DATA Saber 備忘録 Intermediate1 前編

つい最近tableauを触り始めたIT企業に勤める新入社員です。
今回は、tableau初心者🔰の私がDATA Saberでつまずいた所を抜粋して解説していきます。
Intermediateの前編です!
後編はこちら⤵️
https://note.com/kimatableau/n/n2d8f436e5bed
Q1 フィルターアクションの除外

まず、担当マネージャーとはなんでしょう?
注文のシートでは担当マネージャーはないので、
データソースで、関係者を注文に結合します。
地域の名前で関係者をとってくるという意味になります。
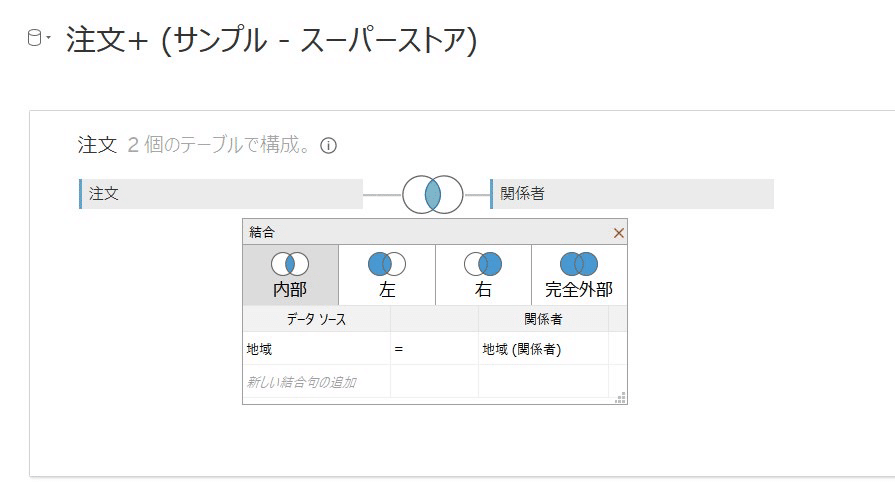
内部→左→右→完全外部
(左からパフォーマンスが良いです)
担当マネージャーが使えるようになったのでシートに移動して、都道府県と地域を地理的役割に当てはめます。
利益を色に当てはめ、緯度を複製します。
1つは地域、もう1つは都道府県(円で表示)
→二重軸にすると地図が重なります!
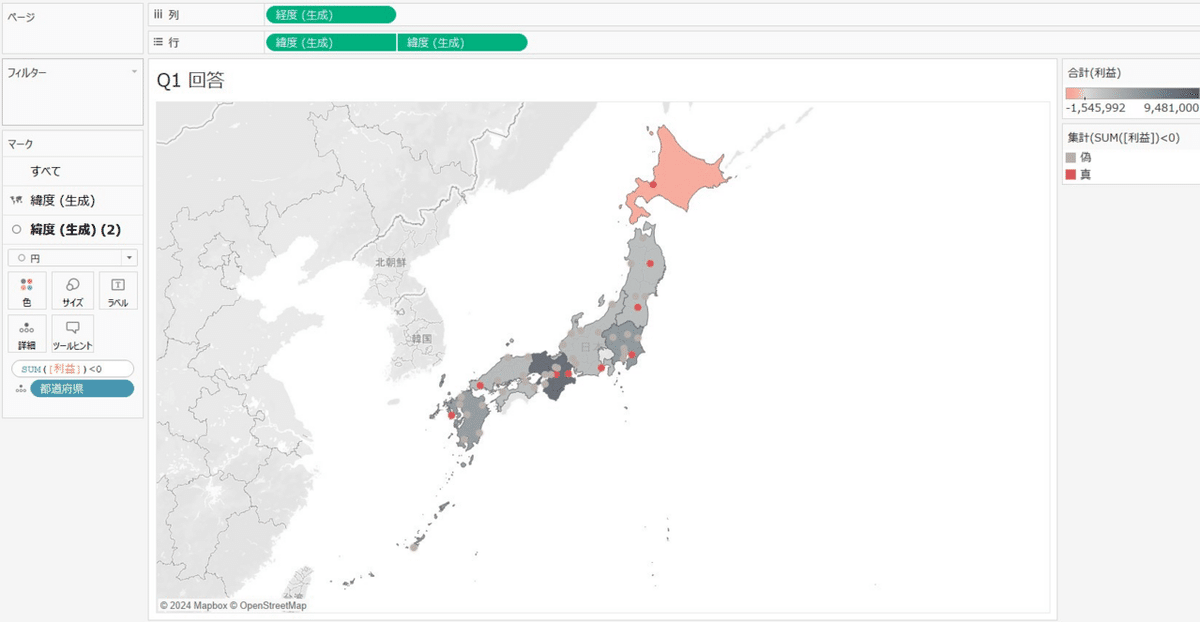
赤字のところをクリックしたら除外されるようにしたいので、
SUM([利益])<0 を作成して赤字を目立たせます。
さらに、サイズや色を変化させて赤字の都道府県を分かりやすくします。
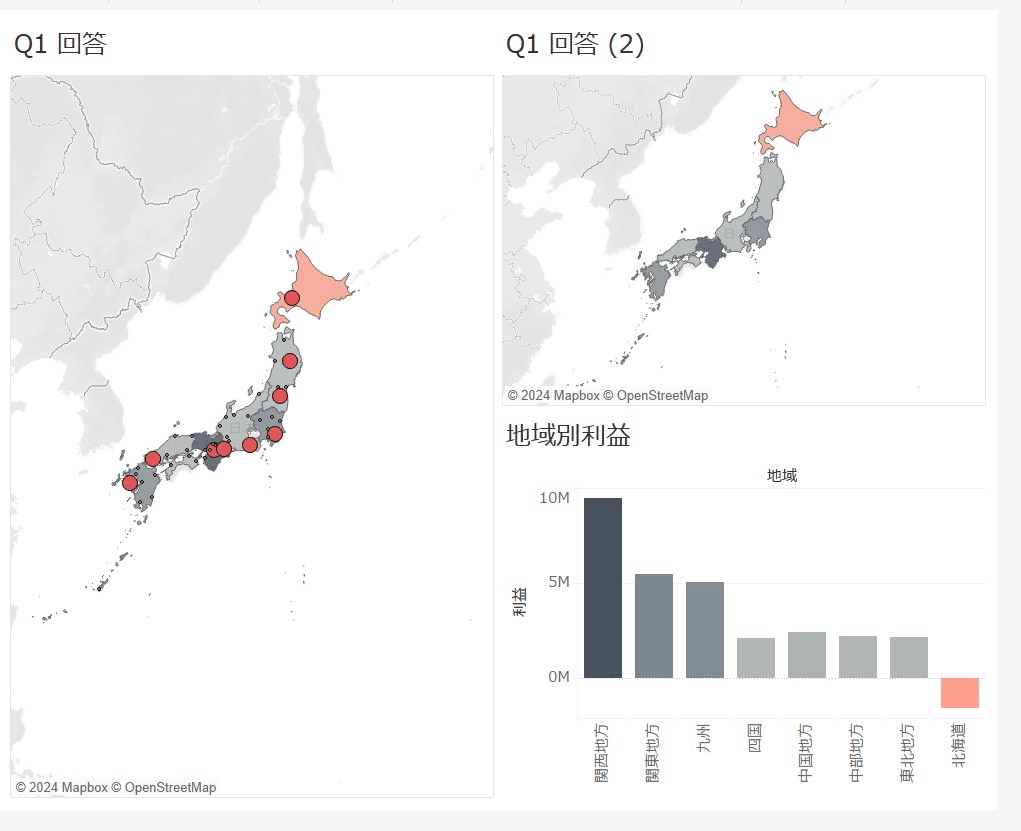
ダッシュボードとして表すと、除外された時の地域別の利益の変化が分かりやすいです。
Q1回答のシートをフィルターとしてクリックした時に、他のシートも除外されるようにしたいので、ダッシュボードでフィルターアクションを追加します。
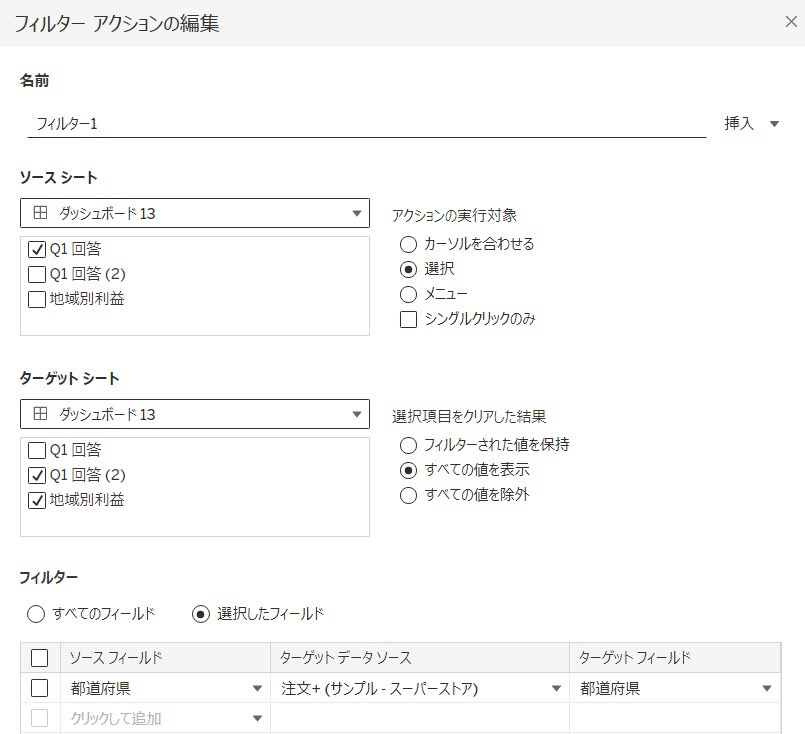
それぞれのシートのフィルターも編集します。
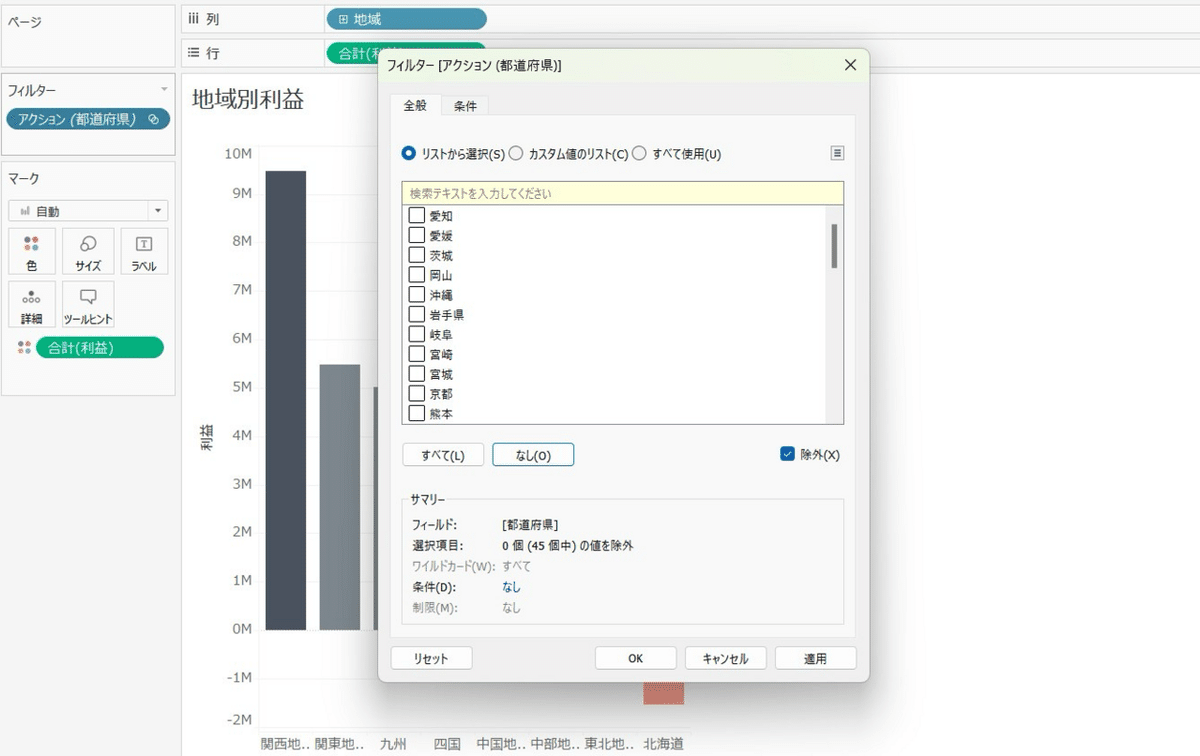
全て「除外」で条件「なし」を選択
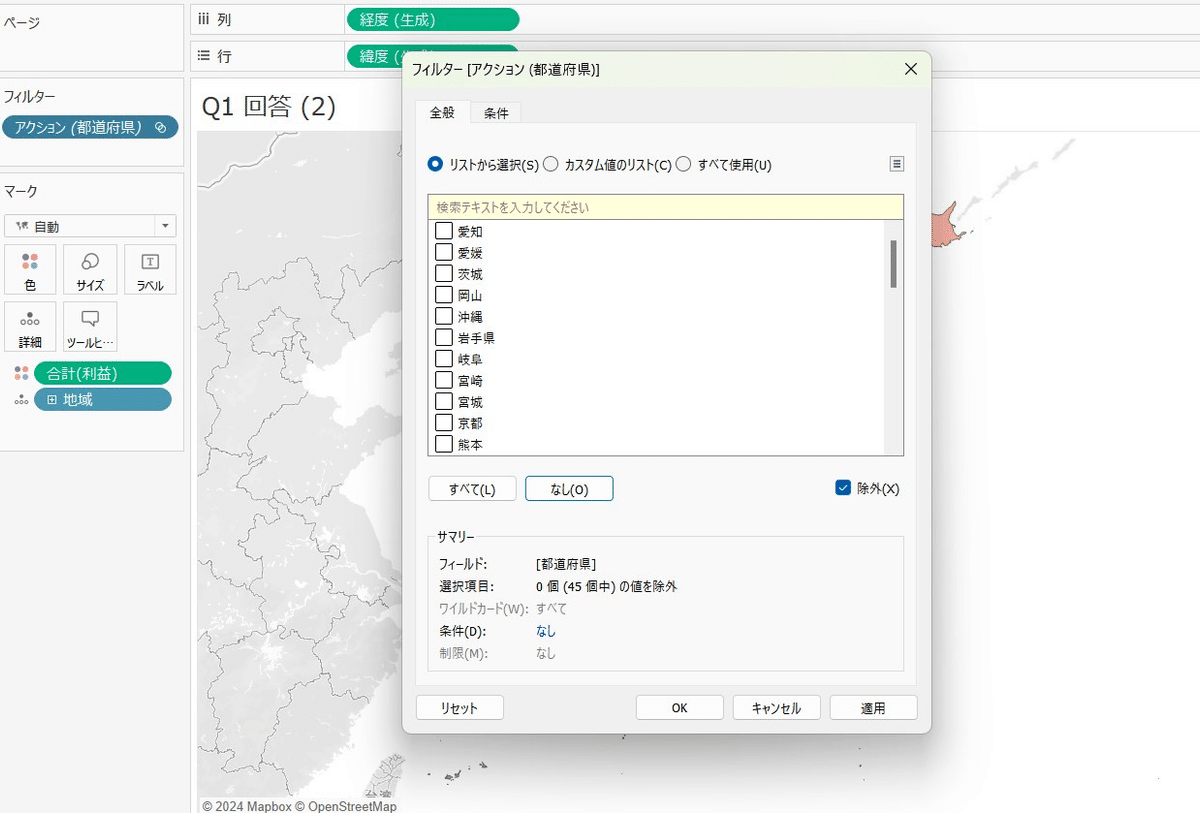
もう一方も同様に
それぞれフィルターを編集したら、静岡県を除外すると中部地方の利益がだいぶ上がることがわかります!
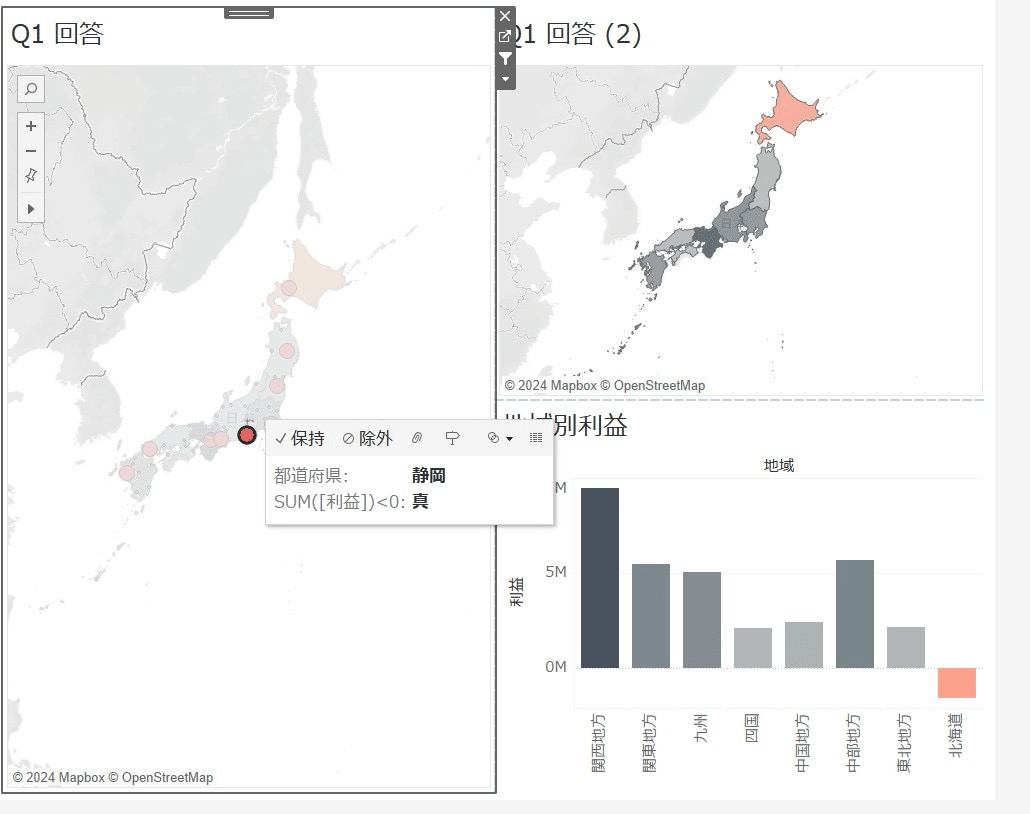
静岡県の地域の担当マネージャーは?
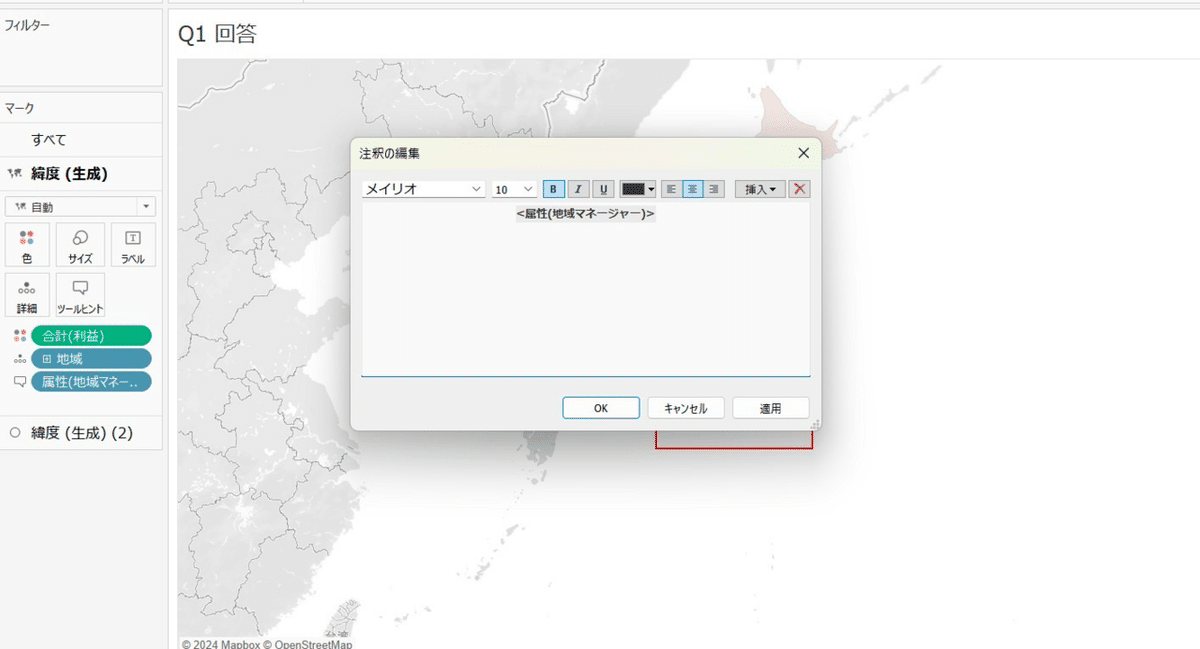
地域の担当マネージャーを注釈で入れます。
注釈からマークを選択して編集すると、担当マネージャーが一目でわかりますね!
Q2 プライマリグループの作成、円の分布

メーカー情報が入ってない…ので、
メーカーの情報が結合できるのがベスト!
ですが、データをコピーして持ってくると、データ接続の画面ではなく別々のデータとして使えるようになります。
メーカー情報は製品IDで紐付くので、別々のデータとして使う時はブレンドで紐付けます。
製品IDでリンクしたい時は鎖マークでリンクできます!🔗
注意ですが、何でもかんでもくっつけるとパフォーマンスが悪くなるので、リンクは必要なものに限ります!
今回の場合はメーカーの情報を取るために製品IDが必要となります。
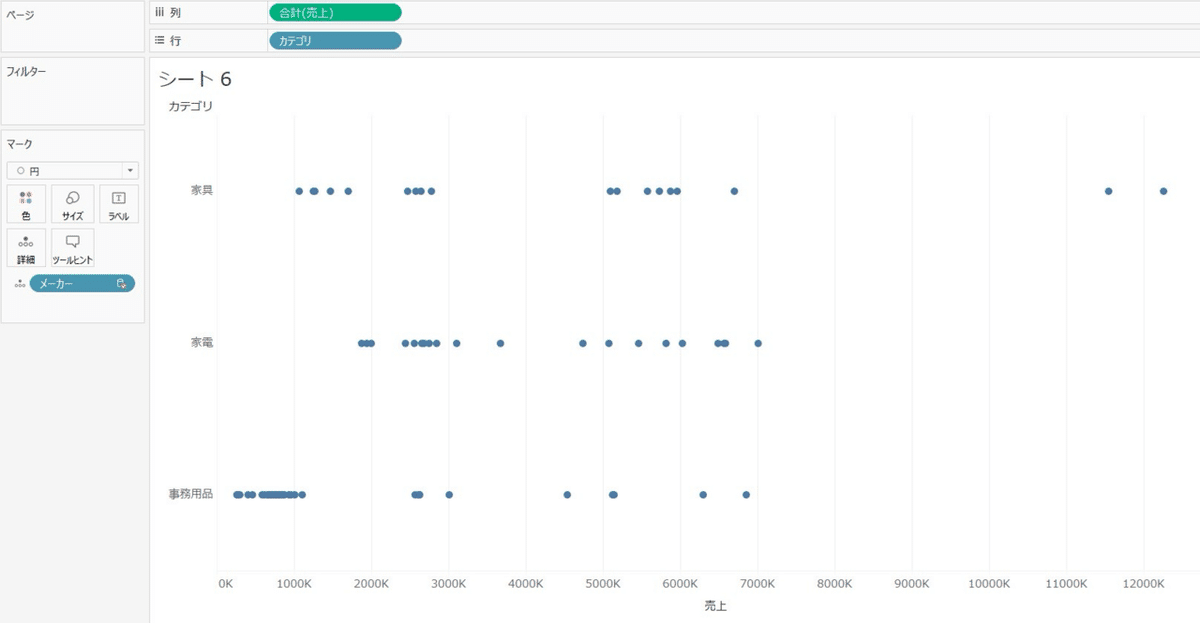
メーカーごとの売上の分布をカテゴリで分けます。
ブレンドは便利だけど、人に編集させるデータソースとして使用する場合は不安…という時は、
プライマリデータソースに仕込むことができます!
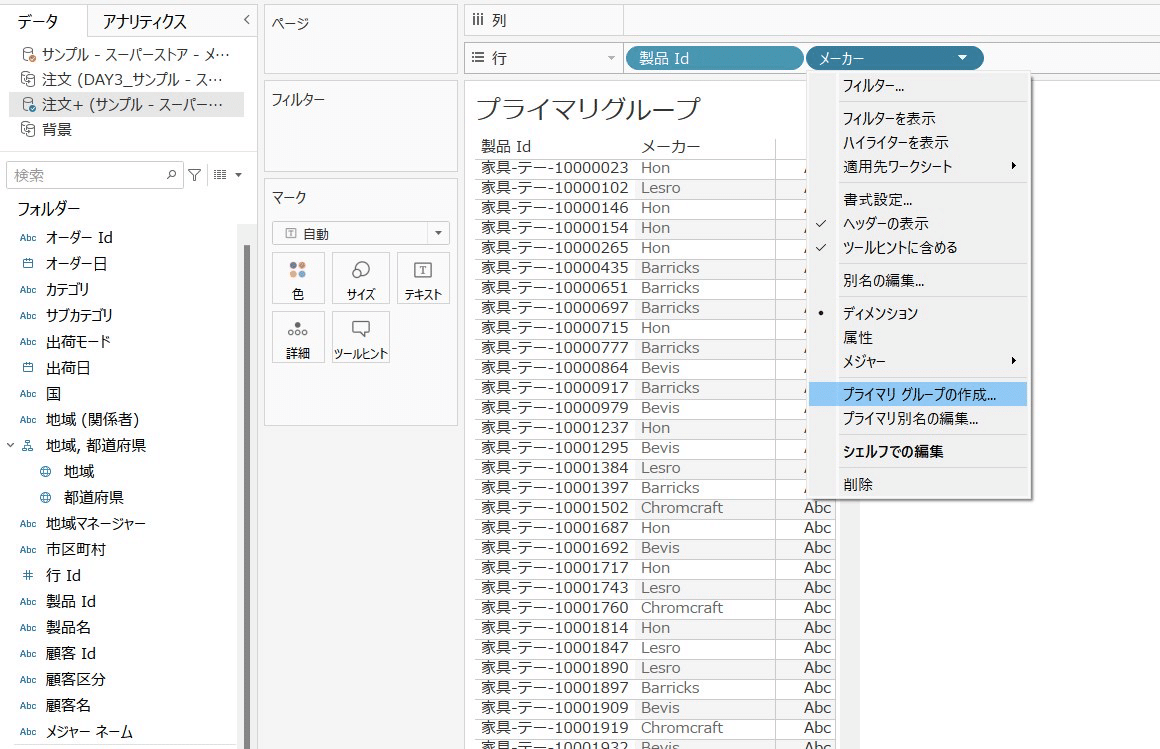
サンプルスーパーストアの製品IDとメーカーを行に並べると、プライマリグループの作成ができます。
→セカンダリデータソース🟠☑️の項目を持ってきた時に、その項目を使ってプライマリデータソース🔵☑️の方にそれをグループ化した新たな項目として追加しますか?という意味です。
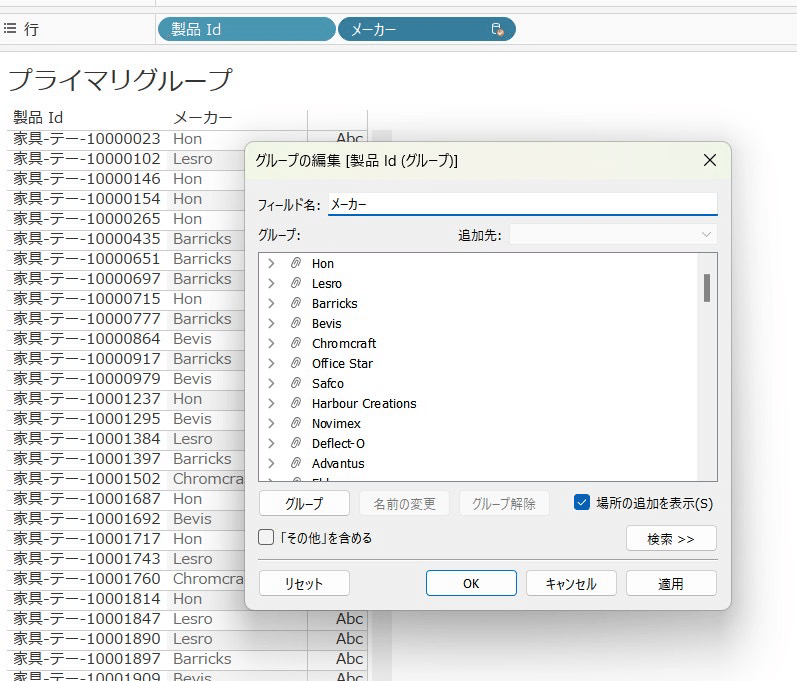
作成すると、プライマリデータの方に「メーカー」(作成した項目)が新たに出現します!
前のシートに戻って「メーカー」を新しい項目の「メーカー」に入れ替えると完了です。
利益を色に入れて分布を見ると赤字になってるメーカーの売上の特徴が見えてきます。
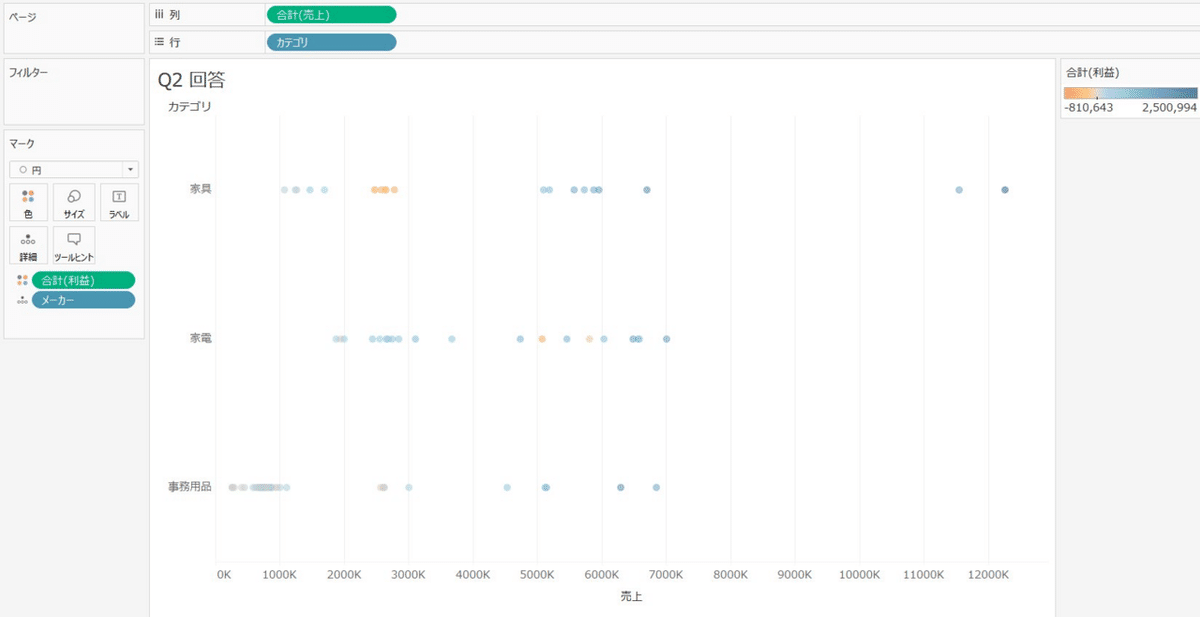
⭐️円の分布は空間グループの考え方で、近い売上が集まるので特徴がわかりやすいです!
JOIN、ブレンド、クロスデータベース結合
JOIN
あるキー項目を使って行単位で結合します。結合した後は大きなテーブルになり、行も列も増えたように見えます。
ブレンド
集計してからある項目で結合します。
セカンダリデータソースの項目はプライマリデータソースになければ、結果に登場しません。
NULLは、セカンダリデータソースに項目がない場合、
*は区切られているディメンションの中で複数以上の項目が出た場合、LODシートの中で選ばれた集計範囲の中では一つに絞れませんという意味になります。
(JOINだと、複数の項目で登場するため重複データには注意⚠️)
クロスデータベース結合
基本的に形はJOINと同じです。
違いは、別のデータベースにあるテーブルをJOINできるということ
⭐︎多くの人が簡単に、正しく、安全にデータを使用できます。
詳しくは以下のYouTubeでKTさんが説明しておりますのでご参考に…(1:02:30~)
Q3 予実対比

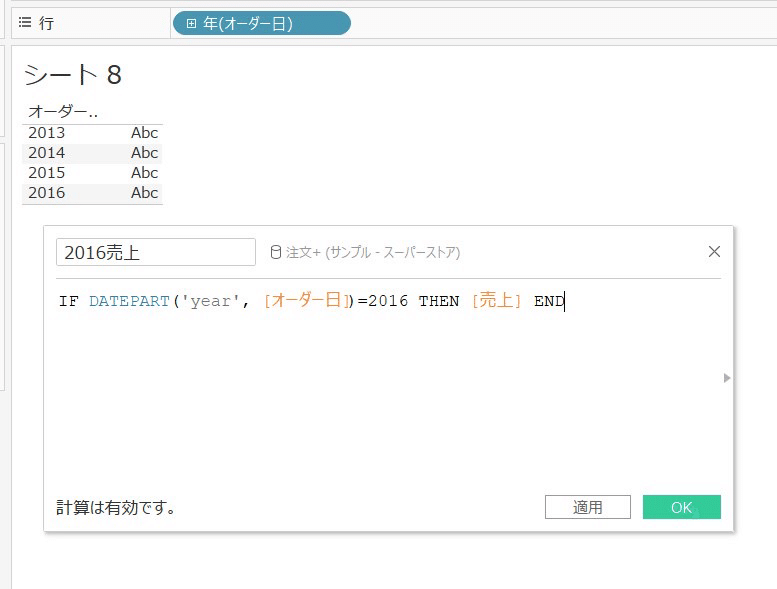
まずは、2015年売上と2016年売上を比較する計算式をつくります。
そのときに、
⭐️オーダー日を行に持って行って計算式を作ると楽!
⭐️複製すると楽!
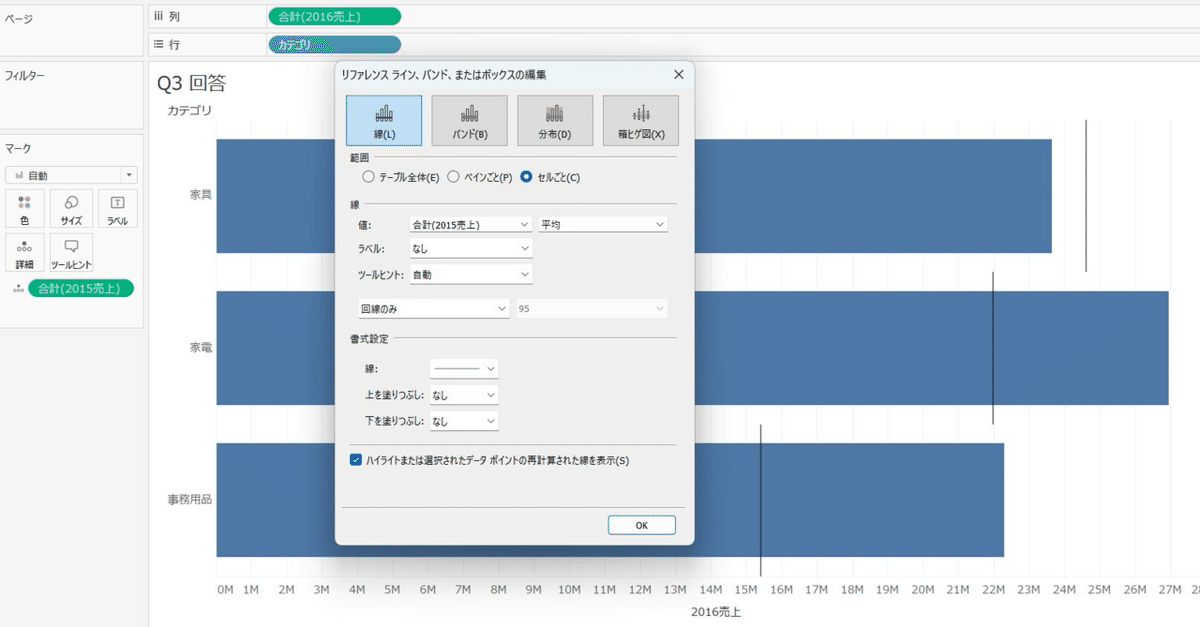
リファレンスラインで2015年の売上を挿入したら比較がしやすくなります。
Q4 集計と非集計

まず、1行単位の利益がみたいので
→集計されている利益を集計されていない利益にします。
やり方①
【分析】からデフォルトになっている【メジャーの集計】を外します。
合計(利益)→利益 になりますが、
全てのデータのメジャーの集計が外れるため、データが増えると危険なやり方です!
やり方②
合計(利益)から【ディメンション】を選択すると、利益になります。
こっちのやり方だと個々で集計を外すことができますね!
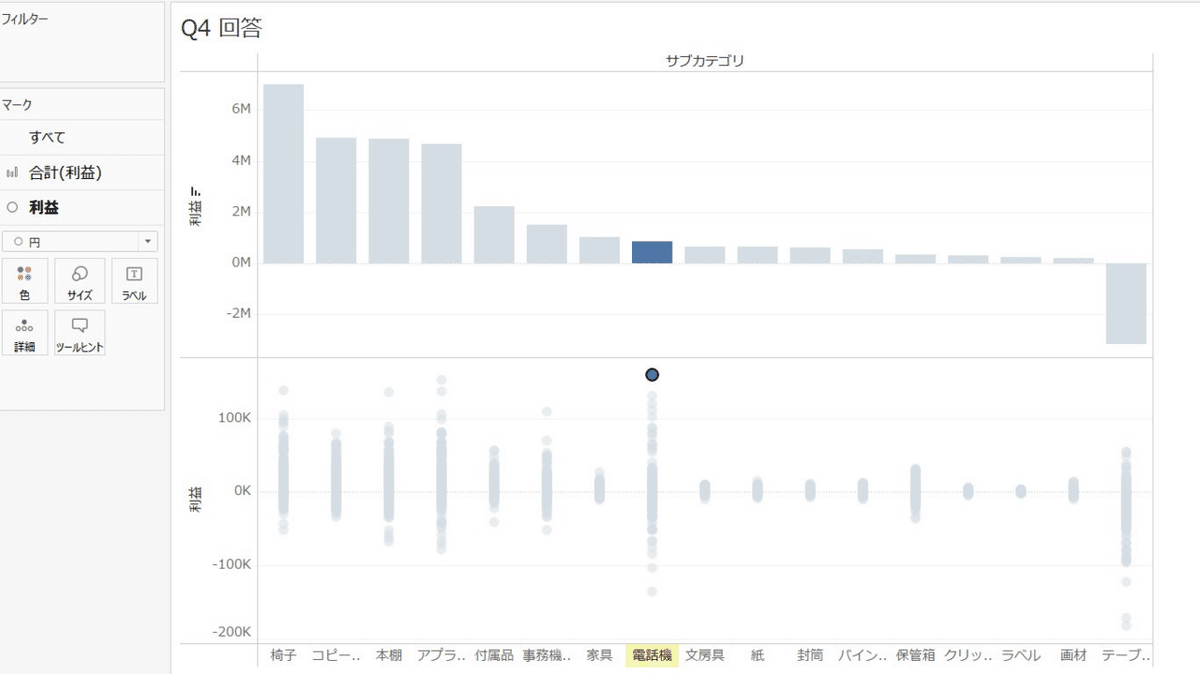
合計(利益)と利益を比較すると、
最も大きな利益を出してる電話機は好調ではないことがわかります。
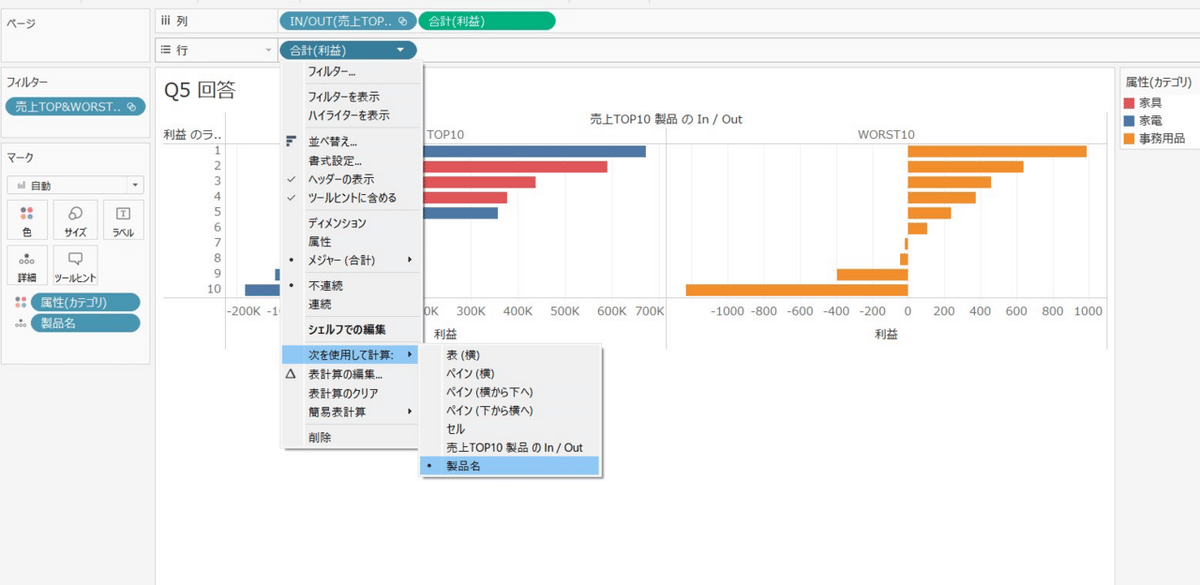
Q5 セットの作成

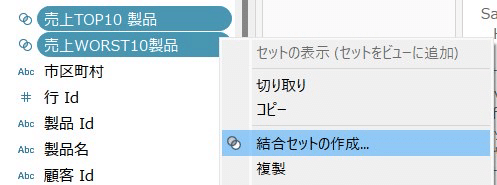
トップ10とワースト10を同時に見るには、セットの作成です!
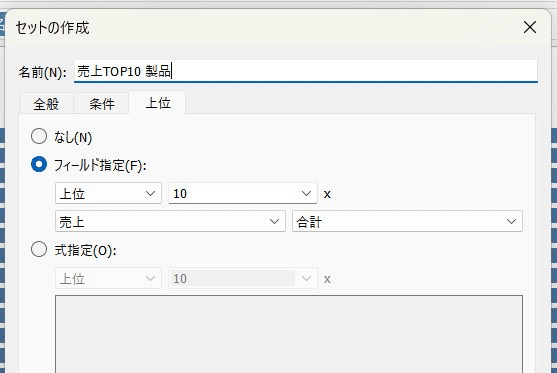
フィルターからセットの作成を選択します。
フィールドの指定で売上のトップ10製品を選、ワースト10製品のセットも同様に作成します。
両方のセットを複数選択して「結合セット」を作成します。
結合したセットをフィルターに持ってくると、トップ10とワースト10製品がフィルターされます。
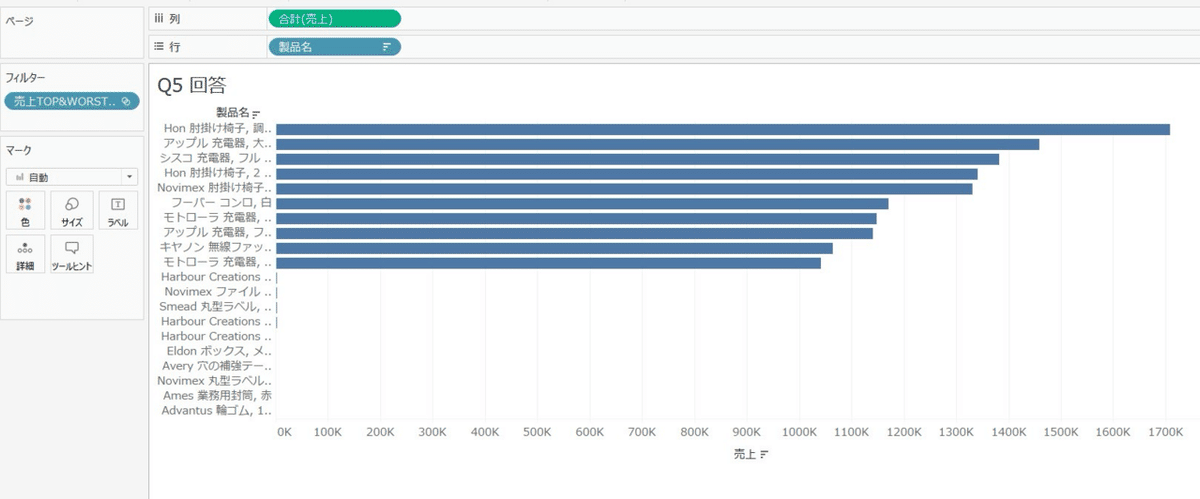
TOP10とWORST10で列を分けて、見やすくします。(WORST10の軸を独立した軸範囲にする)
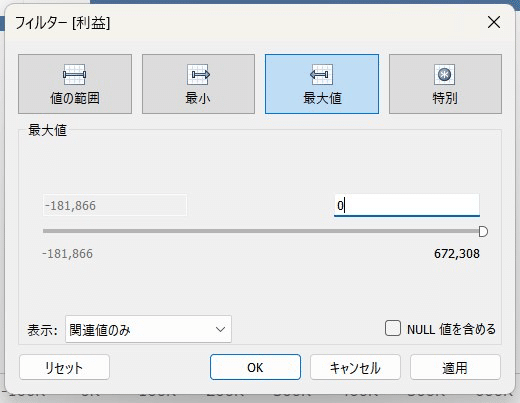
赤字の製品が知りたいので、利益の最大を0にしてフィルターに入れます。
カテゴリを色に入れてみると家電と事務用品だけということがわかります。
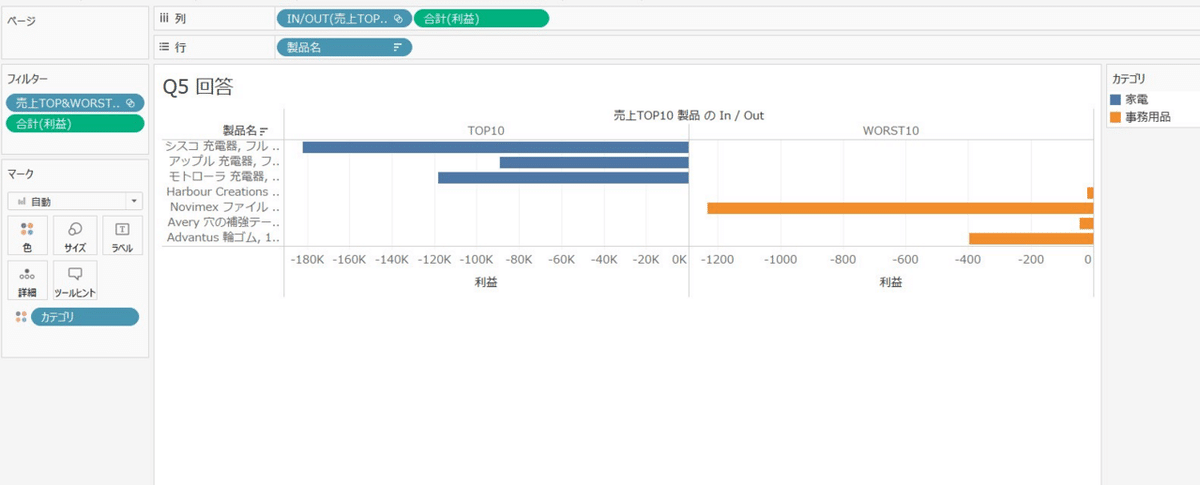
ちなみに、利益をランクの表計算にして、不連続にするとヘッダーとして使うことができます。
属性はこれ以上の粒度で切りたくないけど情報として入れたい時に使います。