
正しいCreate Setのオリジナルコンポーネントを開発してみた

背景
Listをつないだときに重複するデータがある場合、重複しないように1つずつにしてデータをまとめ直す『Create Set』というコンポーネントがあります。
アウトプットの『S』(Set)からはまとめ直した個別のデータが出力され、『M』(Map)からは元のデータがSetの何番目のデータを使用しているかを出力します。
データが重複する場合、重複したすべてのデータに対して処理すると無駄な計算をすることになり、できればきちんと処理したいところですね。
最悪、力任せに重複してようとしてなかろうとすべてのデータに対して計算してしまえば同じ形状は得られるかもしれませんが、スマートじゃないですね。
そんなときにしばしば使いたいコンポーネントが『Create Set』です。
と、いうことでしばしば使ってたのですが、今回、思った結果が得られなかったので、少し深堀りしてみました。
このような簡単なサンプルを用意しました。
X・Y・Z方向にいくつの箱を並べて積んだだけの単純なブロックの塊です。

このモデルのEdgeを取得してみましょう。
『Brep Edges』コンポーネントに積み上げたブロックをつないでみます。

ブロックのEdgeが取得できました。
次はブロックを非表示にしてみます。

ジャングルジムのようですね。
このジャングルジムを実際に作ることを考えてみます。では、どれだけの部材を用意すればいいでしょうか?
それぞれの線分としては見えてるので簡単そうですが、小さなブロックを積み上げてそのEdgeを表示してるのでしたね。
つまり、ブロックが他のブロックと接している箇所はEdgeが重複してるわけです。
重複、そうです。『Create Set』につながってきました。
この重複を取り除きたい、というのが今回の目的です。
ネイティブの『Create Set』
では、Grasshopperにネイティブで用意されているコンポーネント『Create Set』を試してみます。
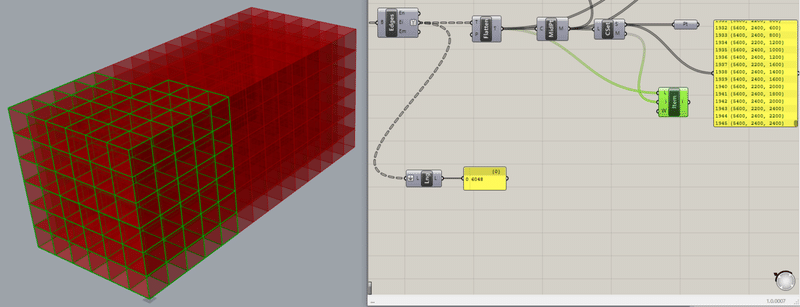
単純にEdgeの線での重複処理はうまくいかないので、それぞれのEdgeの中点を『Curve Middle』コンポーネントで取得します。
得られたPointのListを『Create Set』にインプットすることで重複したデータをまとめ直します。
おさらいですが、『Create Set』は、アウトプットの『S』(Set)からはまとめ直した個別のデータが出力され、『M』(Map)からは元のデータがSetの何番目のデータを使用しているかを出力します。
つまり、重複整理されたPointは元々どのEdgeだったのかが『M』から得られるので、そのインデックスを使ってEdgeの線を『List Item』で最後に表示してます。
これで表示されるEdgeが上の図の通りです。重複したEdgeを整理して重なりをなくしたはずなのですが、結果は偏ったEdgeが選択されており、重複処理が思うようにできてません。
ちなみに、このときのEdgeの総数は、Listの最後を見ると1946個のようです。
オリジナルの『Create Set』
では、次にオリジナルのコンポーネントとして重複処理のロジックを書き直したオリジナルコンポーネントにつなぎ変えてみます。
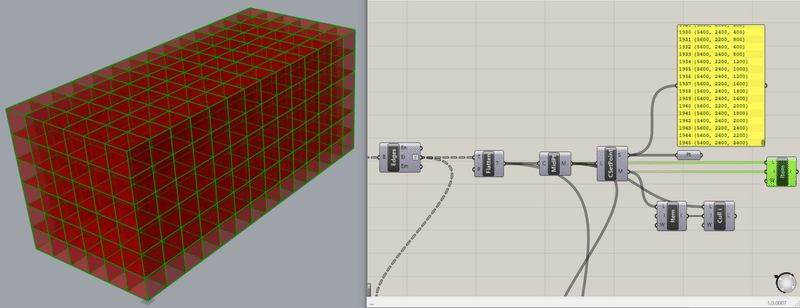
どうでしょう?
今度は全体にEdgeの線が表示されているようです。ちなみに、Listで数を確認すると、こちらも1946個となってますね。
同じ目的で重複整理し、処理された結果、残った数は同じ。ただし、重複で整理されたものが異なるということになりました。
今回、やりたかったのは、このジャングルジムを作るために構成する各辺を取得するということだったので、重複整理としてはオリジナルでロジックを書き直したコンポーネントが適してるようですね。
このように重複整理したいために、重複整理のプログラム処理を書いてみると、その検証の過程でネイティブの『Create Set』がどのようなプログラムだったかが見えたので、示しておきたいと思います。
ネイティブとオリジナルの重複整理プログラムの比較
では、早速ですが、ネイティブの『Create Set』の重複整理のロジックを再現したのが以下です。
for (int i = 1; i < (listToSameRemove.Count); i++)
{
var newListItem = listToSameRemove[i];
for (int j = 0; j < (removedList.Count); j++)
{
var removedListItem = removedList[j];
if (removedListItem == newListItem)
originalMap.Add(j);
if (removedListItem == newListItem)
break;
else if (j == removedList.Count - 1)
removedList.Add(newListItem);
}
}重複整理した結果として取得したいListの生成過程で、元々の全体Listのものと重複整理後候補Listとを順に重複CKした結果、一致するものがあれば、アウトプット『M』のListに重複整理後候補Listのインデックスを追加していき、このとき重複整理後候補Listにすでに一致する要素があったということで、その後の比較を打ち止めてます。
この比較をしていき、重複整理後候補Listの最後まで比較していっても一致するものがなければ重複整理後候補Listに加えます。
という流れです。
次に、オリジナルで書いたロジックです。
for (int i = 1; i < (listToSameRemove.Count); i++)
{
var newListItem = listToSameRemove[i];
for (int j = 0; j < (listToSameRemove.Count); j++)
{
var removedListItem = listToSameRemove[j];
if (removedListItem == newListItem)
originalMap.Add(j);
if (j == i)
removedList.Add(newListItem);
if (removedListItem == newListItem)
break;
}
}まず、大きな違いは、ループする範囲は重複整理前のListの最初から最後まで同士で比較していくことになります。
比較した結果、一致すれば、アウトプット『M』のListにインデックスを追加し、比較したそれぞれのインデックスが同じであれば、つまり、比較時点の最後であれば、重複整理後候補Listに追加し、一致する要素があったということで、その後の比較を打ち止めます。
いつもサポートいただきありがとうございます! これからもあなたの代わりに役立つ記事を更新し続けていきます。 どうぞよろしくお願いします。