顔認証の原理

顔認識についてのUdemyの講座がとても分かりやすかったので、
アウトプット。
なお、すごく大雑把に書いているのをご了承いただきたい。
厳密に理解したい人はリンクの論文をどうぞ。
元の講座
顔認証のバイブル:Viola-Jones Algorithm
Viola-Jones Algorithmは顔を認識するアルゴリズムについてまとめた2001年に発表された論文であり、約20年前の内容にも関わらず広く活用されているアルゴリズムである。
原文
Viola-Jones Algorithmは二つの過程に分けられる。
まずはDetectionについて
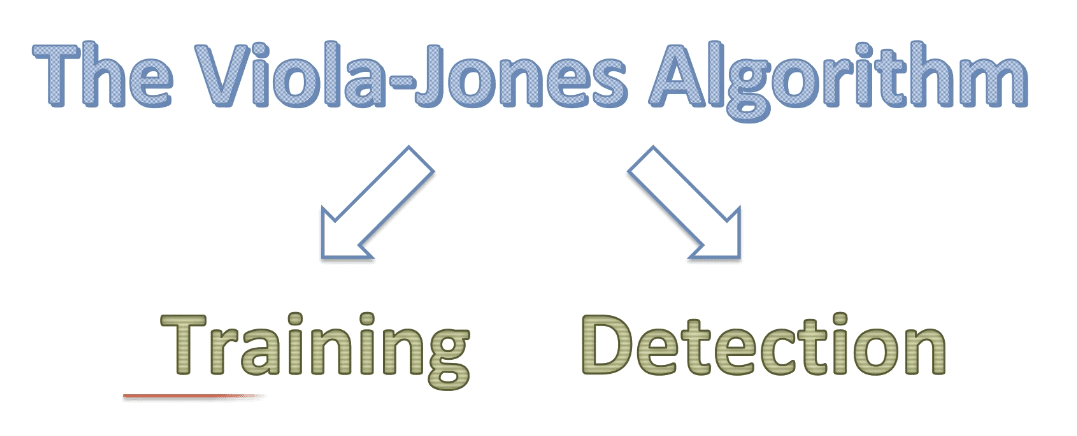
顔検知に必要な3つの重要な特徴量
顔を検出するのに必要な材料は以下の三つの特徴量が必要となってくる

口は、【白い部分】【黒い部分】【白い部分】が特徴的である

大まかに顔のパーツを三つの特徴量で記述すると、以下のようになる

では、具体的にどうやって【白い部分】と【黒い部分】を検出するのか
画像のピクセルごとの色を検出する
白:0.0
黒:1.0

すると、鼻の部分は色が白に近い領域と黒に近い領域が検出される
平均値を取ってみると、
白:0.166
黒:0.568
黒 - 白(差分):0.402

では、黒 - 白(差分)を幾つに設定すれば有意な差として認めるのか。
また、この手法だけだと大量の特徴量が一枚の画像から検出されてしまう。どれが鼻で、どれが口かもう少しフィルタリングする必要がある。
そもそも、鼻とは何か?
コンピュータに鼻とは何かを認識させるためにはどうするか。
トレーニング過程に着目する。
まずは小さい顔の画像からスタートする(24px×24px)
小さい画像の中から、三つの特徴量を検出する

どれくらいの特徴量が検出されるのか?
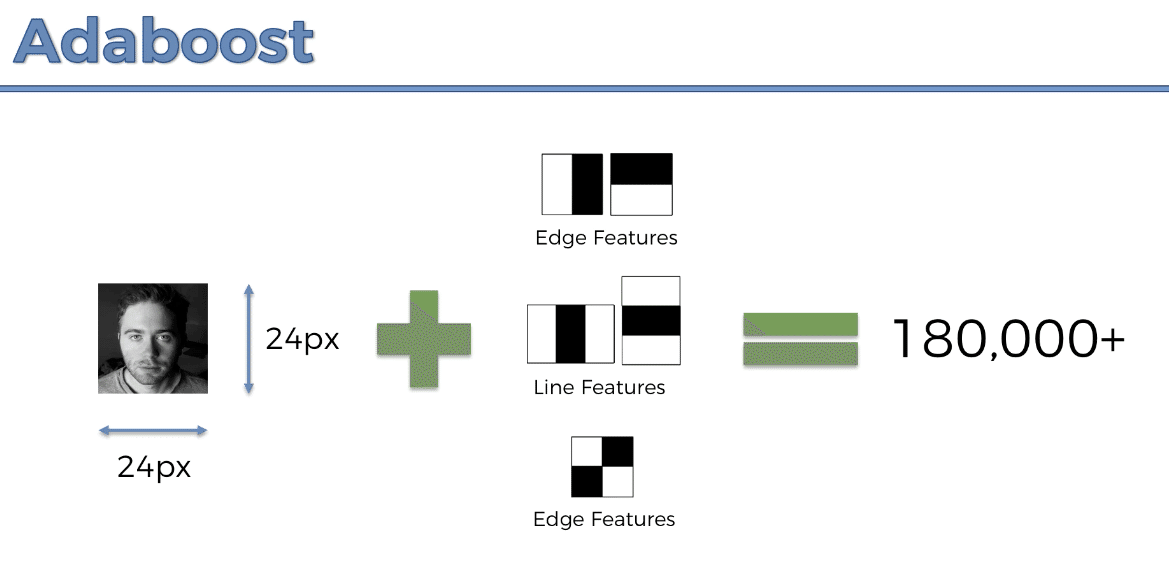
24px×24pxの小さい画像から、数十万に上る特徴量が検出される
次に、
一枚の顔写真だと偏りが生じてしまうので、
大量の顔写真から特徴量を検出する

上記の結果から、
顔にはあって、他には無い特徴量を洗い出す(重要)

参考文献:A General Framework for Object Detection
数式の理解:仮説と検証のループ
洗い出した数々の特徴量から、どうやって【顔】を特徴付けるか。
(理解が難しいパート)
上記の学習過程で得られた180,000もの特徴量について、どの特徴量があれば【顔】と認識されるのか推測する式を立てる。

具体例を
ここに、多数の画像があるとする
これを【顔】と【それ以外】に分類したい

まず、適当に数式を立ててみる。
↓
当然うまく分類されない

【エラー率】という概念を導入する
ある分類式だと、以下のようになった場合、エラー率は比較的高い。
↓
係数を考え直す
というのを延々と繰り返す。
【最強の分類式】が得られるまで頑張る。
では、どういう手順で試行していくのか(闇雲では無い)
重み付けをしていく(説明が若干難しい)
一旦、いくつかの画像に重みを付けてみる

これらの画像は、
【すごく顔(左)】及び【全然顔では無い(右)】と仮定する
仮定した上で、分類式を立てる
その上で、改めて分類してみると、以下のような結果となる
(まだ未完成)

次に、正しく分類されなかった画像をピックアップする
これらは【すごく顔(左)】及び【全然顔では無い(右)】と仮定する

分類式を立て、再度分類する
※完璧な分類式は存在しない
【エラー率】が低くなるまでトライアンドエラーを繰り返す

顔の検出仮定:Cascading(カスケード)
1枚の画像が顔か否か、知るためにはどうすればいいのか
顔と認識する上で重要度が最も高い項目群でまず、ふるい分ける。
この要素を持っていない物は、【顔では無い】と判定する

例えば、この画像では【目】はある。
したがって第一の条件はクリアしているので、次のステップへ

しかし、【口】や【鼻】が無いので【顔では無いと判断される】

結果、以下の領域が【顔】であると判定される

この記事が気に入ったらサポートをしてみませんか?