
横断検索と置換履歴

貸し本棚は編集中の小説に対して、全エピソードを対象に横断検索を行うことができます。検索結果を元に、一括で置換することができたり、指定の検索結果の元にジャンプすることができます。
横断検索

検索結果は一覧化され、リストをクリックすると指定箇所にジャンプすることができます。単なるテキスト検索なので軽量です。
結果リスト
この検索機能について特筆できるものはありませんが、結果本文の抽出はもう少し改善できそうです。現在はこうなっています。
let rc = res.data;
let ndx = 1;
const regex = new RegExp(this.keyword, "ug");
try {
this.results = [];
for (let r of rc) {
let rows = r.body.split(/\n/u);
let chars = 0;
for (let row of rows) {
let pos;
while(pos = regex.exec(row)) {
let sample = "";
if (pos?.index) {
if (pos.index > 15) {
sample = "…" + row.substr(pos.index - 15);
} else {
sample = row;
}
if (sample.length > 50) {
sample = sample.substr(0, 50) + "…";
}
this.results.push({
ndx: ndx++,
section_name: r.section_name || "(無題)",
sample: sample,
id: r.id,
pos: chars + pos.index,
});
}
}
chars += row.length + 1;
}
}
this.finded = this.keyword;
setTimeout(() => {$('[data-toggle="tooltip"]').tooltip()});
this.panel = 0;
} catch (error) {
console.error(error);
}汚いコード改行で分解した文の配列をループさせて、再度正規表現でひっかけて、15文字前〜最大50文字分を結果としてリスト化します。レンダリング時にボールド処理を行うのですが、この「15文字前」に検索文字列が混じってるとそっちをボールドしてしまう問題がありますが、結果に影響しないのでそのままにしてあります。
指定位置へジャンプ
検索結果をクリックすると、指定位置へ遷移します。これはURLに文字位置を付与して、リロード時にキャレット位置を取得してスクロールしています。
このキャレット位置の取得に以下の枯れたライブラリを使っています。
if (this.$route.query.pos) {
try {
setTimeout(() => {
let start = parseInt(this.$route.query.pos);
let end = start + parseInt(this.$route.query.len);
$("#body").get(0).setSelectionRange(start, end);
setTimeout(() => {
const body = document.getElementById("body");
const pos = textCaretPos(body, body.selectionEnd)
$("body,html").animate({scrollTop: pos.top});
$("#body").focus();
});
});
} catch (error) {
console.error(error);
}
}かならずsetSelectionRangeしてから位置取得しないと正しい位置が出てきません。Chromeなんかだとfocusするだけで動作していましたが、Firefoxなどでは動かないので、強制スクロールさせています。
置換と履歴
ここで横断検索した結果に対して、一括置換をかけることができます。例えば登場人物の名前の表記ゆれ、名前変更、設定名称変更などで必要になってきます。
一括置換したとき、もし間違ってしまうと、元に戻れないと極めて破壊的で使い物になりません。そこで、置換の履歴を取るようにしています。
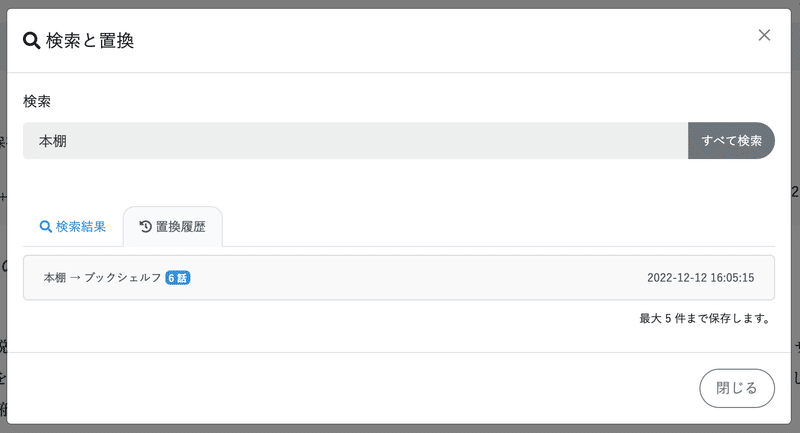
作品によっては数百話を超える大作もあるので、サーバ上に履歴を保存するのはストレージの圧迫を招きます。そこで履歴はブラウザ上に保存することにしました。あまりセキュアではありませんが、IndexedDBを使っています。IndexedDBはそのままでは使いにくいので、Dexieを採用します。
初期化
初期化時にバージョンとテーブルを指定します。置換履歴はgrepdbというデータベースにhistoriesというテーブルを作成し、cached_atとbook_idをキーにします。
this.grepdb = new Dexie("grepdb");
this.grepdb.version(1).stores({histories: "cached_at, book_id"});仕様変更時はバージョンをインクリメントさせて、upgradeメソッドで既存テーブルの変更処理を行います。
履歴リストの読み込み
履歴リストを読み込んで表示します。表示用のリアクティブなデータに一覧を読ませるだけです。
this.grepdb.histories.where("book_id").equals(this.book_id).reverse().toArray((res) => {
this.histories = res;
});編集前のエピソードリストを保存する
一括置換を実行したとき、置換対象のエピソードリストをIndexedDBに保存します。これが置換履歴となります。
this.grepdb.histories.put({
cached_at: moment().format("YYYY-MM-DD HH:mm:ss"),
book_id: this.book_id,
episodes: res.data,
keyword: this.keyword,
replace: this.replace,
}).then(res => {
this.grepdb.histories.where("book_id").equals(this.book_id).count(count => {
if (count > this.HISTORY_MAX) {
this.grepdb.histories.reverse().offset(this.HISTORY_MAX).delete().then(res => {
this.loadHistories();
});
} else {
this.loadHistories();
}
});
}).catch(err => { alert.err(err) });上記コードはreplaceAllにて、サーバに置換を送信した結果として、置換対象となったエピソードの置換前のデータを返してもらい、それを保存します。全エピソードではありません。
元に戻すとき
元に戻すときは、上記のように履歴には変更のあったエピソードしか含まれていないので、元に戻す履歴までの途中の履歴も全てマージ(糾合)する必要があります。
ほげ→もげ
ぴよ→ふが
今日→明日
上記リストが上から順に実行されていたとき、2に戻したいときは、2と3をマージしなければなりません。
// hは戻す先の履歴データ
let merge = [];
for (const history of _.reverse(this.histories)) {
if (moment(history.cached_at).isSameOrAfter(moment(h.cached_at))) {
for (const episode of history.episodes) {
if (!_.find(merge, {id: episode.id})) {
merge.push(episode);
}
}
}
}
this.grepdb.histories.where("cached_at").aboveOrEqual(h.cached_at).delete();ちょっと面倒ですが、無駄なデータを大量にやりとりするより軽量です。
既知の問題
ブラウザ保存の履歴は、当然端末が変われば無くなります。履歴を保存した端末を使い続ける必要があります。
また、この履歴は貸し本棚のいくつかの機能と衝突します。たとえば以前紹介したバージョン管理の履歴とかちあいます。それぞれの履歴が入れ子になった状態で「元に戻す」を実行しないようにヘルプに書いてあります。
通常、履歴や版管理で「元に戻す」を実行すると、そこまでの他の履歴は消滅しますが、版管理の履歴と置換履歴は別管理なので、不要な履歴が消滅しません。そのため、版管理で「1日前に戻す」を行ったあと、その日に実行した置換履歴を元に戻すと、今日の置換直前の状態に戻ります。
また貸し本棚のエピソード分解と糾合の機能は履歴を保全しません。
第1話から第5話までの「ほげ」を「もげ」に置換。
第2話を分解して、第3話から後が全部1話ずつズレる。
置換履歴を元に戻す。
こうするとエピソードデータが破損します。そのため、分解や糾合を行った場合は、置換履歴を消去することを検討しています。
IndexedDB固有の問題
これはずっと昔から言われてることですが、IndexedDBのデータはブラウザ+ドメインで区別され、ログインしているユーザが誰か、について関知しません。そのため、複数アカウントを使っている場合にデータが共有されてしまうという問題が起きます。
置換履歴はbook_idをキーにしているので、上記問題は発生しません。
IndexedDBは他にも一時保存などで使っていますが、軽量高速で扱いが簡単です。揮発性が高くてあまりセキュアでないという問題はありますが、貸し本棚のように小規模なサービスではとても便利だと思います。
アイキャッチはUnsplashのMick Hauptが撮影した写真
この記事が気に入ったらサポートをしてみませんか?