大規模言語モデルが自分で作った文章を「自習」をさせながら、分子物性の予測精度を上げる試行

24/1/16追記
凡ミスで、コード実装に一部、ミスがありました。
(llama2が生成したデータではなく、GPT4が生成したデータを学習していました)。
修正済みです。計算結果にsignificantな変化はありません。
こちらの研究の続きです。
はじめに
既存のケモ・マテリアルズインフォマティクスは基本的に言語モデルを使いません。
そのような特化型モデルは、予測過程が人間に分かりづらかったり、科学的にはありえないロジックで推論してしまうデメリットが生じえます。

そこで、大規模言語モデルに、「理由」も生成・学習させることによって、
科学的な思考をさせる研究を進めています。
これまでの課題
分子構造ー融点データベースをもとに、「なぜその分子が特定の融点を示すのか?」をGPT-4に考察させることで、「説明」を付与するデータセットを生成しました。

そのような「構造ー物性ー理由」データを2.5k件ほど学習させることで、大規模言語モデルの予測性能は上がりました。
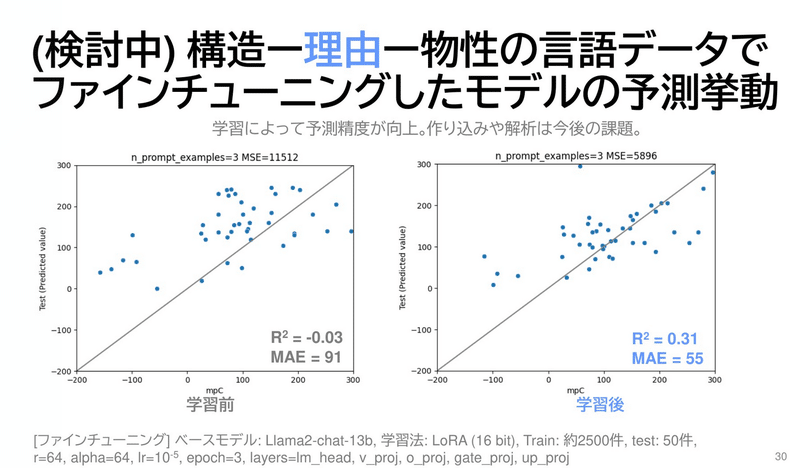
前回の取り組み: 強化学習
訓練データでファインチューニングした後、同データで再度、強化学習するというスクリプトを組みました。
いわば、
教科書を読む → 教科書の問題を自分で解いてみる
というスキームです。
ただ、予測精度は上がりませんでした。モデルがそこまで賢くはないので、原因(予測プロセス)と結果(報酬)の関係を、うまく結び付けられていない印象でした。
なぜ、褒められた/叱られたのかよく分からないのだと思います。
今回の試行: ファインチューニング用データの追加計算
強化学習とやや近いのですが、
1)ファインチューニング済みモデルを使い、
2)訓練データから問題 → 理由+予測 の推定をランダムに行い
3)予測精度が良かったデータ(予測誤差<20)を抽出し、それらを加えてoriginalモデルをファインチューニングする
とする戦略※を取ります。
人間で例えると、、
教科書を読む(はじめのファインチューニング)
教科書の問題を自分で解いて、解法ノートを作る
教科書とノートを学習する
感じです。
※この手法を使うと、一つの問題に対して、複数の解法を学習することになります。化学は数学と違い、色々な解釈が可能な現象が多いので、あまり問題は生じないと考えています。
利点は、
強化学習と違い、明示的にモデルを訓練できる
上手くいった結果だけを丁寧に学習させられる
強化学習における、報酬関数→モデルの重み更新の流れが、筆者にはblack boxだった
予測データを点検、再利用しやすい
並列で計算を回せる
です。3つ目の利点が個人的にはGoodで、A100 x2を使い、7b, 13bモデルからデータ生成しました。 数日で2.5k程度のデータが集まりました。
結果
コードはこちら。
※前回までと異なり、プロンプトチューニング無しで予測しました(プロンプトに予測が引っ張られるため)。
llama自身が作り出したデータを学習した条件で、ほんの僅かに精度が変化しました(7bはわずかに悪化, 13bはわずかに改善)。
ただ、統計的には誤差レベルといえる変化かもしれません。
7bモデルーGPT4の理由データ で学習 (前回までの手法)
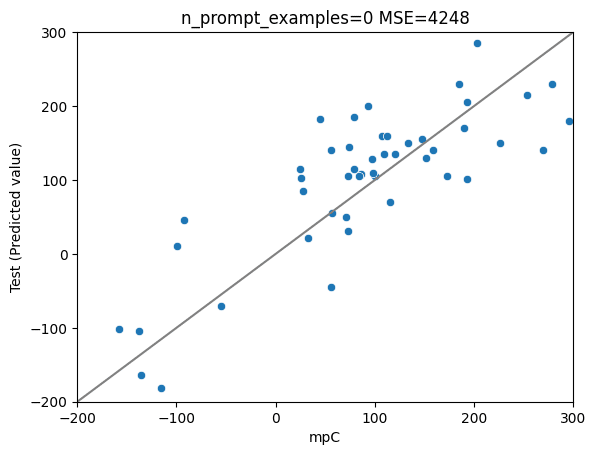
MSE: 4248
MAE: 53
R2: 0.64
7bモデルーGPT4の理由+llama2の理由&予測データ で学習(今回)
1/16: 正しいデータに差し替えました。
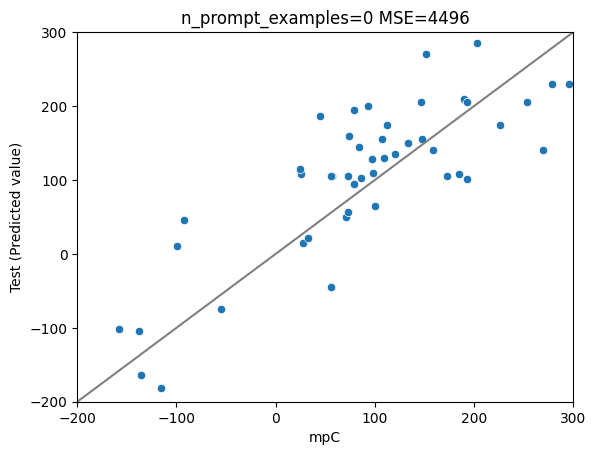
MSE: 4496
MAE: 55
R2: 0.62
7bモデルーGPT4の理由データ で学習 (前回までの手法)
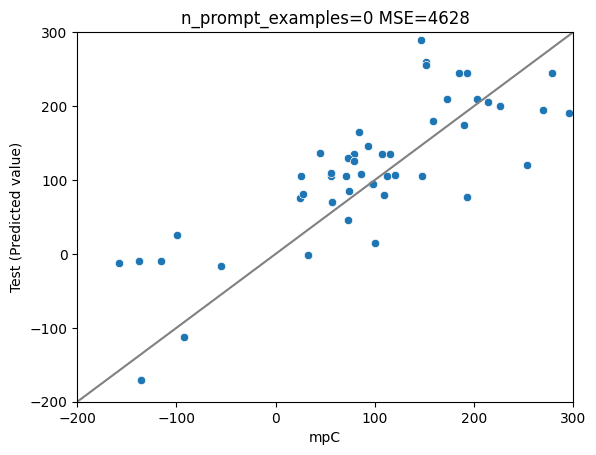
MSE: 4628
MAE: 55
R2: 0.60
13bモデルーGPT4の理由+llama2の理由&予測データ で学習(今回)
1/16: 正しいデータに差し替えました。
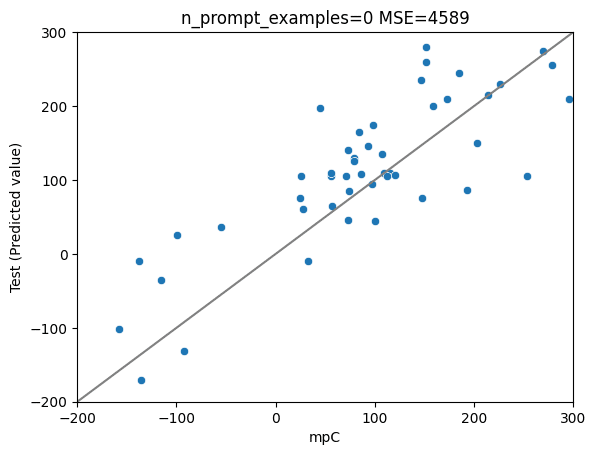
MSE: 4589
MAE: 55
R2: 0.61
まとめ
GPT4が生成した理由データに加え、Llama自身が作り出した理由+予測データで、モデルをファインチューニングしました。
残念ながら、顕著な予測精度の改善は得られませんでした。
Llama2自体の推論性能(例: 足し算を間違える)や学習データの精度(GPT-4レベルでも考察がいい加減?)が、精度のボトルネックになっている気がします。
余裕があれば、次はMOEなんかを試したいと思います。
この記事が気に入ったらサポートをしてみませんか?