機械学習”初心者”が、NFL24年スーパーボウルの優勝チームを予測してみた!!

はじめに
この記事は私がAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
開発環境
Python 3
note
Google Chrome
Google Colaboratory
目的
50歳になりましたが、プログラミングやデータ活用の面白さを日々感じており、Aidemyのデータ分析講座を受講しました!!
今回、その学習成果の確認として、kaggleのNFLデータを活用した分析を行いました。
2003‐2023年シーズンのチームデータを活用し、2024年スーパーボウル(2023年シーズンの優勝チーム決定戦)の優勝チーム予測を行いました。
分析アジェンダ
下記流れで分析を行いました。
データの確認
データの前処理
訓練データとテスト(予測)データの準備
教師なし学習 非階層的クラスタリング「k‐means法」による分析
エルボー法によるクラスター数の決定
クラスタリングの実施、結果確認
予測、結果まとめ
0.使用する関数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans1.データの確認
kaggleから入手したデータ「team_stats_2003_2023.csv」の確認。
データの取り込み ※コード省略

カラムの確認
※ちなみに、カラム内容はchatGPTで翻訳確認。
・year: NFLのシーズンの年。
・team: NFLのチームの名前。
・wins: シーズンでチームが勝った試合の数。
・losses: シーズンでチームが負けた試合の数。
・win_loss_perc:
チームの勝率。勝った試合の数をプレイした試合の総数で割る。
・points: シーズンでチームが得点したポイント総数。
・points_opp: シーズンでチームが失点したポイント総数。
・points_diff: 「points」から「points_opp」を引いた値。
・mov:
「points」から「points_opp」を引いた値を勝った試合数で割る。
・g: シーズンでチームがプレイした試合総数。
・total_yards: チームがシーズンで獲得した総ヤード数。
・plays_offense: チームがシーズンで行ったオフェンスプレイ総数。
・yds_per_play_offense:
オフェンスプレイあたりの平均ヤード数。「total_yards」を
「plays_offense」で割る。
・turnovers: チームがシーズンで失ったターンオーバー総数。
・fumbles_lost: チームがシーズンで失ったファンブル総数。
・first_down: チームがシーズンで獲得したファーストダウン総数。
・pass_cmp: チームがシーズンで成功したパス総数。
・pass_att: チームがシーズンで試みたパス総数。
・pass_yds: チームがシーズンで獲得したパスヤード総数。
・pass_td: チームがシーズンで獲得したパスタッチダウン総数。
・pass_int: チームがシーズンで受けたインターセプト総数。
・pass_net_yds_per_att:
パス試行あたりの純パスヤード数。「pass_yds」を「pass_att」で割る。
・pass_fd: チームがシーズンで獲得したパスによるファーストダウン総数。
・rush_att: チームがシーズンで試みたラン総数。
・rush_yds: チームがシーズンで獲得したランヤード総数。
・rush_td: チームがのシーズンで獲得したランタッチダウン総数。
・rush_yds_per_att:
ラン試行あたりの平均ランヤード数。「rush_yds」を「rush_att」で割る。
・rush_fd: チームがシーズンで獲得したランによるファーストダウン総数。
・penalties: チームがシーズンで受けたペナルティ総数。
・penalties_yds: チームがシーズンで受けたペナルティのヤードロス総数。
・pen_fd:
チームがシーズンで獲得した敵のペナルティのファーストダウン総数。
・score_pct: チームが得点を挙げたドライブの割合。
・turnover_pct: チームがターンオーバーを起こしたドライブの割合。
・exp_pts_tot: チームがシーズンで獲得した期待ポイント総数。
・ties: チームが引き分けた試合の数。
データ(data)の行数、列数の確認
data.shape出力結果:(672, 35)
2.データの前処理
分析用カラムの追加
以下カラムを追加。
・team_code: team名を略称化 。
・superbowl_winner: 2022年までスーパーボール優勝チーム。
#新規カラムとしてteam名を省略したもの(team名が長くて扱いづらいため)
#team略称の辞書
dict_team ={'New England Patriots': 'nwe',
'Miami Dolphins': 'mia',
'Buffalo Bills': 'buf',
'New York Jets': 'nyj',
'Baltimore Ravens': 'rav',
'Cincinnati Bengals': 'cin',
'Pittsburgh Steelers': 'pit',
'Cleveland Browns': 'cle',
'Indianapolis Colts': 'clt',
'Tennessee Titans': 'tti',
'Jacksonville Jaguars': 'jax',
'Houston Texans': 'htx',
'Kansas City Chiefs': 'kan',
'Denver Broncos': 'den',
'Oakland Raiders': 'rai',
'San Diego Chargers': 'sdg',
'Philadelphia Eagles': 'phi',
'Dallas Cowboys': 'dal',
'Washington Redskins': 'was',
'New York Giants': 'nyg',
'Green Bay Packers': 'gnb',
'Minnesota Vikings': 'min',
'Chicago Bears': 'chi',
'Detroit Lions': 'det',
'Carolina Panthers': 'car',
'New Orleans Saints': 'nor',
'Tampa Bay Buccaneers': 'tam',
'Atlanta Falcons': 'atl',
'St. Louis Rams': 'ram',
'Seattle Seahawks': 'sea',
'San Francisco 49ers': 'sfo',
'Arizona Cardinals': 'crd',
'Los Angeles Rams': 'ram',
'Los Angeles Chargers': 'sdg',
'Las Vegas Raiders': 'rai',
'Washington Football Team': 'was',
'Washington Commanders': 'was'}
#team列をkeyにカラム作成
data["team_code"] = data["team"].map(dict_team)#2022年までのスーパーボウル優勝チームをフラグ化
#yearとteamを結合したカラムを作成(後ほどkeyとして使用)
data["year_team"] = data["year"].astype(str) + data["team"]
#各年のスーパーボウル優勝チームを辞書化
dict_spw = {'2003New England Patriots': 1.0,
'2004New England Patriots': 1.0,
'2005Pittsburgh Steelers': 1.0,
'2006Indianapolis Colts': 1.0,
'2007New York Giants': 1.0,
'2008Pittsburgh Steelers': 1.0,
'2009New Orleans Saints': 1.0,
'2010Green Bay Packers': 1.0,
'2011New York Giants': 1.0,
'2012Baltimore Ravens': 1.0,
'2013Seattle Seahawks': 1.0,
'2014New England Patriots': 1.0,
'2015Denver Broncos': 1.0,
'2016New England Patriots': 1.0,
'2017Philadelphia Eagles': 1.0,
'2018New England Patriots': 1.0,
'2019Kansas City Chiefs': 1.0,
'2020Tampa Bay Buccaneers': 1.0,
'2021Los Angeles Rams': 1.0,
'2022Kansas City Chiefs': 1.0}
#year_team列をkeyにカラム作成(優勝チーム以外は値0。year_team列は削除。)
data["superbowl_winner"] = data["year_team"].map(dict_spw).fillna(0)
data = data.drop("year_team", axis=1)欠損値の確認
data.isnull().sum()
出力結果:
・"mov"、"ties"のデータの大部分が欠損。
欠損値の処理
欠損値の多い”mov”を、カラム内容から判断し計算してデータ挿入。
#欠損値処理:カラム内容から判断し計算、データを挿入。
data["mov"] = data["mov"].fillna(data["points_diff"]/data["g"])欠損値の多い"ties"は、分析に使用しないので列削除。
#欠損値処理:""ties"は分析に使用しないので削除
data = data.drop("ties", axis=1)3.訓練データとテスト(予測)データの準備
2022年までのデータを訓練データ、2023年データをテスト(予測)データ。
#2022年までと2023年のシーズンデータに分ける。
data_to_2022 = data.query('year != 2023')
data_2023 = data.query('year == 2023')加えて、クラスタリングに必要ないカラムを削除。
#クラスタリングに必要のないカラムを削除。
cols_drop = ["year","team","team_code","superbowl_winner"]
data_to_2022_drop = data_to_2022.drop(cols_drop, axis=1)
data_2023_drop = data_2023.drop(cols_drop, axis=1)4‐1.k‐means法:エルボー法によるクラスター数の決定
エルボー法を使用し、クラスター数を決定。
#訓練データを使用し、エルボー法でクラスター分割数の目安確認。
distritions = []
for i in range(1,11):
km = KMeans(n_clusters=i,
init="k-means++",
n_init=10,
max_iter=300,
random_state=0)
km.fit(data_to_2022_drop)
distritions.append(km.inertia_)
plt.plot(range(1,11), distritions)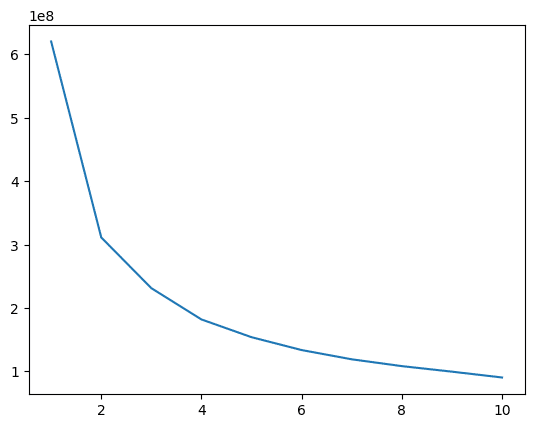
出力結果:クラスター数を6に決定。
4‐2.k‐means法:クラスタリングの実施、結果確認
訓練データを使用し、クラスタリングを実施。
#訓練データでクラスター分け(分類数は6)。
km = KMeans(n_clusters=6,
init="k-means++",
n_init=10,
max_iter=300,
random_state=0)
km.fit(data_to_2022_drop)
y_km = km.predict(data_to_2022_drop)どのクラスターが、過去スーパーボウル優勝チームが多いか確認。
#元データにクラスター情報を挿入
data_to_2022_cl = data_to_2022.copy()
data_to_2022_cl["cl"] = y_km
#スーパーボウル優勝チームのクラスター比率(横計)
data_to_2022_cl_spwin = pd.crosstab(data_to_2022_cl["cl"], data_to_2022_cl["superbowl_winner"], normalize="columns")
data_to_2022_cl_spwin.columns = ["優勝なし", "優勝あり"]
data_to_2022_cl_spwin = pd.DataFrame(data_to_2022_cl_spwin["優勝あり"])
data_to_2022_cl_spwin.T
出力結果:
クラスター4が優勝チームが多い。
(2003から2022年の優勝チームの4割を占める。)
クラスターごとのシーズン成績平均値を可視化。
#クラスターごとのシーズン成績平均値
data_to_2022_cl_mean = data_to_2022_cl.loc[:,"wins":].groupby("cl").agg("mean")
#各クラスターの特徴可視化
cols = data_to_2022_cl_mean.columns
fig, axes = plt.subplots(11,3, figsize= (20,40))
plt.rcParams["font.size"] = 12
for col, ax in zip(cols, axes.ravel()):
sns.barplot(x=data_to_2022_cl_mean.index, y=data_to_2022_cl_mean[col], hue=data_to_2022_cl_mean.index, palette="bright", ax=ax)
ax.axhline(0, color="grey")
ax.get_legend().remove()
plt.tight_layout()
続いて、クラスター別でのパス力とラン力(1パス、1ランあたりの獲得ヤード数の大きさ)のバランスを確認。
#クラスター別に、パス力とラン力のバランス評価(1パス、1ランあたりの獲得ヤード数の大きさ)
plt.figure(figsize=(10,5))
sns.scatterplot(data_to_2022_cl_mean, x="pass_net_yds_per_att", y="rush_yds_per_att", hue="cl", palette="bright")
plt.tight_layout()
同様にパス力とラン力のバランスを、クラスタ―別に全チーム確認。
#クラスター別のパス力とラン力のバランス評価(全チーム)
plt.figure(figsize=(10,5))
sns.scatterplot(data_to_2022_cl, x="pass_net_yds_per_att", y="rush_yds_per_att", hue="cl", palette="bright")
plt.tight_layout()
出力結果:
スーパーボウル優勝比率の高いクラスター4(紫)の特徴は以下。
・パス力(パスの獲得ヤード数、1パスあたりの値)が他と比べて高い。
このクラスタ―に入る全チームの結果を見ても、これが特に特徴的。
・これに対してラン力(ランの獲得ヤード数および1ランあたり)は
他と比べて高くない。ただし、チームによって、ばらつきはある。
・ファンブル、インターセプトといったミスが少ない。
4‐3.k‐means法:予測、結果まとめ
訓練データで学習したモデルを使用し、テストデータで予測。
#学習したモデルを使用し、2023年データをクラスター分け
y_km_2023 = km.predict(data_2023_drop)
#元データにクラスター情報追加
data_2023_cl = data_2023.copy()
data_2023_cl["cl"] = y_km_20232024年スーパーボウル出場2チームの結果を確認。
(sfo:サンフランシスコ・49ers、kan:カンザスシティ・チーフス)
#2023年スーパーボール出場2チームの情報確認
data_2023_cl.loc[data_2023_cl["team_code"].isin(["sfo","kan"])]
出力結果:
49ersは、スーパーボウル優勝比率の高いクラスター4。
チーフスは、クラスタ―0。
各チームの2023年シーズン成績をあらためて確認。
#2023年チーム別各種データ傾向
data_2023_flg = data_2023_cl.copy()
data_2023_flg["flg"] = data_2023_flg["team_code"].map(lambda x: 1 if x in ["sfo","kan"] else 0)
fig, axes = plt.subplots(16, 2, figsize= (20,60))
cols = ['wins', 'losses', 'win_loss_perc','points', 'points_opp', 'points_diff', 'mov', 'g', 'total_yards',
'plays_offense', 'yds_per_play_offense', 'turnovers', 'fumbles_lost',
'first_down', 'pass_cmp', 'pass_att', 'pass_yds', 'pass_td', 'pass_int',
'pass_net_yds_per_att', 'pass_fd', 'rush_att', 'rush_yds', 'rush_td',
'rush_yds_per_att', 'rush_fd', 'penalties', 'penalties_yds', 'pen_fd',
'score_pct', 'turnover_pct', 'exp_pts_tot']
for col, ax in zip(cols, axes.ravel()):
data_2023_flg_grp = data_2023_flg.groupby(["team_code","flg"])[col].sum().unstack()
data_2023_flg_grp.plot(kind="bar", stacked=True, legend=False, fontsize=14, ax=ax)
ax.set_title(str(col))
ax.axhline(0, color="grey")
plt.tight_layout()
出力結果(全体まとめ踏まえて):
・2024年スーパーボウル出場の49ers(sfo)とチーフス(kan)傾向は以下。
‐ 49ersは、過去スーパーボウル優勝チームが最も多いクラスター4。
‐ 49ersは、パス力、ラン力ともに高い。
特にパス力が高いのが特徴で、またミスも少なく、これら傾向は
クラスタ―4の傾向と同一。
‐ チーフスは、パス力は他と比べ上位(これはクラスタ―0の傾向)。
ランは平均的で、ミスは49ersよりも多い。
・これら結果を踏まえると、49ersが2024年スーパーボウルにおいて
チーフスを破って優勝する可能性が高いと予測。
‐ スーパーボウル優勝においての鍵は、パス力とミスの少なさと推察。
最後に
当初は、スーパーボウル優勝チームのデータをもとに教師あり学習の分類という無謀な方法も考えたが、データ数も少なく、32チーム/年の中から優勝1チームをピタッと予測するのはさすがに無理。
そこで、これまでの優勝チームの傾向と今回(2024年大会)の出場チームの傾向をクラスタリングで紐解こうと考えました。
クラスタリングという手法で、正解のない状態(教師なし)からデータ傾向を読み解き、そこに解釈を加えていく面白さを感じました。
(実際の勝負の結果は、この結果とは異なるやもではありますが、、、)
引き続き、研鑽を積みたいと思います。
この記事が気に入ったらサポートをしてみませんか?