pdfからtextを抜き出す試行錯誤のメモ

(文章はAIで校正しました)
はじめに
テキストマイニングでは、PDFの文章からテキストを抽出するタスクが重要となります。これは、PDFの文章ではしっかりとした日本語が多く使われているためです。しかし、PDFの文章は二段組のレイアウトや適当な場所に図表が挿入されているなど、テキストの抽出が難しい場合があります。本記事は、その試行錯誤のメモとなります。
論文
以下のCC 4.0の論文を解析してみましょう。
これは二段構えの構成を持っています。この二段構えを正確に検出し、テキストを理解することが望ましいです。

Unstructuredを使う
PythonのライブラリであるUnstructuredを試してみましょう。
参考記事
導入は非常に簡単です。
pip install 'unstructured[pdf]'
実装も簡単です。
解析コード:
from unstructured.partition.pdf import partition_pdf
pdf_elements = partition_pdf("pdf/7_71_5.pdf")
表示コード:
for structure in pdf_elements:
print(structure)
結果:
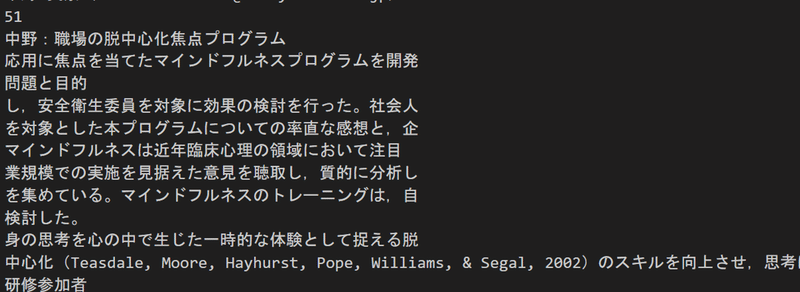
残念ながら、2段組のカラムを正確に検出することはできませんでした。
Grobidを使う
Grobidは、peS2oというオープンアクセス論文のコーパス構築に使用されたOSSです。
デモサーバーが用意されているので、簡単に利用できます。
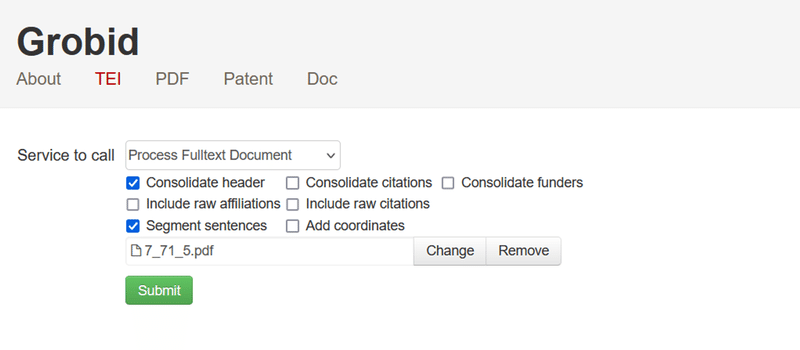
上記のように設定します。
結果

「問題と目的」というセクションすら、見つかりませんでした。
(注: 今回はダメダメでしたが、わりとGrobidを使ったプロジェクトは多いようです。設定を細かく変えれば、うまくいくのかもしれません。)
PyMuPDF
PyMuPDFはPDFを解析してテキストなどを抽出するライブラリです。
インストールは以下のコマンドで簡単に行えます。
pip install PyMuPDF
以下が実行コードです。
import fitz
doc = fitz.open("pdf/7_71_5.pdf") # ドキュメントを開く
out = open("output.txt", "wb") # テキスト出力を作成する
for page in doc: # ドキュメントのページを反復処理する
text = page.get_text().encode("utf8") # プレーンテキストを取得する(UTF-8形式)
out.write(text) # ページのテキストを書き込む
out.write(bytes((12,))) # ページ区切り(フォームフィード0x0C)を書き込む
out.close()
結果はoutput.txtに保存されます。

これは素晴らしいですね!!
手動操作
古典的なテクニックとして、PDFビューアーを開き、全選択し、コピーペーストします。

結果
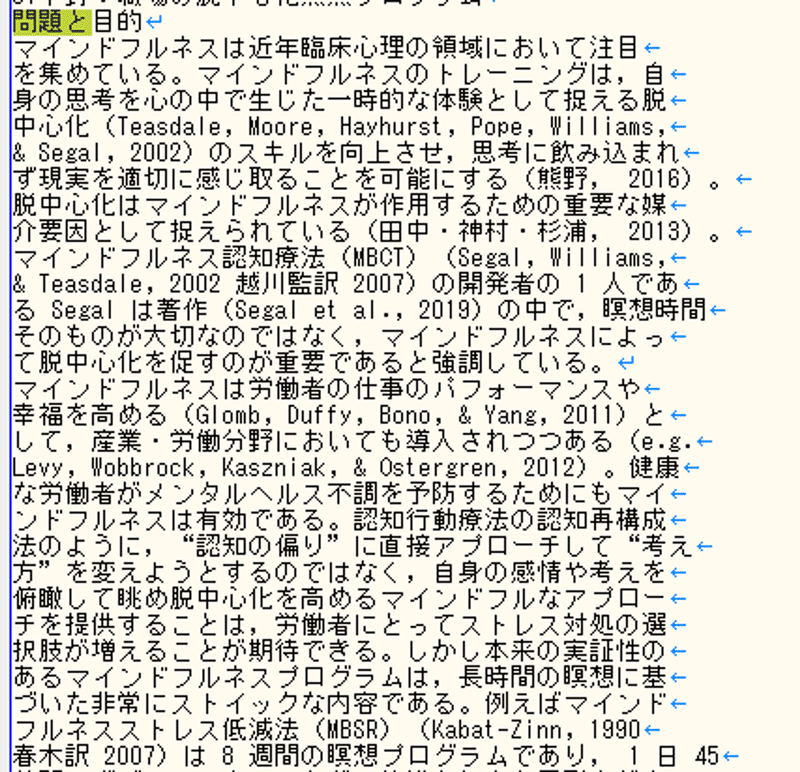
適切に段落に分けて抽出できました。
PDF Extract API (追記)
(コメントで教えてもらいました)
商用であれば、Adobeのサービスも良さそうです。
まとめ
無料で、かつ高速にテキストをPDFから適切に抽出する方法を探しました。試した結果、PyMuPDFが最も優れた抽出性能を持つ印象でした。
ただし、不適切な場所で改行が入るため、文章の区切りを検出するパーサーなどが必要と思われます。
参考
また、ページのヘッダーやフッター、図表の挿入箇所などで文章がおかしくなる可能性がありますので、修正が必要そうです。
この記事が気に入ったらサポートをしてみませんか?