
Stable Diffusion 3について学ぶ

はじめに
今回は、Stability AI社がリリースしたStable Diffusion 3について学んでいこうと思います。
SD1.x、SD2.x、SDXLとアーキテクチャはどのように異なるのか、どのようなアプローチで実現しているのか、ライセンスはどうなのかなどを、この記事で説明していきます。
これまでのStable Diffusionについては、以下記事を参考にどうぞ。
従来のStable Diffusion
従来のStable DiffusionはCLIP、Transformer、U-Netを主体としています。

各層を経由しAttention層でqkvを与えて、ユーザはConditioningを行います。

これらの条件で、画像の推論を行い、ノイズ除去プロセスを経て結果を出力していました。
では、Stable Diffusion 3でどのように変わったのでしょうか。
Stable Diffusion 3のアーキテクチャ
これまでの画像生成AIは、モダリティ(様相性)を重要視してきました。
様々な生成AIにおいても、ユーザの意図を汲み取って、どこまで忠実に再現できるのか、推論できるのかという一種の言語体系への理解が、生成AI全般における課題となっています。
そこで、このモダリティを複数処理できるように考案されたのが、Stable Diffusion 3のアーキテクチャとなる「MMDiT(Multimodal Diffusion Transformer)」です。
MMDiTは、画像表現と言語表現にそれぞれ異なるWeightを使用することで、テキストへの理解や言語の綴り(スペリング)に対しての理解が向上しています。

上図を見るとU-Netを使用していないのが分かります。
このことから、これまでのStable Diffusionとは処理プロセスが全く違うものであることになります。
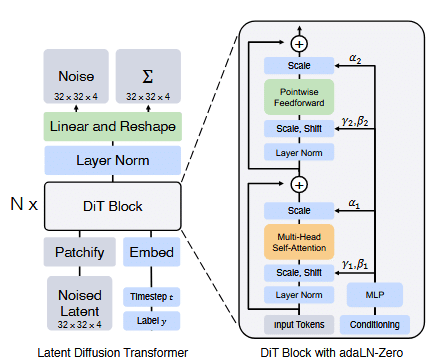
MMDiTはDiT(Diffusion Transformer)アーキテクチャを参考に構築されています。
DiTとは、翻訳すると拡散トランスフォーマと呼ばれ、従来のCNNベースであるU-NetからTransformerベースのアーキテクチャに置き換えることで、性能の向上を実現させています。
DiTはViT構造を模したアーキテクチャで、一部プロセス構成を変更して実現しています。
Stable Diffusion 3のパフォーマンス
前項で紹介した通り、Stable Diffusion 3より新アーキテクチャとなり、テキスト・スペリングへの理解が向上しております。
上記に伴い、
Typography(文章・文字列の視認性)
Visual Aesthetics(視覚的な審美性)
Prompt Following(プロンプトへの追従性)
も大幅に向上しています。

さらに学習においては、Lossも低減しており、CLIP Score(テキストへの適合性)も向上していることがわかります。

Stable Diffusion 3のライセンス
Stable Diffusion 3より新しいライセンスが適用されています。
Stability Non-Commercial Research Community License
その名の通り、非営利ライセンスで研究者や個人開発者向けに提供しているフリーライセンスになります。
条項を確認すると、
You may not use the Software Products or Derivative Works to enable third parties to use the Software Products or Derivative Works as part of your hosted service or via your APIs
ここでいう「Derivative Works(派生作品/二次的著作物)」についても、記載があります。
Derivative Work(s)” means (a) any derivative work of the Software Products as recognized by U.S. copyright laws and (b) any modifications to a Model, and any other model created which is based on or derived from the Model or the Model’s output. For clarity, Derivative Works do not include the output of any Model.
以上から、Stable Diffusion 3の事前学習モデルを使用したマージモデルや追加学習モデルは確実に対象となり、モデルの出力については「For clarity, Derivative Works do not include the output of any Model.」と書かれているので、モデルから出力した物(画像などの生成物)は対象外であると思われます。
また生成物については、次項におけるCreator LicenseとEnterprise Licenseで、生成物への評価を言及しており、恐らく本ライセンスでは生成物を利用した二次的著作物(追加学習モデル)は対象になる、と想定されます。
その為、Stable Diffusion 3の派生モデルは本ライセンスにおいては、一律非営利である必要があると思われます。
Stability AI Creator License / Stability AI Enterprise License
こちらは、有償ライセンスになります。
現状、Stable Diffusion 3事前学習モデルもしくはその派生モデルの作成、生成APIを使用したサードパーティ製の商用サイトなどはこちらのライセンスに同意する必要があります。
Stable Diffusion 3の出力例
Stable Diffusion 3 Mediumモデルは、Stability AI社より一部提供されています。
現状、ComfyUIで利用可能です。
Hugging Face Spaceでも利用可能なので、試しに出力してみます。
では、試しに生成してみます。


こう見ると、本当にタイポグラフィが向上してますね。
完全に文字が読めて、スペリングも正確です。
おわりに
Stable Diffusion 3モデルは、現状の性能評価上で、最先端の画像生成AI技術と同等以上のスコアを叩き出しています。

メモリ消費率、タイポグラフィ、視覚的審美性、プロンプトの追従性など様々な性能でも、一線を画しているのが分かりました。
今後、DiTベースによるアーキテクチャは、次の主流となるのではないかと私的には思っています。
是非皆さんも一度触れてみてください!
文字がはっきり描写されるので、なんだかうれしい気持ちになります。
参考文献・引用元
※1/※5 : Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (Patrick Esser, 5 Mar 2024)
※2 : Scalable Diffusion Models with Transformers (William Peebles, 2 Mar 2023)
※3/※4 : Stable Diffusion 3: Research Paper (5 Mar 2024)
この記事が参加している募集
よろしければサポートお願いします!✨ 頂いたサポート費用は活動費(電気代や設備費用)に使わさせて頂きます!✨