
【2020年版】Pose Trackingの研究動向と実活用の考察

0. はじめに(ビジネスの方向け)
Pose Trackingとは、動画において人物の動きを追跡するタスクのことです。
例えば、
- スポーツにおけるポジショニング・動きの分析
- 工場内での動作解析(異常検知やサイクル検出)
- 店舗内の動線解析・セキュリティ
など、Pose Trackingを活用した様々なアプリケーションが想定されます。
機械の眼ともいわれるDeep Learningの発展によって、「画像」における物体・人物検出の精度は飛躍的に向上しましたが、動きを伴う作業の解析(スポーツ解析、作業者の動作解析、警備、顧客分析、、、etc)においては、「動画」において、同一のモノ・ヒトであることを理解する必要があるため、Pose Tracking技術が重要となります。

引用: Guanghan/lighttrack@GitHub
【Pose Trackingを事業に活用したい方はこちら↓】
この記事では、Pose Trackingに関するSOTAとされる論文([Ning+ 19.05] LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking など)をベースに、研究動向と実活用のとまとめ考察を行い、
1. Object Trackingを含めたTrackingの研究の潮流を理解する
2. Top-Down/Bottom-Up アプローチのSOTAの研究と実活用の潮流を理解する
3. Trackingにおける現状課題を理解する
ことを目的とします。
1. Object Trackingを含めたTrackingの研究の潮流を理解する
動画内でトラッキングするという枠組みにおいて、モノをトラッキングするObject Trackingというタスクがあります。より厳密に定義すれば、「動画像において初期フレームの物体の位置が与えられ、次フレーム以降の同一物体の位置を検出するタスク」となります。
Object Trackingについては、詳細はまた別途まとめたいと思いますが、ここでは、[Ciaparrone+ 19.11]DEEP LEARNING IN VIDEO MULTI-OBJECT TRACKING: A SURVEYを踏まえて簡単に整理します。
Object Trackingには、
1. Single(一つの物体をトラッキングするタスク) vs Multiple(複数の物体をトラッキングするタスク)
2. Online(過去データのみを用いて推論する) vs Offline(Batchとも言う、未来のデータも利用して推論する)
という大きく2つのタスク分類があり、これらの概念構造はPose Trackingと共通です。
Single Object Tracking(SOT)と、Multiple Object Tracking(MOT)は、似て非なるタスクであることに注意が必要です。MOTは目標物体が既知でなく、オクルージョンやインテラクションの問題が発生するタスクであるため、単にSOTのモデルを複数に適用すると、ID(identification)がごちゃごちゃになってしまいます。
また、OnlineかOfflineかによって、KPIも変わってきます。Onlineであれば、精度もさることながら実運用時における速度がより追求されますし、一方で、Offlineであれば、未来を含めて一連の動画において処理を行うため、より精度が追求されます。あとから振り返るタスクであればOfflineの方が適切ですが、実際の現場レベルの話では、 大量の(長時間の)データを振り返る必要がある場合も多く、あとから振り返るタスクであっても速度が求められることがよくあります。
そして、Object Trackingの構造としては、以下の4ステージをとることが主流のようです。(end-to-endのモデルもいくつか提案されています)

引用: [Ciaparrone+ 19.11]DEEP LEARNING IN VIDEO MULTI-OBJECT TRACKING: A SURVEY
1. Detection Stage: Object Detection(SSD, YOLOなどで物体検出)
2. Feature Extraction / Motion Prediction Stage(CNN/Siam CNNで特徴量抽出)
3. Affinity Stage(距離計算)
4. Association Stage(IDの割り振り)
Object Trackingは、ヒトに対しても適用可能であることから、Object Trackingはヒトを追跡するPose Trackingのタスクを内包すると考えることができます。
1. Object Trackingを含めたTrackingの研究の潮流を理解する
に関して、「Pose Trackingは、よりヒトの動きや姿勢を活用したアプローチを取るObject Trackingであり、Multi Object(Pose) TrackingでかつOnlineのタスクが主流である」と言えるでしょう。
2. Top-Down/Bottom-Up アプローチのSOTAの研究と実活用の潮流を理解する
Pose Trackingにおいて、CVPR2019やそれ以降の論文を中心にサーベイすると、
- [Ning+ 19.05] LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking => Top-Downのアプローチ
- [Raaj+ CVPR2019] Efficient Online Multi-Person 2D Pose Tracking with Recurrent SpatioTemporal Affinity Fields => Bottom-Upのアプローチ
あたりが有力なアルゴリズムのようです。
なお、LightTrackの詳しいアルゴリズムや実験の輪読資料は以下の通りです。
[Ning+ 19.05] LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking の性能は以下の通りです。(論文から転載)
なお、LightTrackのonlineでのfpsは、trackingの処理に要する時間であって、姿勢推定などの時間は含まれていないことに注意。

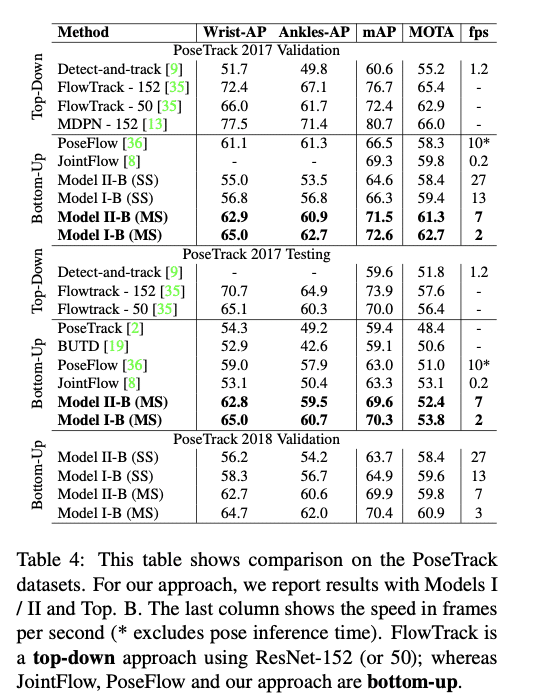
[Raaj+ CVPR2019] Efficient Online Multi-Person 2D Pose Tracking with Recurrent SpatioTemporal Affinity Fields の性能は以下の通りです。(論文から転載)
ここで、両者ともOnlineのタスクであるので、2つの大きな違いはBottom-UpかTop-Downのアプローチのどちらを用いているかということでしょう。それぞれの特徴を整理すると以下のようになります。
# Bottom-up
- 画像内における関節点を推定した後、人を再構成する
- 複数人の推定において、計算時間が人数に比例しない(つまり早い)
- OpenPoseなど
# Top-Down
- 人をObject Detectionアルゴリズムで検知した後に、single person Pose Estimation(SPPE)を行う
- タスクが分解できて、シンプル
- RMPE、AlphaPoseなど
[Raaj+ CVPR2019] Efficient Online Multi-Person 2D Pose Tracking with Recurrent SpatioTemporal Affinity Fields の方が精度はより優れていることがわかります。推論速度は基準が異なっているため単純な比較はできないですが、LightTrackはTrackingにかかわる処理速度がPoseFlowの5倍と今までになく速く、PoseEstimationの速度に対して無視できるほど速いので、速度ではLightTrackに軍配が上がると見て良いでしょう。
ここで、実用により重きをおくのであれば、Top-Down型のTrackingアルゴリズムはそのシンプルさゆえに拡張性と互換性に優れているメリットは大きいです。
個々のアルゴリズムを組み合わせて実現できるTop-Down型のTrackingシステムであれば、例えばより精度・速度ですぐれているPose Estimationのアルゴリズム(例えばCheng+ 19.08]Bottom-up Higher-Resolution Networks for Multi-Person Pose Estimation、通称Higher HRNet)を用いることで、その性能を簡単にupdateすることができます。
また、上述したObject Trackingと並行して用いるなど、end-to-endのBottom-up型の設計よりも、アプリケーション設計する際に要素要素で切り離せるTop-Down型のアプローチのほうが組み込みやすいというメリットがあります。
個人的な意見ではありますが、end-to-endであることはDeep Learningの強みでもありますが、なんでもかんでもend-to-endでアルゴリズム設計してしまうと、互換性や拡張性が担保しづらいという実用面でのデメリットが発生してしまうと考えています。タスクをメタ認知して解決できる汎用AIのようなものがでてくるまでは、きちんと人間がタスクをメタ認知し、Deep Learningが得意な領域までタスクを因数分解する方がスケールすると思います。
故に、
2. Top-Down/Bottom-Up アプローチのSOTAの研究と実活用の潮流を理解する
に関して、「Top-Downのアプローチのほうが実用においてスケールする」と言えるでしょう。
3. Pose Trackingにおける現状課題を理解する
Pose Trackingにおいて、LightTrackではヒトの姿勢の一貫性を確認するre-identificationのシステムを組み込むことで、特にセンサ(カメラ)の移動やズームにロバストであることを可能にしているが、複数のセンサの対応付けや、トラッキングは、別のタスク・研究要素であり、難易度は高いといえます。
また、センサの死角に入って一定時間が立ってしまう場合(姿勢の一貫性によりTrackingできない場合)は、服装や顔といった視覚的な特徴から人物同定を行う必要があり、例えば店舗での顧客の追跡などは、複数のアルゴリズムを組み合わせたアプリケーション側の設計も必要になるでしょう。

引用: [Ning+ 19.05] LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking カメラの移動やズームが発生すると、位置情報だけのトラッキングではうまく行かない。
3. Trackingにおける現状課題を理解する
に関して、
1. 複数視点でのトラッキング
2. 長期的に死角にはいってしまうこと
が課題として言えそうです。
4. 最後に
私が代表をしております株式会社ACESでは、Deep Learningを用いた画像認識技術を中心に、リアル産業でのDXプロジェクトやアルゴリズムライセンス事業を行っています。特に、ヒトの認識・解析に強みを持って研究開発を行っておりますので、ご興味のある方は、ぜひお問い合わせください!
【会社紹介↓】
【一緒に働いていただける方・まずは話を聞いてみたい方はこちら↓】
この記事が気に入ったらサポートをしてみませんか?