【Python初心者】Kaggle : Amazonレビューを使った感情分析

自己紹介
機械設計業務を8年間経験→IT業界への転職を目指し、Aidemy premiumを受講中(3ヶ月間)
使用環境
Macbook Air (M1)
Google Colaboratory Pro
Python学習歴
初心者(Aidemy PremiumにてAIアプリ開発・データ分析講座を3ヶ月間受講)
目的
Amazonのレビューに記載されているテキストと、「評価スコア」Negative(低評価)とPositive(高評価)の相関性について検証する。
実践にあたって
Google Colaboratory上で全て実践した。
※ 極力各コードで不要になった変数等は消去しているが、それでもRAM容量の上限を超えたのでメモリ拡張の為Google Colaboratory proを使用した。
実践の流れ
データセットの取得(データ収集)
データの中身の確認(データクレンジング)
特徴量の調査(データクレンジング)
モデルの作成〜学習〜性能評価(データを学習、性能をテスト)
1-1. Kaggleの「Amazon Reviews for Sentiment Analysis」にあるDownloadから分析に使用するTrain_dataとTest_dataをダウンロード
1-2. Google Driveにデータをアップロードし、データを読み込む

2.データの中身を確認
結果

Kaggle上の説明にも書いてある通り、"_ _label_ _1"が星1〜2のレビュー評価、"_ _label_ _2"が星4〜5のレビュー評価のデータとなっている。※星3のレビューは今回のデータには入っていない。
3-1.データをラベルとテキストに分割

結果

trainデータ:3,600,000
testデータ:400,000
データが存在していることが確認できた。テキストデータ、ラベルデータともに正常に抽出できていることから、欠損値は無いと考えられる。
3-2. テキストデータのノイズ軽減
評価スコアに影響のない単語を減らす為、"stopwords"だけでなく"!"や"?"などの記号も消去対象としている。
(後で単語の数をカウントする為に、単語のみでリスト化されたデータも用意しておく。)

3-3. 評価ラベル、単語数、ノイズ削減したテキストをデータフレーム化して可視化した。

3-4.抽出した単語数をラベル別(Negative/Positive)に分ける

結果

・Positive評価の方が比較的単語数が少ない(文章が短い)が優位差はあるとは言えない。
考察:レビューにおいて、NegativeとPositiveどちらにおいても各自の評価とその理由付けという構成は大きく変わらないと考えられる。
3-5.どのような単語が頻繁に出現しているか確認する



結果

・上図は、Negative/Positiveそれぞれ上位20位までの単語をグラフ化したものである。
・補足として、単語の出現総量と総量に対する上位20位の単語の占める割合も求めた。
・ノイズ低減した後の単語総数は142,883,146であることが分かった
・上位20位の単語は全体の単語の10.43%を占めている
・Negativeでは"bad"の否定的な単語が入っており、Positiveでは"great","love"などの肯定的な単語が入っていることが確認できた
改善案
ノイズ低減を実施したが、テキストには感情分析に不要であると考えられる単語がまだ多くみられる。不要な単語を抜き出すことで、より精度を上げられる余地がある。
4-1.モデルの作成~学習~性能評価
トレーニング用データセットから訓練用データと検証用データを用意し、RandomForestClassifierで実行。特徴量は頻出単語20個とした。
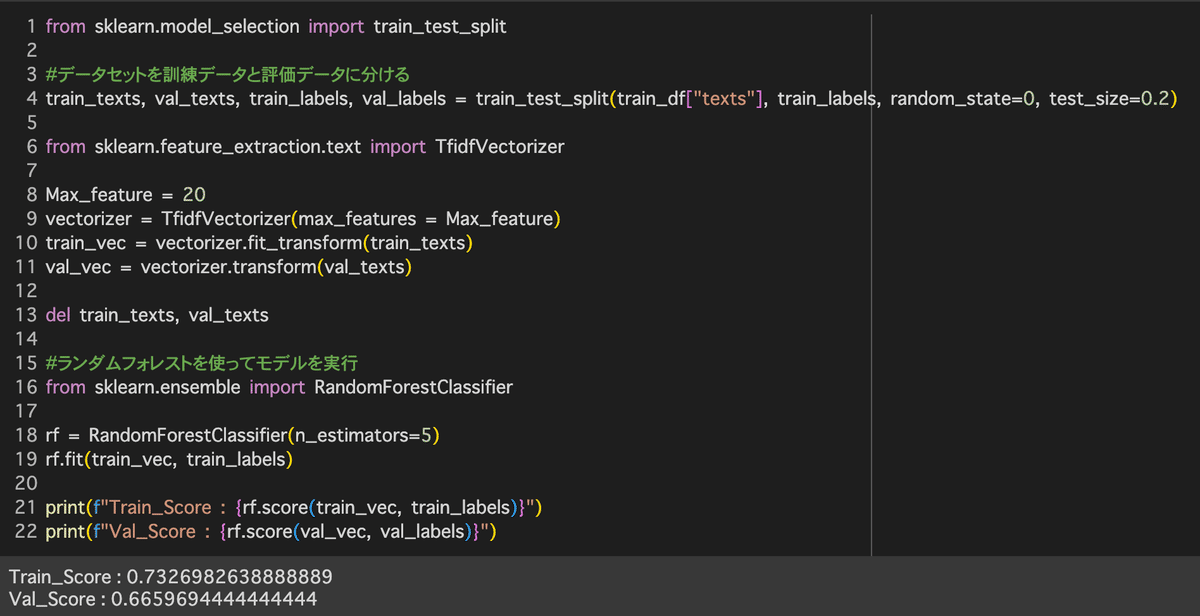
結果
Train_Score = 0.732638888889
Val_Score = 0.665969444444444
というスコア結果になった。
4-2.テストデータの実行

結果
Test_Score = 0.664125
考察
・訓練データより検証データのスコアが低い=過学習している可能性がある
・全体的にスコアが低い=学習データしたデータのノイズが多いことが考えられる。不要な情報を消去し、精度を上げる必要がある。
対策と今後の検証について
・感情に関わらない単語を手動で抜き出す。【6/14実施済】
・単語だけに絞らず、文脈を考慮する(n-gram)
・特徴量の決め方の精度を上げる。(グリッドサーチやランダムサーチを用いる)
・他の分析モデルでも実行し、結果を比較する。(SVM、ロジスティック回帰など)
最後に
今回初めて大量のデータを扱う分析を行なったが、RAMの許容容量を考慮できておらず、コードを実行してしばらく動作した後にRAMがクラッシュしては1からやり直すという作業で詰まってしまった。良かった点としては、そこでどうすれば容量を確保できるか、コードをより簡潔に書けないか、合間に不要な変数を消去できないかと考えながら作業したことで、コードに対する理解が深まったと思う。
今回は容量の関係上1つのモデルでのみの実行となってしまったが、他のモデルだとどのような結果になるか、学習データをどのように加工すればより良くなるかを引き続き試行錯誤していきたいと思う。
※追記
(追記 6/14)
頻出単語Top20の中にあった感情分析に関係の薄い単語を手動で抽出。
stop_2 = ["book", "one", "would", "time", "movie", "even", "read", "buy", "product", "really", " money", "first", "work", "cd", "album", "also", "story" ]
stopwordsと同じ容量でテキストから除去する。

結果

前回
Train_Score = 0.732638888889
Val_Score = 0.665969444444444
Test_Score = 0.664125
今回
Train_Score = 0.708
Val_Score = 0.672
Test_Score = 0.673
スコアに改善あり。
使用するデータの質によって精度に影響していることが分かった。
※6/15追記
TfidfVectorizerではなくCNNを用いた分析を行なった。



さらにテストデータで実行
結果

Test_accuracy Score : 0.9501
Val_accuracy Score : 0.9200
Test_Accuracy Score : 0.9195225
TfidfVectorizerよりもCNNを用いた分析の方が大幅にスコア上昇が見られた。
TfidfVectorizerはテキストデータの特徴量抽出に向いているが、大量データの分析においてはCNNの方が効果的であると分かった。
※LogisticRegressionモデルを使った予測

結果


Test_Accuracy Score : 0.905275…
Val_Accuracy Score : 0.9012875
Test_Accuracy Score : 0.90087
CNNよりやや低いがスコアを出力することができた。
ハイパーパラメータの調整により、もう少しスコアの上昇の見込みがあると考えられる。
この記事が気に入ったらサポートをしてみませんか?