
ChatPDFを使って大量データ分析できないかやってみた

今回もGPTネタではあります。いろいろ考えていたら思いついたChatGPTの弱点のひとつである「プロンプトの長さ」の問題をちょっとズルして解決してみようと思いますので、同時進行で記事にしてみたいと思います。
非エンジニアの我々はどうやってLLMの課題を乗り越えるのか?
大きな話題になっているChatGPTを始めとするLLMですが、いろいろと弱点があります。トークンの量が足りないのであまり長いプロンプトの質問ができないとか、結果が正しくないとか、様々なことが言われています。また、その課題に対する技術・・・ReActとかLangChainとかSemantic Kernelとかを使ってこれらを克服しようとしています。
しかしながら我々エンジニアでもない凡人はそんな強強なことはできそうにありません。だからといってマスコミや昭和脳の人たちみたいに「使えなそう」と唾を吐いたり、「もうちょっと完成してから」と先送りするのは悲しすぎます。
プロンプトエンジニアリング力を鍛えるのも良いのかもしtれませんが、次々に出る新しいサービスをうまいこと利用して解決するくらいならデキそうな気がします。そんなこんなで今回はそういうやり方でChatGPTの弱点のひとつを乗り越えて見ようと思います。
プロンプトの文字数制限の課題
いろいろ試してみて、最も痛烈に感じる限界は「トークンの制限」の問題です。よく言われる「嘘をつく」問題はプロンプトで制約をかけていけばかなりの線で解決できます。しかしながらプロンプトの長さ制限だけは、そんな小手先の努力ではどうしようもない感じで圧倒的な壁になっています。
たとえばデータの分析なんかかなりいい線いっている結果を出せるのに扱えるデータ数が50くらいなので、まだまだ実用的ではありません。せいぜい日々のデータを日々ごとに要約して報告する仕事(日報とか連絡帳のコメント)くらいにしか使用できません。ビックデータとまでは言わずとも、そこそこの件数を処理できないものかと頭を悩ませていました。
ChatPDFの登場で思いつく
これが一変したのは「ChatPDF」というサービスの登場です。このサービスはPDFファイルを読み込ませて、その範囲内で質問や要約などにこたえるLLMのサービスです。いたってシンプルなサービズでいろいろと試してみました。
まず試すために入れたのは「DX白書 2023」です。経済産業省が刊行した全407ページの「分厚い」文書のPDFファイルなのです。当然文字数はプロンプトの限界値を遥かに超えています。たぶんGPT-4の限界を遥かに超えているでしょう。
そんな分厚いPDFを「ChatPDF」がみごとに取り込んで要約してみせました!!
最初は単純に「すげー」って思いましたが、しばらくしてワタクシの頭の中にあることが思いつきました。
PDFにしたら大量データ読み込めるんじゃなね?
PDFファイルという形式はどんなデータにも平等といえば平等です。WordもEXCELもPowerPointも・・・・どんなデータでもPDFにしてしまえます。
しかもWebページも「印刷する」にするとたいていのデバイスでPDFにすることができちゃいます。
さっそくNotionにあるワタクシのイベント参加データをPDF化してみようと思い立ったのでした。
思い立ったら吉日ということで、早速Notionにある昨年7月からのIT勉強会イベント参加履歴のデータを開きました。
総件数276件に及ぶデータです。
一覧が表示されたビューのページを一番下までスクロールして全データを表示してから、画面上で右クリックし「印刷」をし、ダイアグラムから項目を多く抽出できるように「横方向」印刷にして形式はPDFを指定して「保存」をクリックです。
10ページに渡るPDFファイルが出来上がりました。
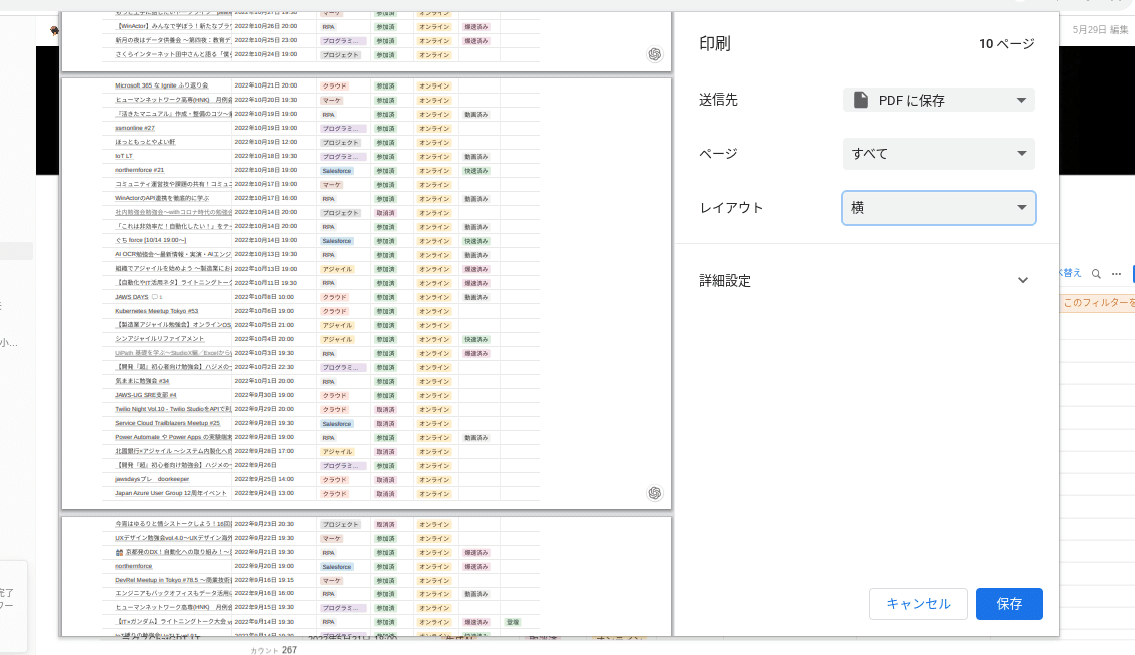
これでPDFに読み込ませたのであとはChatPDFに突っ込むだけです。
ChatPDFでデータを読み込ませられるか?
次はChatPDFの画面を開きます。
さっそく先程作ったPDFファイルを読み込ませます。
400ページのDX白書に比べれば、この程度のボリュームならあっという間です。すぐに読み込み終わりました。

さっそく軽く質問してみます。
その前にデータの説明用プロンプトを追加します
このデータはワタクシの一年間のIT勉強会の出席を記録した情報のPDFです。表には以下のような項目があります。
Name:イベント名
イベント日時:参加したイベントの日時
カテゴリ:勉強会イベントのテーマをSalesforce、クラウド、アジャイル、プログラミング、RPA、生成AI、マーケに分類しています
ステータス:実際に参加したイベントは「参加済」になっています
形式:オンラインとオフラインに分類しています
レポート:何らかのデータが有れば参加レポートをブログに公開しています
登壇:勉強会で登壇した場合は「登壇」となっています
この下に要求を付け加えます。例えば・・・・
最も多く参加しているカテゴリと最近多くなってきたカテゴリを挙げてください
これを投入してみます

回答は・・・・
PDFファイルには、参加したイベントのカテゴリがSalesforce、クラウド、アジャイル、プログラミング、RPA、生成AI、マーケに分類されています。しかし、どのカテゴリが最も多く参加しているかや最近多くなってきたかについては情報が提供されていません。
くぅぅぅぅ! データを読んでくれません

色々やってみましたがどうやらChatPDFくんは表にあるデータをデータと認識していないようです。逆にタイトルから特定の文字列を抜き出すなどは出来る感じです。

あきらめずにもう少し考えてみた
そう簡単に諦めるわけにはいかないので、色々考えてみました。ChatPDFが何を認識していないのか色々考えてみました。
そこで気がついたのはNotionの表の選択肢のところの表示・・・・「これもしかして画像として認識されてない?」

そこでPDFを改善してみることにしました。
Notionから一回CSVとして取り出した上でスプレッドシート形式に変換し、そこからPDFにするともっとChatPDFにとって認識しやすくなるのではと考えました。
というわけでまずはNotionからCSVを抜き出します。

それでまたChatPDFにやってもらいました

結果は・・・・
提供された情報には、参加したイベントのカテゴリーを集計する機能がありません。申し訳ありませんが、この質問に対する回答はできません。
もうちょっと粘ってみましたが
残念ながらChatPDFさんは集計はできないようです。

まとめ
・残念ながらChatPDFはデータ分析や集計をすることはできなかった。
それだけです。
やはりPDF文書として特化されてチューニングされているので想定外の他のことをさせるのは難しいような感じです。
そう考えるとChatGPTの守備範囲の広さってすごいんだなぁと感じました
しょぼん・・・・・
とはいえもう一つ新しいことを思いついたのでやってみたいと思います。
この記事が気に入ったらサポートをしてみませんか?