想環境(venv)が構築されます。
まずは、venvをアクティベートしましょう。
> .\stable-diffusion-webui\venv\Scripts\activatevenvを作成・アクティベートすることで、ホスト環境と切り離された環境として構築することができます。
pipのアップグレードを実施する
pipとはPythonパッケージをリポジトリより入手するコマンドです。
pipのアップグレードを行いましょう。
(venv)> python -m pip install --upgrade pipRequirement already satisfied: pip in d:\python\.venv\stable-diffusion-webui\venv\lib\site-packages (22.3.1)
Collecting pip
Using cached pip-23.1.2-py3-none-any.whl (2.1 MB)
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 22.3.1
Uninstalling pip-22.3.1:
Successfully uninstalled pip-22.3.1
Successfully installed pip-23.1.2pipのバージョンがアップグレードされました。
WebUIをアップデートする
WebUIをGithubよりPullします。
その際、WebUIが置いてあるカレントフォルダへ階層変更しておいてください。
(venv)>git pullremote: Enumerating objects: 539, done.
remote: Counting objects: 100% (484/484), done.
remote: Compressing objects: 100% (159/159), done.
Receiving objects: 94% (507/539)used 414 (delta 318), pack-reused 55R
Receiving objects: 100% (539/539), 326.21 KiB | 8.36 MiB/s, done.
Resolving deltas: 100% (351/351), completed with 63 local objects.
From https://github.com/AUTOMATIC1111/stable-diffusion-webui
* [new branch] cfg-rescale -> origin/cfg-rescale
cd8a510c..31545abe dev -> origin/dev
* [new branch] extensions-clone-depth-1 -> origin/extensions-clone-depth-1
* [new branch] startup-profile -> origin/startup-profile
* [new branch] ui-selection-for-cross-attention-optimization -> origin/ui-selection-for-cross-attention-optimization
Already up to date.今回の実行では、そこまで大きな変更はなかったようです。
大きな差分があるときは、ファイルもしくはフォルダ構成が変更になります。
WebUIの更新は以上になります。
続いて、WebUIに関わるPythonのパッケージを更新しましょう。
Pythonパッケージの更新
方法としては2通りあります。
WebUI起動引数によるアップデートする(推奨)
pipコマンドでパッケージをアップデートインストールする
一応どちらも説明しますが、WebUI起動引数によるアップデートを推奨します。
理由としては、WebUIの必要パッケージは指定されることがありますが、pipコマンドを引数をつけずに実行すると、最新版が導入されてしまいます。
WebUIの推奨バージョンではないものがインストールされてしまう可能性を考えると、WebUIで指定されてるパッケージを自動でインストールされるほうが安全である為です。
[!! 注意 !!]
現在(2023.5.21現在)、最新版のWebUIはpytorch2.xを利用しています。
pytorch2.xに対応したxformersはリリースされていない関係上、xformersはインストールする必要がありません。
インストールしても恐らく問題ありませんが、動作環境外であることを留意してください。
[2023/06/13追記]
pytorch 2.xに対応したxformers 0.0.20以降がリリースされました。
引数 [--xformers]がA1111WebUI v1.2.0以降でも使用できるようになっています。
WebUI起動引数によるアップデートする(推奨)
まずは、WebUIの起動引数によるアップデートを紹介します。
起動ファイルを、まずはメモ帳などで開きましょう。
.\stable-diffusion-webui\webui-user.bat開いたら、下記の行に引数を追加しましょう。
set COMMANDLINE_ARGS=--reinstall-pytorchpytorchを再インストールする引数です。
内容を保存して、バッチファイルを実行しましょう。
実行が終わったら、バッチを終了させて、再度メモ帳で起動ファイルを開いてください。
追加した引数を消してください。
set COMMANDLINE_ARGS=保存して更新作業は完了です。
pipコマンドでパッケージをアップデートインストールする
pipコマンドでパッケージをアップデートする方法を紹介します。
pytorchの公式サイトへ行きましょう。
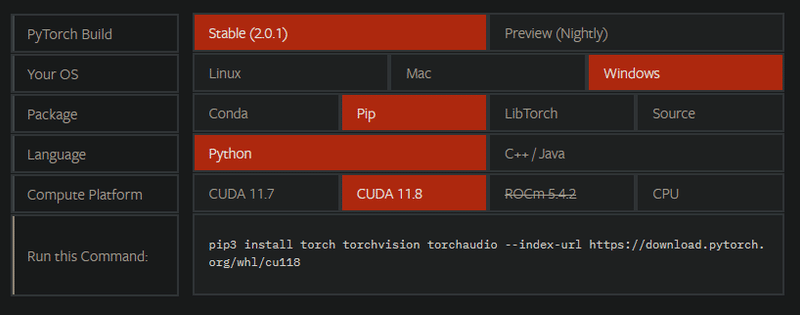
使用CUDAを選択すると、コマンドが表示されます。
pythonバージョンにもよるのですが、Windows版Pythonで現在使用しているバージョンではpip3ではなくpipであることに留意しましょう。
CUDA 11.8の場合
(venv)>pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118CUDA 11.7の場合
(venv)>pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118以上で完了です。
WebUIの高速化
一番の高速化はハードウェアを更新すること!
なのですが、決してPCパーツは安価ではありません。
WebUIを高速化すると言っても、限度はありますのでご承知ください。
高速化するには、以下の方法が有効と思われます。
WebUI起動引数による動作指定を行う方法
Garbage collection thresholdの設定(メモリ領域開放の閾値)
CUDA Memory Allocatorの分割サイズの設定
WebUI内のVRAM・RAMの設定
演算処理方法の変更
1つずつご紹介していきたいと思います。
1.WebUI起動引数による動作指定
まずは、WebUIのGithubのArguments関係を見てみましょう。

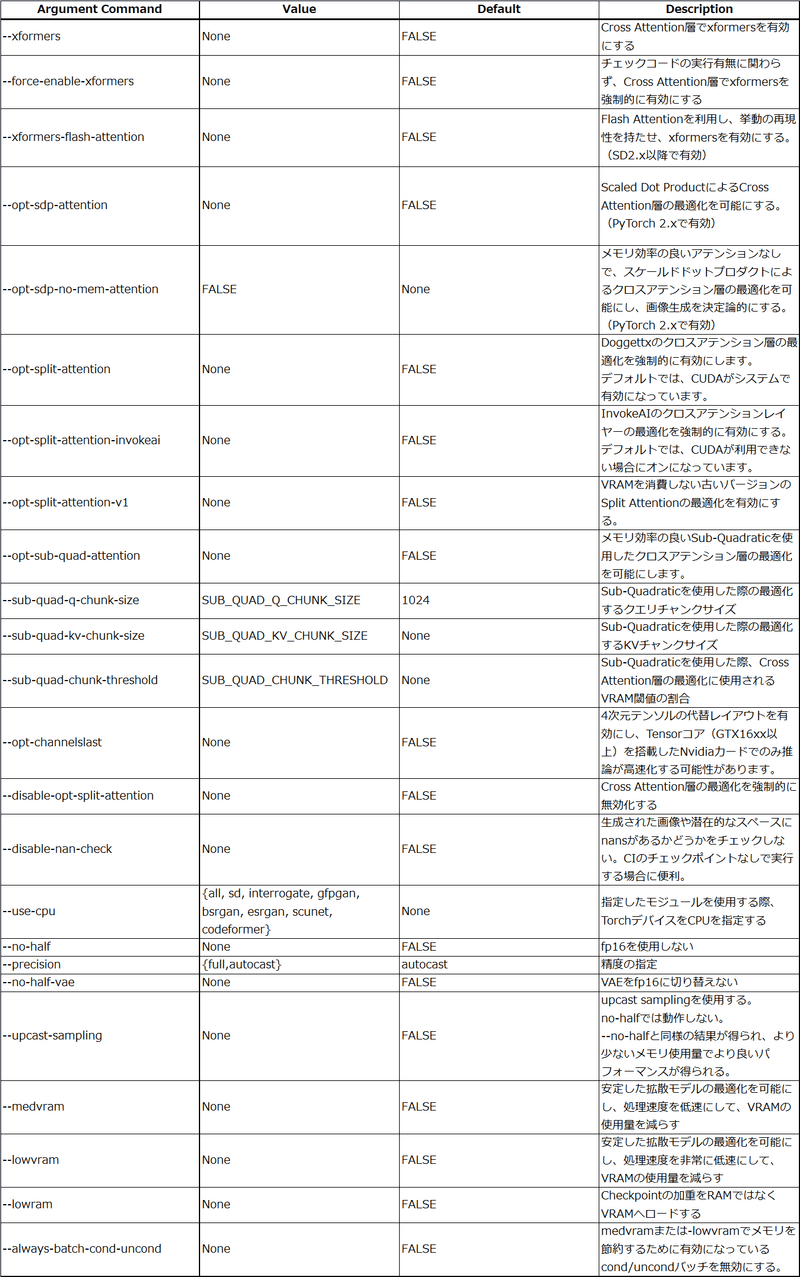
上記は、パフォーマンスに係るWebUIの起動引数です。
色々と難しい単語が並んでいるので、抜粋して解説します。
Cross Attention Layers
Cross Attention Layersとは、自然言語処理(NLP)のタスクにおいて、異なる情報源間の相互作用や関連性をモデルに学習させるための注意メカニズムの一つです。
2つの異なる情報源(例えば、文章Aと文章B)を持ちます。まず、文章Aの各要素に対して、文章Bの要素との関連性を計算するための重みが割り当てられます。これにより、文章A内の各要素は、文章Bの情報に基づいて重要度が決定されます。
次に、文章Aの各要素に対して計算された重みを使用して、文章Bの情報を重み付きで統合します。
これにより、文章Aは文章Bの情報を考慮しながら処理され、両者の相互作用がモデルに反映されます。
Flash Attention
Flash Attentionは、自然言語処理(NLP)のタスクにおける注意メカニズムの一つです。
注意メカニズムは、モデルが重要な情報に集中し、その情報を適切に処理するための手法です。
また、自然言語処理タスクにおいて、特に文脈や長距離の依存関係を考慮する必要がある場合に有効です。
Flash Attentionを使用することで、モデルは異なる視点や情報の特徴をより繊細にキャプチャでき、タスクの性能を向上させることが期待されます。
出典元:Github - HazyResearch /flash-attention
Scaled Dot Product
Scaled Dot Productは、注意機構の一部として使用される計算手法です。主にTransformerモデルや自己注意(self-attention)メカニズムにおいて利用されます。
Scaled Dot Productは、二つのベクトル(通常はクエリ(query)ベクトルとキー(key)ベクトル)の内積を計算し、その結果にスケーリングを適用することで、注意の重みを計算します。
Split Attention
Split Attentionは、自然言語処理(NLP)の注意機構の一種です。
Split Attentionは、Transformerモデルのマルチヘッドアテンション(multi-head attention)の一部として使用されます。
通常のマルチヘッドアテンションでは異なるヘッドが異なる情報に注目し、その情報を処理します。
一方、Split Attentionは、各ヘッドが入力の異なる部分に対して注意を分割することが特徴です。
Doggettx's cross-attention layer optimization
Doggettx氏が提案しているクロスアテンション層でのアルゴリズムを指します。
デフォルトではCUDAによるアルゴリズムが有効になっています。
https://github.com/Doggettx/stable-diffusion
InvokeAI
InvokeAIが提案しているクロスアテンション層でのアルゴリズムを指します。
デフォルトではCUDAが利用できない環境でのみ有効になります。
https://github.com/invoke-ai/InvokeAI
Sub-Quadratic
大規模なデータセットや計算負荷の高いタスクにおいて特に有用です。
高速な計算を実現することで、アルゴリズムや計算手法の効率性を向上させ、リソースの節約や処理時間の短縮が可能になります。
Upcast sampling
fp16で行われる推論を、Cross Attention層の最適化をfp32で実施する等、U-Net処理時にアップキャスティング(Upcast)を行い、float32でサンプリングを実施します。
一部環境では、メモリの使用率を軽減させる効果があります。
では、起動引数を指定して、色々見ていきましょう。
初めに、以下引数のみを指定した場合を試してみます。
set COMMANDLINE_ARGS=--autolaunch--autolaunchは、起動バッチ処理完了時に、WebUI画面を自動起動する引数です。
今回の内容とは関係ないので、詳しい説明は割愛します。
今回は、以下のプロンプトと設定で処理速度を計測します。
Prompt
best quality,masterpiece,absurdres,highres,beautiful eyes,detaild background,
BREAK,
(1 girl, solo:1.5),[close view]Negative Prompt
EasyNegativeV2,[:(negative_hand-neg:1.2):15],(worst quality:1.5),(low quality:1.5),(normal quality:1.5),(monochrome),(grayscale),(watermark),(white letters),((nsfw))Steps: 30
Sampler: DPM++ 2M Karras
CFG scale: 11
Seed: 142408489
Size: 512x512
Batch count: 10
Denoising strength: 0.55
Clip skip: 2
Hires upscale: 2
Hires steps: 13
Hires upscaler: SwinIR_4x
起動時間
Startup time: 11.4s (import torch: 1.7s, import gradio: 1.2s, import ldm: 0.5s, other imports: 0.9s, list SD models: 0.2s, load scripts: 2.5s, create ui: 4.0s, gradio launch: 0.3s).
処理速度
9.44 it/s
続いて、効果がありそうで、機能が競合しなさそうな引数を選定して入れてみましょう。
set COMMANDLINE_ARGS=--autolaunch --opt-sdp-attention --opt-split-attention --opt-channelslast --no-half-vae[2023/06/13追記]
A1111 WebUI v1.2.0以降(pytorch 2.x+xformer 0.0.20以降)でも、--xformersと--opt関係の引数は共存できません。
どちらか一つを割り当ててお使いください。
起動時間
Startup time: 9.8s (import torch: 1.6s, import gradio: 1.2s, import ldm: 0.5s, other imports: 0.8s, list SD models: 0.1s, load scripts: 1.8s, create ui: 3.5s, gradio launch: 0.3s).
処理速度
13.85 it/s
起動時間 11.4秒 → 9.8秒 (1.6秒短縮)
処理速度 9.44 it/s → 13.85 it/s(4.41 it/s上昇)
かなり早くなりましたね!
2.メモリに関する設定
ここでは、
Garbage collection thresholdの設定(メモリ領域開放の閾値)
CUDA Memory Allocatorの分割サイズの設定
を設定します。
ひとまず、上記の用語をご説明します。
Garbage Collection
ガベージコレクション[注釈 1](英: garbage collection、GC)とは、コンピュータプログラムが動的に確保したメモリ領域のうち、不要になった領域を自動的に解放する機能である。
Memory Allocator
動的メモリ確保(どうてきメモリかくほ、英: dynamic memory allocation)は、メモリ管理手法のひとつであり、プログラムを実行しながら、随時必要なメモリ領域の確保と解放を行なう仕組みである。動的メモリアロケーション、動的メモリ割り当てとも。
メモリの利用状況は、自身の実行状況や他のプログラムの実行状況に応じて常に変動するため、それらの動作に支障をきたさないよう必要なメモリ領域を適切なアドレスに対して臨機応変に確保・解放を行なう必要がある。
高速化というよりも、メモリ不足やメモリリークに関わるところが大きいです。
ハイエンドGPUでもない限り、VRAMは限られているので、設定しておくことが大事です。
ここでは、私の設定を記載しておきます。
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.8, max_split_size_mb:128,念の為、設定があるとないとでは、どの程度違うのか見てみましょう。
[設定なし]
起動時間
Startup time: 10.5s (import torch: 1.6s, import gradio: 1.2s, import ldm: 0.5s, other imports: 0.8s, list SD models: 0.1s, load scripts: 1.7s, create ui: 4.2s, gradio launch: 0.3s).
処理速度
14.74 it/s
[設定あり]
起動時間
Startup time: 10.9s (import torch: 2.1s, import gradio: 1.2s, import ldm: 0.5s, other imports: 0.8s, list SD models: 0.1s, load scripts: 1.7s, create ui: 4.1s, gradio launch: 0.3s).
処理速度
13.81 it/s
起動時間 10.5秒 → 10.9秒 (0.4秒増加)
処理速度 14.74 it/s → 13.85 it/s(0.89 it/減少)
これは想定していましたが、ガベージコレクションとアロケータを設定すると、メモリ解放・確保という動きをする以上、処理速度が若干下がってしまいます。
ただ、VRAM不足・メモリリークを防止する観点からいうと、設定はしておきたいですが、しっかり見極める必要がありそうです。
起動時間については、誤差と思われます。
3.WebUI内のVRAM・RAMの設定
WebUI内にもVRAMとRAMの設定があります。


検証は、以下で行います。
生成中のVRAM使用率の取得間隔:0 or 40
RAMにキャッシュするcheckpointの個数:1
RAMにキャッシュするVAEの個数:1
[デフォルト設定]
起動時間
Startup time: 10.3s (import torch: 1.7s, import gradio: 1.2s, import ldm: 0.5s, other imports: 0.9s, list SD models: 0.1s, load scripts: 1.8s, create ui: 3.7s, gradio launch: 0.4s).
処理速度
13.39 it/s
[設定あり - VRAM Polling : 0 ]
起動時間
Startup time: 10.4s (import torch: 1.6s, import gradio: 1.1s, import ldm: 0.5s, other imports: 0.8s, list SD models: 0.1s, load scripts: 1.7s, create ui: 4.1s, gradio launch: 0.3s).
処理速度
13.59 it/s
[設定あり - VRAM Polling : 40 ]
起動時間
Startup time: 10.4s (import torch: 1.6s, import gradio: 1.1s, import ldm: 0.5s, other imports: 0.8s, list SD models: 0.1s, load scripts: 1.7s, create ui: 4.1s, gradio launch: 0.3s).
処理速度
8.22 it/s
これについては、あまり効果が確認できませんが、VRAM Pollingを多くすると処理速度が低下しました。
VRAM Pollingを一切行わなければ、処理速度は上昇し、間隔の値を大きくすると処理速度が低下するという結果になりました。
4.演算処理方法の変更
拡散モデルを演算する際、現在はfp16かfp32で行われることが最もポピュラーです。
今回は、テンソル演算を利用した「tf32」を利用してみるとどうなるか検証してみます。
テンソル演算を利用するためには、以下ファイルに構文を追加する必要があります。
対象ファイル
.\stable-diffusion-webui\modules\sd_hijack.py追加する構文
torch.backends.cuda.matmul.allow_tf32 = True追加する位置はimport torch配下であれば、どこでも問題ありません。
上部あたりに追加してみましょう。
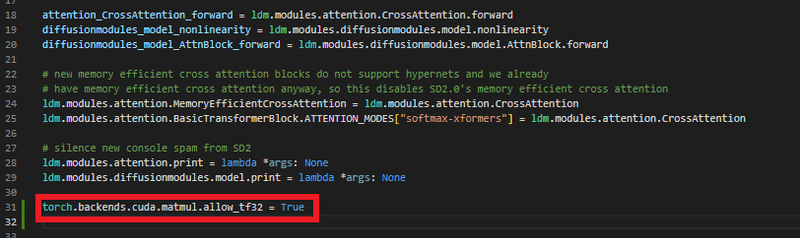
では、検証してみましょう。
[設定なし]
起動時間
Startup time: 10.4s (import torch: 1.6s, import gradio: 1.1s, import ldm: 0.5s, other imports: 0.8s, list SD models: 0.1s, load scripts: 1.7s, create ui: 4.1s, gradio launch: 0.3s).
処理速度
13.59 it/s
[設定あり]
起動時間
Startup time: 10.6s (import torch: 1.7s, import gradio: 1.2s, import ldm: 0.5s, other imports: 0.9s, list SD models: 0.1s, load scripts: 1.8s, create ui: 4.0s, gradio launch: 0.3s).
処理速度
13.92 it/s
起動時間 10.4秒 → 10.6秒 (0.2秒増加)
処理速度 13.59 it/s → 13.92 it/s(0.33 it/上昇)
微増ながらも処理速度が向上してます。
このくらいであれば、もしかすると誤差かもしれません。
但し、私の環境では、安定的に13.00~13.92 it/sが出て処理されていたので、効果はあるのかもしれません。
まとめ
では、各項で行った結果をおさらいしましょう。
1.WebUI起動引数による動作指定
set COMMANDLINE_ARGS=--autolaunch --opt-sdp-attention --opt-split-attention --opt-channelslast --no-half-vae2.メモリに関する設定
高速処理を求める場合は、PYTORCH_CUDA_ALLOC_CONFを設定しない。
安定処理を求める場合は、PYTORCH_CUDA_ALLOC_CONFを設定する。
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.8, max_split_size_mb:128,3.WebUI内のVRAM・RAMの設定
生成中のVRAM使用率の取得間隔:0
RAMにキャッシュするcheckpointの個数:1
RAMにキャッシュするVAEの個数:1
4.演算処理方法の変更
対象ファイル
.\stable-diffusion-webui\modules\sd_hijack.py追加する構文
torch.backends.cuda.matmul.allow_tf32 = Trueおまけ
これまでの内容で、最も処理速度が出るであろう設定にして試してみましょう。
(項目1,3,4を設定し、2.メモリに関する設定のみ無効化)
起動時間
Startup time: 9.9s (import torch: 1.6s, import gradio: 1.2s, import ldm: 0.5s, other imports: 0.8s, list SD models: 0.1s, load scripts: 1.8s, create ui: 3.5s, gradio launch: 0.3s).
処理速度
14.93 it/s
驚異のMAX 14.93 it/sに到達しました。
平均処理速度は14.75 it/sという結果になりました。
おわりに
今回は、WebUIの高速化についてお伝えしました。
極論、マシンパワーを上げれば速度はもっと上がりますが、処理の仕方・仕組みをチューニングすることで、ある程度は処理速度の向上がみられることが分かりました。
ここで記した内容は、あくまでも私の動作環境で実施した内容なので、各々の環境に合わせてチューニングする必要があります。
是非、皆さんもWebUIの高速化をしてみてはいかがですか?
よろしければサポートお願いします!✨ 頂いたサポート費用は活動費(電気代や設備費用)に使わさせて頂きます!✨