大規模言語モデルをフルスクラッチする練習 (環境構築ー前処理ー事前学習ーファインチューニングー評価まで)

はじめに
以下のオープンなプロジェクトの一環で、大規模言語モデルをフルスクラッチで作る練習をします。24年3月現在、協力者も募集中です。
リポジトリ
当該プロジェクトの標準コードが公開※されたので、それを走らせてみます。
※24/3/5時点で、まだレポジトリ内に、工事中の箇所が多々、あります。
このリポ上では、事前学習ー事後学習ー評価まで、一気通貫(?)したパイプラインが提供されています※。
※3/8追記
個々のパイプが繋がってませんでした。
きちんと繋がったパイプラインをレポジトリで構築中です。
0. 環境構築
プロジェクトの本番環境はクラウドですが、今回は手持ちのubuntuを使います。
Dockerはお手軽な一方で、スパコン上で使うと、どうやら速度が落ちるらしいとの噂を聞いたので、condaで作ります(とはいえ、pipしか使わないので、pyenvでもいけると思います)。
必要なマシン
適当なlinux: 例えばUbuntu 22.04.3 LTS
GPU: 20 GBくらいは欲しいかも?
ディスク容量: 軽く1TBくらいはあると安心?
RAM: 数十GBくらいは欲しいかも
学習データ数やモデルサイズを小さくした条件なら、もっと少なくても大丈夫かもしれません。
Githubレポジトリ
とりあえずgit
git clone https://github.com/matsuolab/ucllm_nedo_prod.git仮想環境
筆者はcondaが好きなので、condaで作ります。train周りを見る限り、pythonのversionは3.11.2が良さそうです (pipしか使わないので、pyenvでいけると思います)。
(3.11.2だと、Solving environment: unsuccessful attempt using repodata from current_repodata.json, retrying with next repodata source.でダメそうでした)
conda create -n scr python=3.11 -y
conda activate scr
python -v # version確認。 3.11.8でした。1. データの取得と前処理
READMEはこちらです。
aptのinstall
#まずはディレクトリ移動
cd ucllm_nedo_prod/preprocessing/
#大きなファイルをgitするapp
sudo apt-get install git-lfspip
データセットのダウンロード時に、module not found errorが出たので、入れておきます。(蛇足: condaで環境を作って基本的にpipで入れる邪道なユーザーです)
pip install mwxml==0.3.3
pip install requests==2.31.0データセットのダウンロード
mc4-jaの一部を落とします。
python -m preprocessing.download_dataset --dataset=c4 --split=train --output_base=output --index_from=0 --index_to=10全ての場合は以下のコードのようです(未確認。数百GBはあるので注意)
./bin/download_mc4_ja※補足: index_toは、1~1024までのようです。1 indexあたり、0.6 GB程度でした。
ダウンロードすると、
ucllm_nedo_prod/preprocessing/output/datasets/allenai/c4/
フォルダにgz圧縮されたjsonlファイルが格納されます。
wikipediaも落とせます※。
python -m preprocessing.download_dataset --dataset=wikipedia --split=20240301※ 実行すると、数分ほどした後、EOFError: Compressed file ended before the end-of-stream marker was reached が返ってきました。
が、ucllm_nedo_prod/preprocessing/output/datasets/wikipedia/20240301/ja/フォルダ内に、それなりの量のjsonlが生成されたので、一旦、これで良しとします。
2-1. 前処理
前処理とは?
mc4-jaに含まれるテキストデータは恐ろしく汚いので、クリーニングを行います。
(参考サイト)
日本語 LLM 構築におけるコーパスクリーニングの網羅的評価 (新里ら 2024)
テキストフィルタリングとは?
テキストフィルタリングは、LINEが開発したhojicharというライブラリによって行われます。hojicharが提供するfilterの種類については、codeを見るのが手っ取り早いです。
公序良俗に反するNGワード、webページのヘッダー、フッター類の削除、emailと電話番号のマスキングといった基本機能が搭載されています。
あくまで基本処理を行うライブラリという印象で、もっときれいにした方が良いと個人的には考えています(例えばこちらやこちら)。
フィルタリングの実施
pipでhojicharなどの関連ライブラリを入れます。
fugashiは、Mecabという形態素解析のためのライブラリです。
pip install hojichar==0.9.0
pip install mecab-python3==1.0.8
pip install 'fugashi[unidic]' # v1.3.0
python -m unidic download #辞書のダウンロード※fugashiのところでちょっとつまりました(pip install fugashiでは不可でした)。
次のコードで実行できます。
#wikipediaをクリーニングする場合
python -m preprocessing.filtering --input_dir=output/datasets/wikipedia/20240301/ja --output_dir=outputTODO: preprocessing.filteringは、指定フォルダ内のjsonlファイルを探索し、フィルタリングするコードのようです。
上記のscriptで落としたmc4はgz圧縮されてるので、解凍しておく or gzも読み込めるscriptに変更する必要がありそうです。
実行にはそれなりの時間がかかります。

TODO: 2 processくらいが並列で動いているようですが、もっと並列化はできそうです。
scriptを実行するとpreprocessing/output/20240305070021 的なフォルダが生成されます(数値は実行時の時間)。
その中に、更に0,1,..,Nのフォルダが生成され、jsonlが格納されます。

TODO: ノイズ, Good判定された記事の違いが筆者にはわかりませんでした。要するに、フィルタリングの精度に改善の余地があるということです。
ファイルの集約
生成されたwikipediaのjsonlファイル群を、一つのフォルダ(output/filtered)内に集約します※。
(※ dedupに必要だったので、筆者があらたんい追加したコードです)
コード中盤の20240305070021 は、自分のフォルダを指定すること。
#shファイルの生成
cat << 'EOF' > aggregate_files.sh
#!/bin/bash
# 集約先ディレクトリの確認と作成
mkdir -p output/filtered
# カウンターの初期化
counter=1
# 対象ファイルを検索し、ループ処理
find output/20240305070021 -type f -name 'result.filtering.jsonl' | while read filename; do
# ファイルを移動して名前を変更
mv "$filename" "output/filtered/$counter.jsonl"
# カウンターをインクリメント
((counter++))
done
EOF
#権限付与
chmod +x aggregate_files.sh
#実行
./aggregate_files.shDedup
テキスト間の重複を削除する処理です。こちらも、hojicharライブラリによって行われます。
以下のコード実行を実行すると、output/filtered内のjsonlファイルよ読み込み、重複チェックをしていきます。
python -m preprocessing.dedup --input_dir=output/filtered --output_dir=output重複チェックも、わりと時間がかかります。
フィルタリングと同様、rejectedに重複っぽいテキスト、resultにフィルタされたテキストが生成されます。

所感
こちらの前処理codeは、わりと時間がかかりそう&フルに並列化されてないので、もろもろの改善の余地がありそうです。
(前処理専用のサーバーで処理する、などの選択肢も有りえます)
2-2. 事前学習のための環境構築
こちらが大規模言語モデルの構築のメインパートです。
…と言いたいところですが、引き続きの環境構築が必要です。
multi_node/GPUの違いで、処理codeが分かれています。今回は一番シンプルな、1 node, 1 GPUを想定して作業を進めます。
環境構築
GitHubのREADMEはABCIサーバー(A100, 40GB)想定ですが、今回はローカルのubuntuを使っています。なので、少し操作が異なります。
今回、使用するマシンはRTX6000Adaです。

基本パッケージのインストール
パッケージを入れていきます。
cd ../train/ #train dirに移動
#torch類のinstall
pip install torch==2.0.1+cu118 torchaudio==2.0.2+cu118 torchvision==0.15.2+cu118 --find-links https://download.pytorch.org/whl/torch_stable.html
#requirements: accelerate, transformers, sentencepieceのような言語モデル系ライブラリ
pip install -r requirements.txt
#deepspeed
pip install deepspeed-kernelsDeepSpeedのinstall
次に、deepspeedをbuildしながら入れます。deepspeedは、機械学習の訓練と推論を早くしてくれるライブラリです。
自分の環境では、次のaptが必要でした。
sudo apt-get install libaio-dev -ybuildが上手くいくよう、祈りながら以下のコマンドを実行します※。
buildにも時間がかかります(15分くらい?)。
DS_BUILD_OPS=1 DS_BUILD_EVOFORMER_ATTN=0 DS_BUILD_SPARSE_ATTN=0 pip install deepspeed==0.12.4
※ cuda toolkitのバージョンにシビアなようです。例えば11.5や12.3では、エラーが出ました。バージョンはnvcc- Vで確認できます。もしバージョンが異なるなら、こちらのサイトなどから、11.8を入れましょう。
(複数のcuda toolkitを使う方法はこちら)
#installの例 (driverは元のまま、cuda toolkitのみ別途入れるようにしました)
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo bash cuda_11.8.0_520.61.05_linux.run
#必要に応じ、パスを通しておく
export PATH="/usr/local/cuda-11.8/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH"Megatron-DeepSpeedのインストール
Megatron-DeepSpeedは、大規模なトランスフォーマーモデルの訓練を高速化し、効率化するために設計されたフレームワークです。
以下のコマンドで入れていきます
#Megatron-DeepSpeedのレポジトリをクローン。
git clone https://github.com/hotsuyuki/Megatron-DeepSpeed
# mainブランチではエラーが起きる場合があるため、指定のタグにチェックアウト。
cd Megatron-DeepSpeed/
git fetch origin && git checkout refs/tags/ucllm_nedo_dev_v20240205.1.0
#install
python setup.py installapexのインストール
NVIDIAのApexは、PyTorchでの深層学習モデルの訓練を高速化および最適化するためのツールです。
以下のコマンドでインストールします。
こちらもインストールに時間がかかります(5-10 min)。
#train dirに戻る
cd ../
#clone
git clone https://github.com/NVIDIA/apex
cd apex
# mainブランチではエラーが起きる場合があるため、指定のタグにチェックアウト。
git fetch origin && git checkout refs/tags/23.08
#install
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
# apex_C.cpython-311-x86_64-linux-gnu.soが作成されていることを確認。
find build/lib.linux-x86_64-cpython-311/ -name apex_C.cpython-311-x86_64-linux-gnu.soflash-attention 2, llm-jp-sftのインストール
flash-attention 2はattentionを高速化するモジュール、 llm-jp-sftはSupervised Fine-Tuningのためのモジュールです。
#flash atten
cd ../
pip uninstall ninja -y && pip install ninja==1.11.1
pip install flash-attn==2.5.0 --no-build-isolation
#sft
# mainブランチではエラーが起きる場合があるため、指定のタグにチェックアウト。
git clone https://github.com/hotsuyuki/llm-jp-sft
cd llm-jp-sft
git fetch origin
git checkout refs/tags/ucllm_nedo_dev_v20240208.1.0
3. トークナイザーの学習
textをtoken化していきます。
デフォルトでは、先程までに頑張って前処理したテキストではなく、適当なtxtが処理される設定なので注意。
※train_sentencepiece_tokenizerを修正します。
sys.path.append(os.path.join(os.environ["HOME"], "ucllm_nedo_prod
/train/scripts/common/"))などのようにして、special_token_listへのパスを通すか、
パラメータを直接定義してしまいます。
#コメントアウト
#from special_token_list import BOS_TOKEN, EOS_TOKEN, PAD_TOKEN, CLS_TOKEN, SEP_TOKEN, EOD_TOKEN, MASK_TOKEN, NEWLINE_TOKEN
#追加
UNK_TOKEN = "<unk>"
BOS_TOKEN = "<s>"
EOS_TOKEN = "</s>"
PAD_TOKEN = "<pad>"
CLS_TOKEN = "<CLS>"
SEP_TOKEN = "<SEP>"
EOD_TOKEN = "<EOD>"
MASK_TOKEN = "<MASK>"
NEWLINE_TOKEN = "\n"トークナイズします。textが少ないので、一瞬で終わります。
#ディレクトリ移動
cd ../scripts/step1_train_tokenizer/
#トークナイズ。 vocab sizeは重要なハイパラです。
python ./train_sentencepiece_tokenizer.py \
--input ./dataset/botchan.txt \
--model_prefix botchan \
--vocab_size 2000
#ファイルの移動
mkdir -p botchan/ && mv ./botchan.model ./botchan.vocab --target-directory botchan/
この作業が終わると、train/scripts/step1_train_tokenizer/botchanフォルダ内に、botchan.model & vocabが生成されます。modelはバイナリのモデルファイル、vocabはテキストエディタで閲覧可能なvocab集です。
4. 事前学習
やっとメインです。wandbのアカウントを作成して登録しておきましょう(こちらなどを参照。アクセストークンはこちらから確認)。
デフォルトで学習されるコードは、arxivのtextなので注意。
cd ../step2_pretrain_model/
#wandb
wandb login (ここにwandbのアクセストークンを貼り付ける)必要に応じ、dataset-arxiv_tokenizer-sentencepiece_model-gpt_0.125B/zero-0_dp-1_pp-1_tp-1_flashattn2-on.shの設定を少し変えます。
・shファイル内の上の方のucllm_nedo_dev_train_dirが、デフォルトでは$HOMEから参照される設定なので、必要に応じて絶対パスを指定します。

・もしGPUが二枚以上刺さっている環境の場合は、batch_size=1にしておきます。

学習コマンドを実行します。
bash ./abci_node-1_gpu-1/dataset-arxiv_tokenizer-sentencepiece_model-gpt_0.125B/zero-0_dp-1_pp-1_tp-1_flashattn2-on.sh \
--input_tokenizer_file ../step1_train_tokenizer/botchan/botchan.model \
--output_model_dir ./ \
--save_interval 100010分ほど待つと、学習が開始します。
(テキストのtokenization(?)に時間がかかるようです)
上手くいくと、GPUが動き始めます。

今後、何がどうなっているのか、調べようと思います。
兎にも角にも、計算が始まった感じなので、とりあえず放置します。
学習が進むにつれ、モデルのcheckpointが自動生成されます。
例: checkpoint/gpt_0.125B_tok300B_lr6.0e-4_min1.0e-6_w3000M_d300B_cosine_gbs256_mbs1_g_pp1_seed1234_rebase/global_step10000
(油断していると、ディスク容量を圧迫するので注意)
TODO: Wandbと連携できていない感じでした(こちらのサイトを参考に実装できそう)。
TODO: 途中から学習、みたいなコードも把握したほうが良さそうです。
学習結果(中断)
一晩ほど放置した結果のログは以下の通り。
iteration 10010/ 1144409 | consumed samples: 2562560 | consumed tokens: 5248122880 | elapsed time per iteration (ms): 7840.3 | learning rate: 5.999E-04 | global batch size: 256 | lm loss: 1.072230E+00 | loss scale: 1048576.0 | grad norm: 0.108 | num zeros: 0.0 | actual seqlen: 2048 | number of skipped iterations: 0 | number of nan iterations: 0 | samples per second: 32.652 | tokens per gpu per second (tgs): 33435.277 | TFLOPs: 24.85 |
iterationはまだまだですが、5B token, 25 TFLOPsほど学習できたようです。
tokenizerもかなりいい加減に作っており、学習を完了させる意味は特に無いので、ここらで学習をストップさせました。
Huggingface Transformersへの変換
学習したモデルを、HuggingFaceのTransformersライブラリで使える形式に変換します。
input_tokenizer_fileは、tokenizerのモデルパス、input_model_dirはcheckpointのディレクトリ、output_tokenizer_and_model_dir は出力ディレクトリを指定します。
コード修正
tokenizerの時と同様、convert_tokenizer_from_sentencepiece_to_huggingface_transformers.pyを修正します。
すなわち、special_token_listへのパスがきちんと通っていないので、環境に応じて正しいpathを追加したり、UNK_TOKEN, …類をファイル内で定義してしまいます。

convert_tokenizer_and_pretrained_model_to_huggingface_transformers.shも、必要に応じてディレクトリを修正します。

megatronほか、変換時に用いるライブラリを入れます。
pip install Megatron==0.5.1
pip install matplotlib==3.8.3
pip install ipython==8.22.2
pip install megatron-core==0.5.0変換を実施します。
#ディレクトリ移動
cd ../step3_upload_pretrained_model/
#変換スクリプトの実行
bash ./convert_tokenizer_and_pretrained_model_to_huggingface_transformers.sh \
--input_tokenizer_file ../step1_train_tokenizer/botchan/botchan.model \
--input_model_dir ../step2_pretrain_model/checkpoint/gpt_0.125B_tok300B_lr6.0e-4_min1.0e-6_w3000M_d300B_cosine_gbs256_mbs1_g_pp1_seed1234_rebase/global_step10000 \
--output_tokenizer_and_model_dir gpt_0.125B_global_step10000/
うまくいくと、gpt_0.125B_global_step10000フォルダなどが生成されます。
モデルのアップロード
HuggingFaceにモデルをアップロードします。
はじめに、アクセス用のAPIを取得します。

ログインしておきます。
huggingface-cli login新規モデルをhuggingface上に登録しておきます。
今回のモデル名は、20240306test_gptとしました。

アップロードします。
input_tokenizer_and_model_dirには、先程のoutput dirを設定します。
output_model_name は、先程のモデル名です。
python ./upload_tokenizer_and_pretrained_model_to_huggingface_hub.py \
--input_tokenizer_and_model_dir gpt_0.125B_global_step10000/ \
--output_model_name kanhatakeyama/20240306test_gpt\
--test_prompt_text "Once upon a time,"うまくいくと、モデルのアップロードが始まります。

5.ファインチューニング
ファインチューニングのスクリプトは色々なところに転がってますが、レポジトリの通りにやってみます。
コード修正
ucllm_nedo_prod/train/scripts/step4_finetune_model/abci_node-1_gpu-1/dataset-openassistant_tokenizer-sentencepiece_model-gpt_0.125B/launcher-none_zero-none.sh のパスを必要に応じ、修正します。
データセットのダウンロード(不要?)
英語のinstruction datasetをダウンロードします。
(datasetをダウンロードする自動処理が、launcher-none_zero-none.sh内に入っていました)
cd ../../llm-jp-sft/dataset/
wget https://huggingface.co/datasets/timdettmers/openassistant-guanaco/resolve/main/openassistant_best_replies_train.jsonlファインチューニング
ファインチューニングを実行します。
cd ../../scripts/step4_finetune_model/
bash ./abci_node-1_gpu-1/dataset-openassistant_tokenizer-sentencepiece_model-gpt_0.125B/launcher-none_zero-none.sh \
--input_model_name_or_path kanhatakeyama/20240306test_gpt \
--output_tokenizer_and_model_dir 20240306test_gpt_openassistant5 minほどかかるようです。

モデルのアップロード
事前学習モデルと同じように行います。
cd ../step5_upload_finetuned_model
python ./upload_tokenizer_and_finetuned_model_to_huggingface_hub.py \
--input_tokenizer_and_model_dir ../step4_finetune_model/20240306test_gpt_openassistant/ \
--output_model_name 20240306test_gpt_openassistant \
--test_prompt_text "Once upon a time,"6.評価
モデルの評価を行います。
wandbの設定
今回は練習なので、自分の独自のwandb projectを作ります。

環境構築
事前学習用の仮想環境でpipすると、conflict errorが出ました。
なので、仮想環境を新しく作り直します。
仮想環境を新たに作り、eval用のcodeをclone, pipします。
cd ../../../eval/
git clone https://github.com/matsuolab/llm-leaderboard.git
conda create -n llmeval python=3.11 -y
conda activate llmeval
pip3 install -r llm-leaderboard/requirements.txt環境変数も設定します。評価にはopenaiのapiも使います。
export LANG=ja_JP.UTF-8
# https://wandb.ai/settings#api
export WANDB_API_KEY=<your WANDB_API_KEY>
#https://platform.openai.com/api-keys
export OPENAI_API_KEY=<your OPENAI_API_KEY>yamlの設定
最後に、llm-leaderboard/configs/config.yamlの設定を変更します。主な変更点は以下のとおりです。
wandb-entity: 先程設定したwandbのentity(≒ユーザー名, 例: kanhatakeyamas)
wandb-project: 先程設定したwandbのプロジェクト名 (例: llmeval)
model-pretrained_model_name_or_path
huggingface上の自分のモデル名(例: kanhatakeyama/20240306test_gpt)
tokenizer-pretrained_model_name_or_path
huggingface上の自分のモデル名(例: kanhatakeyama/20240306test_gpt)
metainfo-basemodel_name:
huggingface上の自分のモデル名(例: kanhatakeyama/20240306test_gpt)
必要に応じ、max_seq_length (モデルの扱えるcontext length)、max_new_token(最大の出力token数)を修正します。

実行
cd llm-leaderboard/
python scripts/run_eval.pyうまく実行されると、評価が始まります。はじめはファイルダウンロードなどが行われます。※
※scriptsに移動して、python run_eval.pyとすると、うまく設定のyamlを読め込めないので注意。


スコアは圧倒的に低いです。

注意: 評価にGPT-4のAPIを何回も呼び出します。
(エラー対応メモ)
いくつか、codeのミスがあるので、修正が必要です(24/3/23時点)。
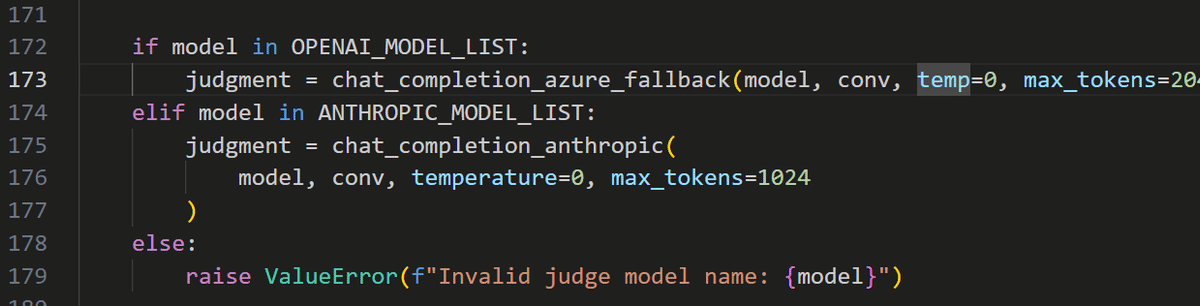
(これはcommpn.py内のバグ; chat_completion_axure_feedbackの引数がtempとなっていた)
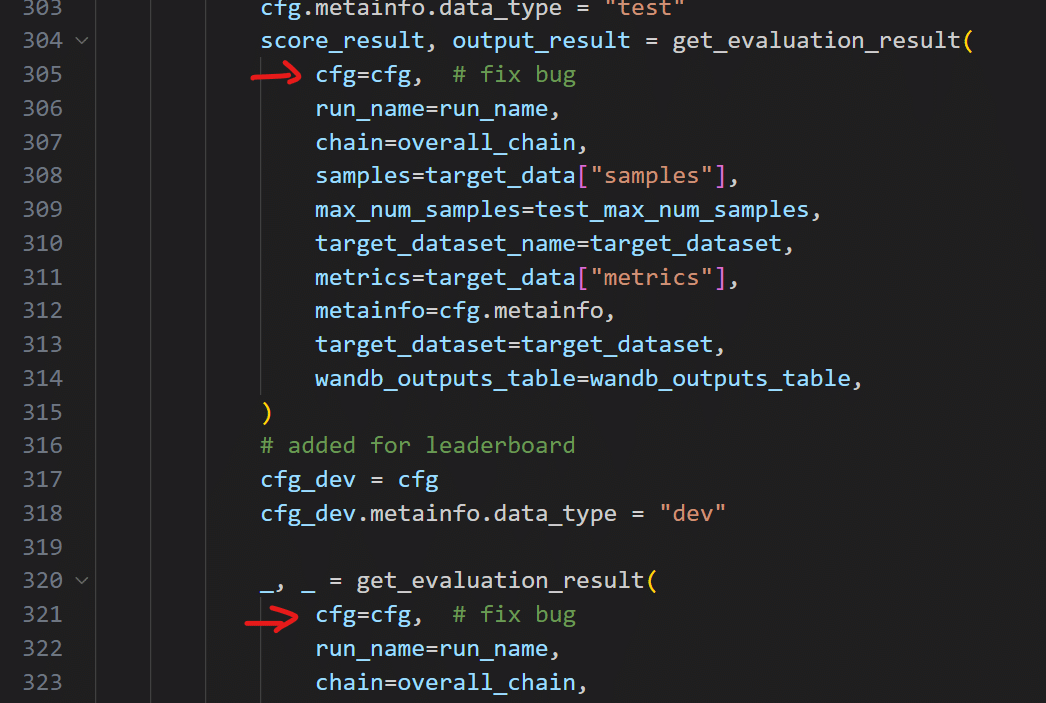
cfgが引数として渡されていないので、エラーが出る
さいごに
今回は手元のマシンでやりましたが、本番はクラウド環境で、まさかの10-50Bモデルの訓練です。
オープンなプロジェクトなので、自分でもやってみたくなった方は、諸々のことに参加できます。以下のページを参照ください。
(筆者のグループでは、データセット作成などにも力を入れています)