
【Python+selenium+beautifulsoup】note.comの『記事ページ』をスクレイピングする方法

前回はPython+selenium+beautifulsoupを用いたnote.comのスクレイピングの例として、ハッシュタグ検索ページのスクレイピングについて解説しました。
そして今回はより実用的なnote.comの記事ページから、様々な情報を抽出するサンプルコードをご紹介したいと思います。
note記事ページに含まれるデータを確認
スクレイピングのコードを書く前にまず、note記事ページに含まれるデータについて確認します。
主要なデータとしては以下の項目などが挙げられます。
・テキストデータ(文字数・見出しの数など)
・記事に使用されている画像のデータ
・ハッシュタグ
・記事の著者(名前・note ID)
・スキ数
・コメント数
今回はこれらの項目をカラムとして、一つの記事が一行のデータに収まる形となる様にPythonコードを組んでいきます。
サンプルコード
# note.comの記事を取得
import sys
import requests
import time
import re
import pandas as pd
from tqdm import tqdm
import datetime
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from bs4 import BeautifulSoup
columns_name = ["page_url","date","pict_cnt","text_cnt","tag","tag_cnt","comment_cnt","body_html","body_text"]
file_name = "note記事.xlsx"
# 対象URL
url="https://note.com/karupoimou/n/n85762f62e5cc"
def get_notes():
all_list=[]
# driverのセットアップ
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(30)
driver.get(url)
WebDriverWait(driver, 30).until(EC.presence_of_all_elements_located)
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "lxml")
# 投稿時刻
date = soup.find("span",class_="o-noteContentHeader__date").text
date = datetime.datetime.strptime(date, '%Y/%m/%d %H:%M')
# 画像の数
body_div = soup.find("div",class_="p-article__content")
pict_cnt = len(body_div.find_all("img"))
# 文字数
text_cnt = len(body_div.text)
# タグ
tag_divs = soup.find_all("div",class_="a-tag__label")
tag=[]
for t in tag_divs:
tag.append(t.text[8:-5])
# コメント数
comment_h2 = soup.find_all("h2",class_="o-commentArea__title")
if len(comment_h2) > 0:
comment_cnt = re.sub("\\D", "", comment_h2[0].text)
else:
comment_cnt = 0
temp=[]
temp.append(url)
temp.append(date)
temp.append(int(pict_cnt))
temp.append(int(text_cnt))
temp.append(tag)
temp.append(len(tag))
temp.append(int(comment_cnt))
temp.append(body_div)
temp.append(body_div.text)
all_list.append(temp)
driver.close()
driver.quit()
df = pd.DataFrame(all_list, columns=columns_name)
df.to_excel(file_name)
get_notes()結果:成功!

上記のコードで様々な項目を取得することができました。
以下、コードの説明を少々
コードの説明
# driverのセットアップ
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(30)
driver.get(url)ここでseleniumのwebdriverをセットアップしています。今回はChromeを使っていますが、パスを通してあるディレクトリにchromedriver.exeを置いているので、webdriver.ChromeOptions()の記載だけで済んでいます。(もしパスを通していない場合は絶対パスで.exeの場所を指定すれば大丈夫です)
投稿時刻の取得
date = soup.find("span",class_="o-noteContentHeader__date").text
date = datetime.datetime.strptime(date, '%Y/%m/%d %H:%M')
ここでは記事の投稿時刻の文字列を取得した後、それをdatetime型に変換しています。
datetime型に変換しておくと、日時の計算や集計が簡単になるのでなにかと便利です。
タグの取得
# タグ
tag_divs = soup.find_all("div",class_="a-tag__label")
tag=[]
for t in tag_divs:
tag.append(t.text[8:-5])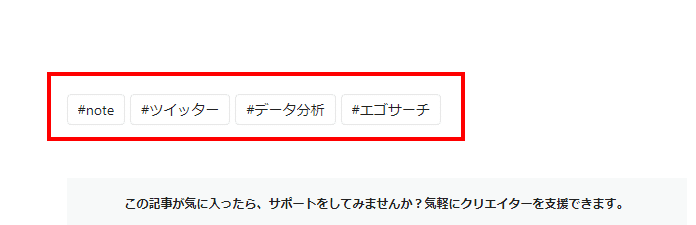
ここでは記事の下の方にある『タグ』の情報を読み取っています。
コメント数の取得
# コメント数
comment_h2 = soup.find_all("h2",class_="o-commentArea__title")
if len(comment_h2) > 0:
comment_cnt = re.sub("\\D", "", comment_h2[0].text)
else:
comment_cnt = 0note記事ではコメントが0件の場合、コメント数がそもそも表示されないので、そのまま取得しようとするとエラーが出てしまいます。
そこで「0件の場合」と「1件以上の場合」で条件分岐させ、1件以上の場合のみ文字列から数字を抽出するようにしています。
まとめ
今回はPython+selenium+beautifulsoupを用いて、note.comの『記事ページ』から様々な情報を抽出するサンプルコードをご紹介しました。
今回は1記事分の抽出を対象としましたが、for文を上手く組み合わせることで1000記事2000記事といった記事でも一括取得出来るようになります。
次回はこのコードをさらに拡張して『note.comにおけるスキ獲得数上位2000記事』の一括取得を行っていきたいと思います。
メモ代わりに♡ボタンよろしくおねがいしますm(_ _)m
よろしければサポートお願いします。サポート? サポート……、サポート!よろしくおねがいします!?